Abstract
The goal of this project was to develop a system that, given a definition or description, returns the name of the corresponding concept. Nowadays, one of the main and most popular approaches to consider when dealing with large amounts of data and means to learn from it, is Machine Learning. In the present project, this technique was explored via the Classify built-in function of Mathematica. Classify performed well for training sets consisting of balanced word-definition pairs; that is, sets having an homologous number of definitions per word. In unbalanced sets, performance was reduced dramatically, as the classifier chose only among the most frequent words. Further improvements include finding more sources so that balancing does not represent data loss, as well as building a recurrent neural network, which has been proven to be useful for this problem.
Data
The first part of this project was retrieving the necessary data. At the beginning, this was done by using the Mathematica WordData built-in function, but tests proved this to be insufficient for the classifier to train. By surfing the web for more content, a better source was found. Belonging to the Computer Laboratory of the University of Cambridge, this file contained compiled word-definition sets taken from 5 different freely available dictionaries: Wordnet, The American Heritage Dictionary, The Collaborative International Dictionary of English, Wiktionary and Websters. In total, this contained over 800,000 word-definition pairs.
Proof of Concept
The first approach at a solution was to attempt classifying small chunks of data with no special focus on homogeneity; that is, the amount of definitions per word could be very different in the training set (high variance). The results from these tests were under-performing, as the output from previously unseen definitions was always one of the most frequent words of the training set. From these results is that the emphasis turned towards balancing the training data.
The second approach at exploring possible solutions was built in cases, parting from the simplest one. As a proof of concept, the first of these consisted in taking 50 of the most common nouns in the English language, with the definitions normalized to the minimum among the maximum number of definitions for each word; in this case 60. This was prepared in a text file in the format <word, definition>.
The first step was importing this file, from a training_data folder found in the current directory:
simplePath=FileNameJoin[{NotebookDirectory[],"training_data","60Def50Words.csv"}];
rawData=Import[simplePath];
Then its necessary to put this into a list of associations, which is the format expected by Classify:
associate[elem_]:=Last[elem]-> First[elem];
wordDefSet=Map[associate, rawData];
Now wordDefSet was divided into two sets: training and testing:
Testing Set
The testing set consisted of one word-definition pair per word, taken randomly from the complete set.
simpleTestingSet=Normal[DeleteDuplicates[Association[RandomSample[wordDefSet]]]];
Training Set
The training set was just the compliment of the testing set.
simpleTrainingSet=Select[wordDefSet,Not[MemberQ[simpleTestingSet,First[#]->_]]];
Classify
With the input prepared, an attempt to solve the problem via Classify was made:
classifier=Classify[simpleTrainingSet,PerformanceGoal->"Quality",Method->"Markov"]
As a visual representation of performance, a ConfusionMatrixPlot was generated from both the classifier and the testing set:
ClassifierMeasurements[classifier,simpleTestingSet,"ConfusionMatrixPlot"]
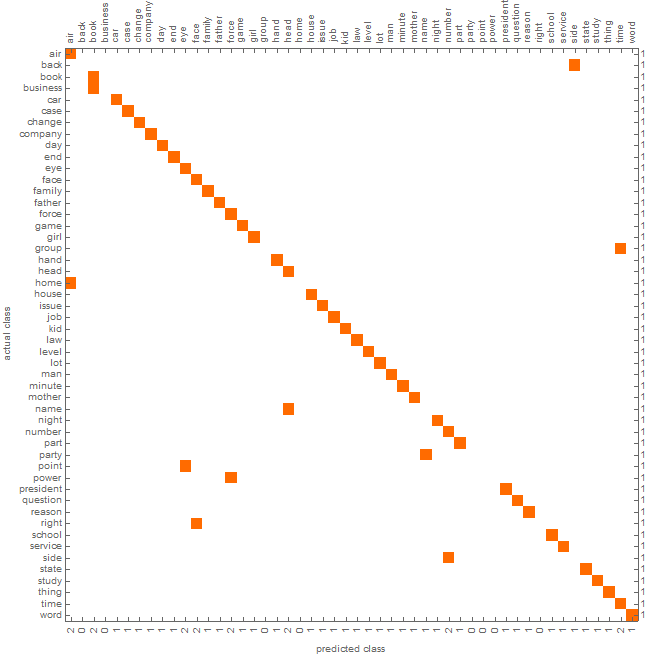
One can see that without bias, the classifier proved to be much more accurate. Testing on 50 previously unseen definitions, it showed an accuracy of approximately 80%. Testing with own definitions proves to be more interesting, as one can test the classifier limits.
classifier["60 seconds"]
"minute"
Larger Dataset
With confidence from these results, the next step was trying out the same approach for a larger amount of data. This time the training set consisted in words having 50 or more definitions, with the later being normalized to just 50, in order to minimize variance.
For this, a list of frequencies was generated from rawData:
completePath=FileNameJoin[{NotebookDirectory[],"training_data","training_data.csv"}];
rawData=Import[completePath];
freq=Reverse[SortBy[Tally[First[#]&/@rawData],Last]];
Then, with the following function, rawData could be filtered in order to output only words having a given number of definitions, discarding extra definitions and infrequent words:
getBalancedList[noElem_]:=Module[{wordSet,wordCounter,resultList,elem,word},(
wordSet=First[#]&/@Select[freq,Last[#]>=noElem&];
wordCounter=<||>;
resultList={};
For[i=1,i<=Length[rawData],i++,
elem=rawData[[i]];
word=First[elem];
If[MemberQ[wordSet,word],
If[KeyExistsQ[wordCounter,word],
If[wordCounter[[word]]<=noElem,
AppendTo[resultList,elem];
wordCounter[[word]]+=1],
AppendTo[wordCounter,word->1]
]
]
];
resultList
)]
Then, as in the previous section, the resulting list was parsed to comply with the format accepted by Classify:
balanced=getBalancedList[50];
balancedWordDef=Map[associate, balanced];
Testing and training sets were generated analogously to the previous example, and then passed into the classifier:
balTestingSet=Select[Normal[DeleteDuplicates[Association[RandomSample[balancedWordDef]]]]];
balTrainingSet=Select[balancedWordDef,Not[MemberQ[balTestingSet,First[#]->_]]];
classify=Classify[balTrainingSet,PerformanceGoal->"Quality",Method->"Markov"]
The resulting classifier showed satisfying results up to the tenth most probable word for a given definition. This means that the expected output was not necessarily the first one to come up, but it was among the top 10 most probable words.
textBal="";
InputField[Dynamic[textBal],String,ContinuousAction->True]
Dynamic[Column[First[#]&/@clssfy[textBal,"TopProbabilities"->10],Frame->All,Alignment->Left,ItemSize->{8, Automatic}]]


As a last exploration with Classify, the training set was taken to be the complete set of data, not caring about variance. As expected, this resulted in poor performance, with the classifier having a certain bias towards most frequent words.
Conclusions
From the obtained results, it can be concluded that input data plays a significant role in the performance of the classifier. This is easily explained in terms of the variance of the number of definitions per word. Less variance means better performance and vice versa. It has been suggested in previous work that a recurrent neural network may result in a solution for this problem. As further improvements to this method, it is suggested to try this approach and compare both techniques for the same training and testing sets; analyzing how both the balance in number of definitions and the total number of different words (or classes) affect the resulting performance.
GitHub repository
 Attachments:
Attachments:


