Over the last week I have been training a deep learning NN (VGG style). Overall the results look good, but the discontinuities between training sessions worry me. Here is the Validation loss graph: 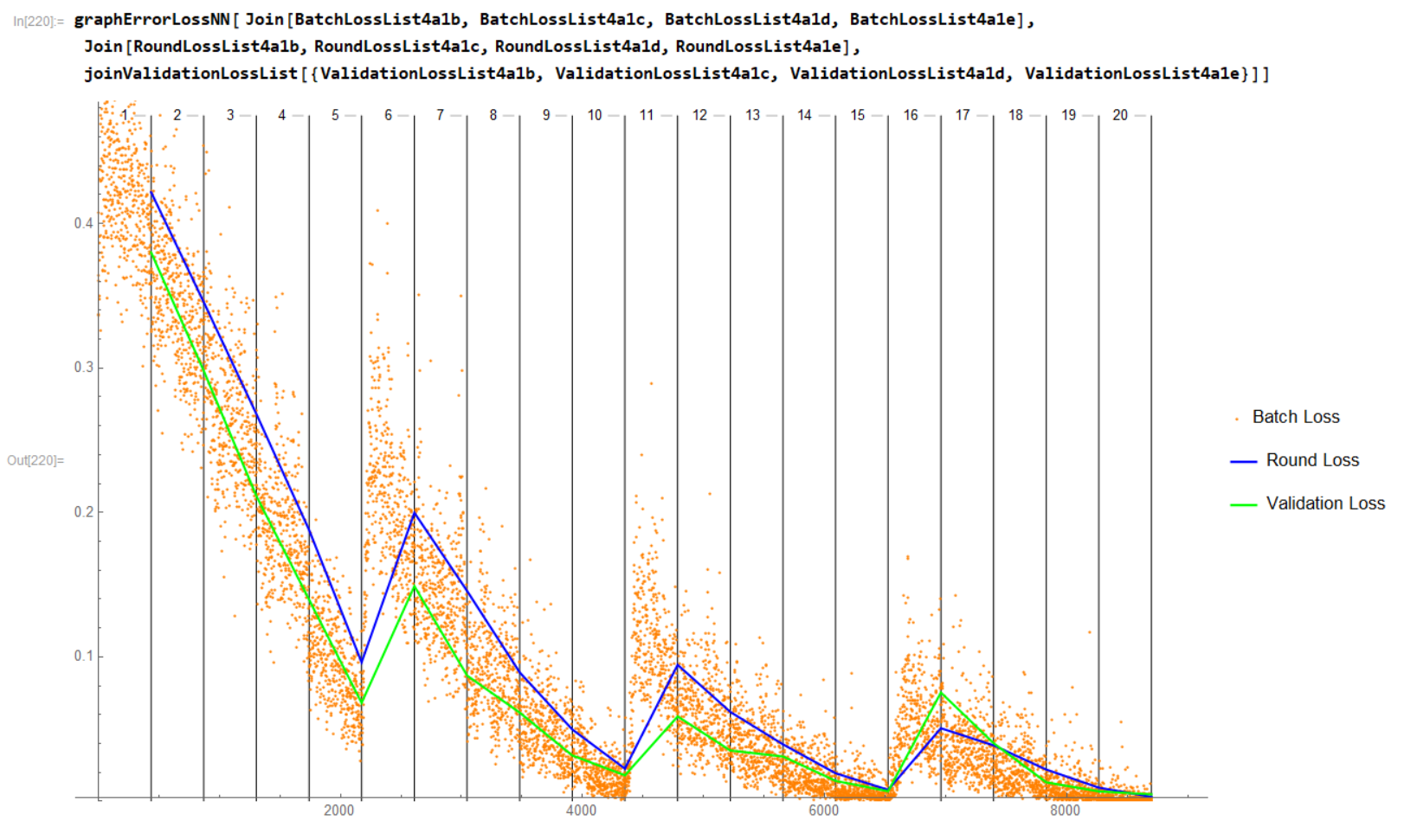
Each training session lasts 5 epochs, then when finished results are examined and the next is started if necessary:
- Training Session #1: epochs 1 - 5
- Training Session #2: epochs 6 - 10
- Training Session #3: epochs 11 - 15
- Training Session #4: epochs 16 - 20
Each of these sessions are just started using the previous with the following command:
{trainCNN4a1e, LossPlot4a1e, weightPlot4a1e, gradPlot4a1e, TrainTime4a1e, MeanBatchesPerSec4a1e, MeanInputsPerSecond4a1e, BatchLossList4a1e, RoundLossList4a1e, ValidationLossList4a1e} = NetTrain[trainCNN4a1d, TrainSet, {"TrainedNet", "LossEvolutionPlot", "RMSWeightEvolutionPlot", "RMSGradientEvolutionPlot", "TotalTrainingTime", "MeanBatchesPerSecond", "MeanInputsPerSecond", "BatchLossList", "RoundLossList", "ValidationLossList"}, ValidationSet -> Scaled[0.2], Method -> {"SGD", "Momentum" -> 0.95}, TrainingProgressReporting -> "Print", MaxTrainingRounds -> 5, BatchSize -> 256];
From one session to the next the only thing that changes is the previous trained model (this case: trainCNN4a1d) is used as the starting point for the training. In all 4 training sessions shown above this is held true, the last trained NN model is used in the next.
If I ran all these Epochs as one Training session (instead of 4) these discontinuities would NOT be present. Why are they present for this case when I do incremental training?


