Introduction
Traditional strategies for identifying rhyme rely on the underlying phonological representations of words. However, it is often the case that pronunciation information is not available. In addition, spoken sounds change over time, making pervious pronunciations difficult to reconstruct.
The goal of this project is to identify rhyming word pairs from poetry without phonological information and in an unsupervised manner, specifically with clustering/graph theory. We attempt to effectively cluster groups of rhymes in a effort to discover how words may have been pronounced in the past.
Rhyming and non-rhyming data was collected. Unlabeled rhyming poems were processed and inserted into a Graph with words as nodes and observed pairs as edges. Pairs of words are clustered using graphs, and edges are weighted and cut if they do not meet a frequency threshold.
From all potential pairs to communities of rhyme
Approach
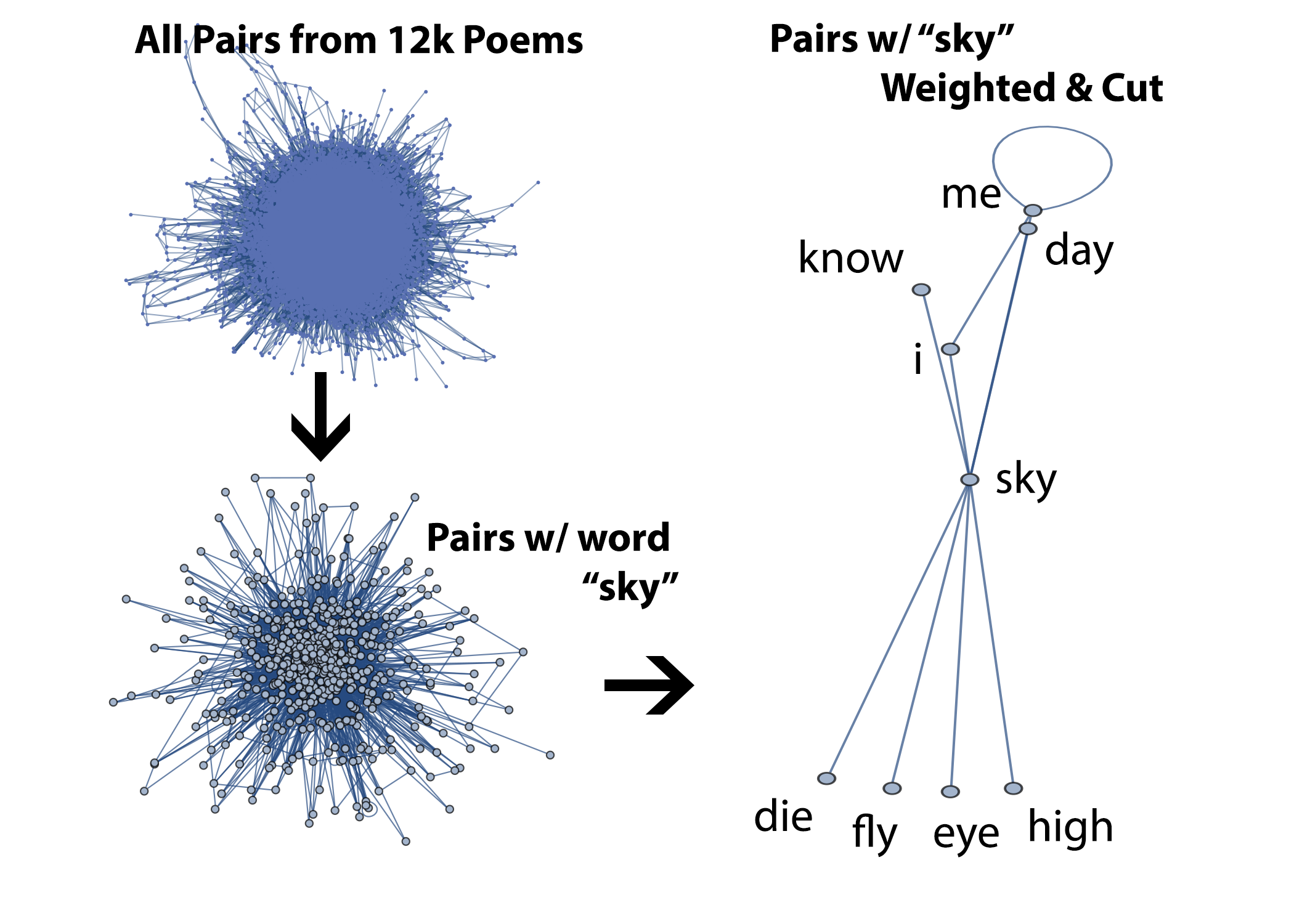
The process of identifying rhymes by clustering is motivated by the idea that pairs of end-line-words which appear in close proximity within many different rhyming works are likely to rhyme. We inject our data into Graphs were nodes are words and edges represent observed proximal pairs.
The resulting graphs eliminate many non-rhymes and show relatively dense clusters of rhymes. In future work we plan to utilize the non-rhyming from Wikipedia to further prune these graphs of high frequency non-rhyming pairs. This should allow for cutting of pairs such as "sky-day" and "i-me" from the graph. As seen in Ackerman's Mathematica Notebook (homework) on the space of perfect rhyme and perfect similarity, perfect rhyme and consonance do not happen frequently by chance. Further studies must be done to discover exactly how often and how proximally rhymes (of given degrees of similarity) occur in wikipedia entries.
Results
Using large amounts of unlabeled rhyming poems, it seems that relatively simple rhyme graphs are about to be weighted and trimmed significantly increase the ratio of rhyming words in neighborhoods of clustered nodes. While it seems precision has jumped at least 10x as a result of weighting and trimming, it is also likely that recall has been reduced dramatically as very uncommon rhyme pairs would be pruned by our method. These performance metrics should be corroborated with the methods discussed in the future.
Although our visualizations indicate improvements in clustering rhymes vs non-rhymes, many clusters do contain slant rhymes, half rhymes and words whose pronunciation has changed due to accents and historical vowel shifts, more detailed analysis is required to determine if this our model can reliably capture these variations.
More Graph Examples
Since we do not yet have robust performance metrics, here are some graphs on a small enough random sample of our data that we can easily visualize.
500 Poems - Weighted and Trimmed Graph 
2500 Poems - Weighted and Trimmed Graph 
Performance Metrics
In the current incarnation we use visual graph displays at the neighborhood level to explore our clustering effectiveness. While this is useful in broad strokes, we ultimately want a much more robust performance metric. In the future we intend to use the labeled rhyming data to create a performance metric for gauging the effectiveness of our rhyme clustering. Additionally, the phonetic distance search tool, Phonesse, developed by Ackerman, will be used to measure the phonetic distance of words in identified clusters.
Previous work
This work is motivated by Reddy and Knight's work on "Unsupervised Rhyme Scheme Detection", which uses the EM algorithm to distinguish rhymes from non-rhymes in the Sonderegger Dataset. Also Sonderegger uses his dataset to construct rhyme graphs which, when given only labeled rhymes, are able to distinguish between full and half rhymes through clustering.
References
- https://github.com/jordanmasters/WolfRamifications/blob/master/JordanAckerman_FP.nb
- Sonderegger/Reddy Collection
- WikipediaDump 2017
- PoemHunter.com
- PoetryFoundation.org
- Reddy. S and Knight K. 2011. Unsupervised discovery of rhyme schemes Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies: short papers-Volume 2.
- Sonderegger. M. 2011. Applications of graph theory to an English rhyming corpus. Computer Speech &Language. Volume-25. Issue-32. Pages 655-678.


