CUDALink is the recommended interface in the Wolfram Language for computing on CUDA-enabled graphical processing units (GPUs). In order to access additional functionality in CUDA libraries or create customized CUDA kernel functions, it is also possible to use the function LibraryFunctionLoad from the LibraryLink package.
This post demonstrates a few examples in the Wolfram Language to:
- Invoke functions from CUDA host library APIs like Thrust and cuBlas
- Compile and load custom CUDA kernel functions
Some familiarity with the LibraryLink package would be helpful in understanding the idea behind this approach. The Wolfram LibraryLink User Guide is a good starting point.
To enable Mathematica to successfully load the CUDA Runtime Library, required for compilation of CUDA functions, it is recommended that you add the CUDA Runtime Library path to the system environment variable LD_LIBRARY_PATH.
1. Reducing a list of numbers
Here is a simple example of reducing a list of numbers (with the default + operator) in the Wolfram Language.
xList = {1,2,3,4};
res = Total[xList]
Here is the same operation performed in CUDA, using the Thrust Library.
#include <cuda_runtime.h>
#include <thrust/device_vector.h>
#include <thrust/reduce.h>
#include <thrust/execution_policy.h>
#include <iostream>
int main () {
thrust::device_vector<int32_t> dv{1,2,3,4};
const int32_t res = thrust::reduce(thrust::device, dv.begin(), dv.end());
std::cout << res << std::endl;
return 0;
}
This is a trivial example. The reduction function in Wolfram Language is highly optimized and already performs efficiently. Nevertheless, for the sake of demonstration, we wrap the call to the Thrust API in a C library function with LibraryLink.
extern "C" {
DLLEXPORT int cudaSumInt(WolframLibraryData libData, mint Argc, MArgument * Args, MArgument Res) {
// ---- On Host ---- //
MTensor inTensor;
mint * in;
inTensor = MArgument_getMTensor(Args[0]);
in = libData->MTensor_getIntegerData(inTensor);
const mint len = libData->MTensor_getFlattenedLength(inTensor);
// ---- On Device ---- //
thrust::device_vector<mint> dv(in, in+len);
const mint out = thrust::reduce(thrust::device, dv.begin(), dv.end());
// ---- Set Res ---- //
MArgument_setInteger(Res, out);
return LIBRARY_NO_ERROR;
}
}
To compile this library function, we also need to define WolframLibrary_getVersion, WolframLibrary_initialize and WolframLibrary_uninitialize. For more details about these LibraryLink functions, please refer to this section in the LibraryLink tutorial.
Here is an example of a Makefile to compile the code.
CC = nvcc
LINKTYPE = -shared
TARGET = ./libname.so
SOURCE = ./kernel_link.cu
NVCCFLAGS = -arch=sm_52 -O3
CFLAGS = -m64 --compiler-bindir /usr/bin --compiler-options -fPIC
MINSTALLDIR = /usr/local/Wolfram/Mathematica/11.0
INCMMA = $(MINSTALLDIR)/SystemFiles/IncludeFiles/C
INCGPU = $(MINSTALLDIR)/SystemFiles/Links/GPUTools/Includes
LIBMMA = $(MINSTALLDIR)/SystemFiles/Libraries/Linux-x86-64
INCMATHLINK = $(MINSTALLDIR)/SystemFiles/Links/MathLink/DeveloperKit/Linux-x86-64/CompilerAdditions
LIBMATHLINK = $(MINSTALLDIR)/SystemFiles/Links/MathLink/DeveloperKit/Linux-x86-64/CompilerAdditions
INCCUDA = /usr/local/cuda-8.0/include
LIBCUDA = /usr/local/cuda-8.0/lib64
$(TARGET) :
$(CC) $(LINKTYPE) -L $(LIBCUDA),$(LIBMATHLINK),$(LIBMMA) $(CFLAGS) $(NVCCFLAGS) -I $(INCMMA),$(INCMATHLINK),$(INCGPU),$(INCCUDA) -o $(TARGET) $(SOURCE)
The compiled library can now be loaded into the Mathematica with LibraryFunctionLoad.
In[1]:= libFunc = LibraryFunctionLoad[NotebookDirectory[] <> "libname.so",
"cudaSumInt", {{Integer, _}}, {Integer}]
In[2]:= libFunc[{1,2,3,4}]
Out[2]:= 10
This provides an alternate way to load CUDA libraries into Mathematica.
You can find another example in the archive link below. That example demonstrates how a function from cuBlas host API can be invoked in the Wolfram Language.
2. Custom CUDA kernel function - myCUDAFunctionLoad
You may want to write your own CUDA kernel function and wish to call it from the Wolfram Language. The following example demonstrates how this can be done.
2.1 Templating
The StringTemplate function in the Wolfram Language can be used to create a library source file with the CUDA kernel functions.
includes =
"#include <cuda_runtime.h>
#include <stdio.h>
";
template =
"extern \"C\" {
#include \"WolframLibrary.h\"
DLLEXPORT mint WolframLibrary_getVersion( ) {
return WolframLibraryVersion;
}
DLLEXPORT int WolframLibrary_initialize(WolframLibraryData libData) {
return LIBRARY_NO_ERROR;
}
DLLEXPORT void WolframLibrary_uninitialize(WolframLibraryData libData) {
return ;
}
DLLEXPORT int `dl_func_name`(WolframLibraryData libData, mint Argc, MArgument * Args, MArgument Res) {
// Memory Management
`loc_mem`
// Block and thread size define
dim3 block_size(`loc_bs`);
dim3 thread_size(`loc_ts`);
// Launch Kernel
`kernel_func_name`<<<block_size, thread_size>>>(`loc_args`);
cudaDeviceSynchronize();
// Set return
`loc_return`
// Free Device Memory
`loc_free`
return LIBRARY_NO_ERROR;
}
}";
A simple template to create a function that mimics the compile command would be as follows:
compiletemplate =
"\"`nvcc`\" -shared -L\"`cudalib`\" -L\"`mathlib`\" -L\"`syslib`\" -m64 --compiler-bindir \"`ccpath`\" --compiler-options -fPIC -arch=sm_`arch` -O3 -I\"`sysinclude`\" -I\"`mathinclude`\" -I\"`gtinclude`\" -I\"`cudainclude`\" -o `target` `source`";
This template can now be used to create the compile function.
compile[sourcePath_String,cudaToolkitPath_String,arch_Integer]:=
Module[{command,libpath},
command=StringTemplate[compiletemplate]
[<|
"nvcc"->cudaToolkitPath<>"/bin/nvcc",
"cudalib"->cudaToolkitPath<>"/lib64",
"mathlib"->$InstallationDirectory<>"/SystemFiles/Links/MathLink/DeveloperKit/Linux-x86-64/CompilerAdditions",
"syslib"->$InstallationDirectory<>"/SystemFiles/Libraries/Linux-x86-64",
"ccpath"->"/usr/bin",
"arch"->ToString[arch],
"sysinclude"->$InstallationDirectory<>"/SystemFiles/IncludeFiles/C",
"mathinclude"->$InstallationDirectory<>"/SystemFiles/Links/MathLink/DeveloperKit/Linux-x86-64/CompilerAdditions",
"gtinclude"->$InstallationDirectory<>"/SystemFiles/Links/GPUTools/Includes",
"cudainclude"->cudaToolkitPath<>"/include",
"target"->StringReplace[sourcePath,".cu"->".so"],
"source"->sourcePath
|>];
RunProcess[$SystemShell,"StandardOutput",command];
Return[StringReplace[sourcePath,".cu"->".so"]];
]
The compiled executable will be placed in the same directory as the source file, with the same name, but with a different extension.
2.2 Helper Functions
A few helper functions are also required for assembling the source code containing the custom CUDA Kernel function. Their names and description are as follows:
- sizeToString : this converts a list (length <= 3) into a string to fit into
loc_bs and loc_ts
- scalarMemMange : this generates C code for scalar (int or double) variables according to a customizable argument list
- arrayMemManage : this generates C code for array (Host and Device) variables according to a customizable argument list
- returnMemMange : this generates C code for returning data to Mathematica
- memManage : this assembles all memory related source code
- srcAssemble : this assembles the final source code for the C library, where the CUDA kernel function is queued
Once the source code has been prepared, myCudaFunctionLoad is invoked to compile and load the function with LibraryFunctionLoad.
myCUDAFunctionLoad[cudaToolkitPath_String, kernel_String, kname_String, args_List, bs_, ts_:32, arch_Integer:60]
:= Module[{source,sourcePath,libPath,func,iargs,oarg},
source = srcAssemble[kernel, kname,args, bs,ts];
sourcePath = Export[$TemporaryDirectory<>"src_"<>kname<>".cu",source,"Text"];
libPath = compile[sourcePath,cudaToolkitPath,arch];
iargs = args/.{x_,y_,z_}->{x,y};
oarg = Cases[args,{_,_,"Output"}][[1,;;-2]];
func = LibraryFunctionLoad[libPath,"host_"<>kname,iargs,oarg];
Return[func];
]
The myCUDAFunctionLoad function takes as arguments:
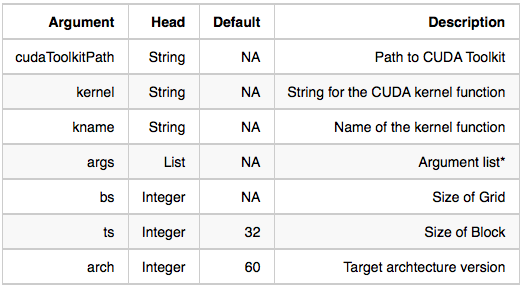
Notice, the format for the args list is the same as that used by CUDAFunctionLoad and LibraryFunctionLoad
The code above can be tested with a very simple kernel function, defined below.
kernels =
"__global__ void linear_plus(double alpha, double * a, double beta, double * b, int NMAX)
{
size_t idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx<NMAX) {
a[idx] = alpha * a[idx] + beta * b[idx];
}
}
";
This function is then loaded into Mathematica and used as follows:
In[13]:= func =
myCUDAFunctionLoad[
"/usr/local/cuda-8.0",
kernels,
"linear_plus",
{Real,
{Real, _, "Output"},
Real,
{Real, _, "Input"},
Integer
},
1024,
32,
52
]

In[14]:= ma = RandomReal[10, 5];
mb = RandomReal[10, 5];
al = RandomReal[];
be = RandomReal[];
nmax = Length[ma];
In[18]:= func[al, ma, be, mb, nmax]
Out[18]= {3.20244, 3.07296, 3.75771, 1.94413, 4.75805}
In[19]:= al*ma + be*mb
Out[19]= {3.20244, 3.07296, 3.75771, 1.94413, 4.75805}
You can download all the code from this archive. Before you try it on your own machine, please set the correct value for arch (according to your architecture) in the call to myCUDAFunctionLoad.


