The goal of OCR (Optical Character Recognition) is to recognize characters in images. Here is how I used convolutional neural network to create an OCR working on images of single characters that supports 8 major writing systems: Arabic, Chinese, Cyrillic, Devanagari, Greek, Japanese, Korean, and Latin.
Neural Network
I developed my neural network based on LeNet by adding batch normalization layers, dropout layers, and more convolutional layers. Here is the architecture of my network:
OUCR = NetChain[{
ConvolutionLayer[32, {5, 5}, "PaddingSize" -> {2, 2}, "Stride" -> 2],
BatchNormalizationLayer["Input" -> {32, 32, 32}],
ElementwiseLayer[Ramp],
PoolingLayer[{2, 2}, {2, 2}],
ConvolutionLayer[64, {3, 3}, "PaddingSize" -> {1, 1}],
BatchNormalizationLayer["Input" -> {64, 16, 16}],
ElementwiseLayer[Ramp],
PoolingLayer[{2, 2}, {2, 2}],
ConvolutionLayer[128, {3, 3}, "PaddingSize" -> {1, 1}],
BatchNormalizationLayer["Input" -> {128, 8, 8}],
ElementwiseLayer[Ramp],
PoolingLayer[{2, 2}, {2, 2}],
ConvolutionLayer[256, {3, 3}, "PaddingSize" -> {1, 1}],
BatchNormalizationLayer["Input" -> {256, 4, 4}],
ElementwiseLayer[Ramp],
PoolingLayer[{2, 2}, {2, 2}],
FlattenLayer[],
DropoutLayer[0.5],
LinearLayer[],
SoftmaxLayer[]
},
"Output" -> NetDecoder[{"Class", unicode}],
"Input" ->
NetEncoder[{"Image", {64, 64}, "Grayscale", "MeanImage" -> 0.85}]
]
The first convolutional layer has kernels of size 5 and stride 2 to reduce the influence of noise. The fully connected layers are very simple due to the large volume (over 32000) of classes.
Training Set
To train my neural network, I generated over a million images of characters with different fonts and rotations using Mathematica. At first I used Rasterize[], which turned out to be so slow that it would take tens of hours to generate all the images. So I improved my algorithm by using Image[], Graphics[], and Text[] instead, which took only a few minutes. Here are the two functions I designed to generate images:
unrotated[list_, size_, scale_, font_, horizontal_, vertical_] :=
Module[{len, col, row},
len = Length[list];
col = Floor[Sqrt[len]];
row = Ceiling[len / col];
Thread[(Join @@
ImagePartition[
Image[
Graphics[
MapIndexed[
Text[
Style[#1, FontFamily -> font, FontSize -> Scaled[scale / col]],
Reverse[#2]] &,
Reverse[
Partition[FromCharacterCode /@ list, UpTo[col]]
],{2}],
PlotRange -> {{horizontal, col + horizontal}, {vertical, row + vertical}},
ImageSize -> {size * col, size * row}],
ColorSpace -> "Grayscale"], size])[[;; len]]
->
FromCharacterCode /@ list]]
rotated[list_, size_, scale_, font_, angle_, horizontal_, vertical_] :=
Module[{len, col, row},
len = Length[list];
col = Floor[Sqrt[len]];
row = Ceiling[len / col];
Thread[(Join @@
ImagePartition[
Image[
Graphics[
MapIndexed[
Rotate[
Text[
Style[#1, FontFamily -> font, FontSize -> Scaled[scale / col]],
Reverse@#2],
RandomVariate[
NormalDistribution[0, angle]] Degree] &,
Reverse[
Partition[FromCharacterCode /@ list, UpTo[col]]
], {2}],
PlotRange -> {{horizontal, col + horizontal}, {vertical, row + vertical}},
ImageSize -> {size * col, size * row}],
ColorSpace -> "Grayscale"], size])[[;; len]]
->
FromCharacterCode /@ list]]
These functions take a list of Unicodes and generate images of unrotated and rotated characters of the corresponding Unicodes. There are several tunable parameters. "size" controls the size of the images (size * size), where I used 64 for my training set. "scale" controls the scale of characters in images, where I found 0.7~0.8 suitable for most writing systems and fonts. For "font", I chose several fonts for each language to make the characters as diverse as possible. "horizontal" and "vertical" are compensations, where 0.5 works for most cases. rotated[] also takes "angle" and generates rotated images whose rotational angles follow a normal distribution with standard deviation of "angle" degrees, where I used 4 degrees in most cases.
For each font of each writing system, I generated 1 unrotated and 3 rotated images for the training set and 1 rotated image for the validation set. There was no obvious overfitting or underfitting during the training process, and after 70 rounds of training, the validation loss was down to 5*10^-3.
Tests
Here is the bar chart of accuracies recognizing characters of each writing system, tested on random samples with random fonts and random rotations:
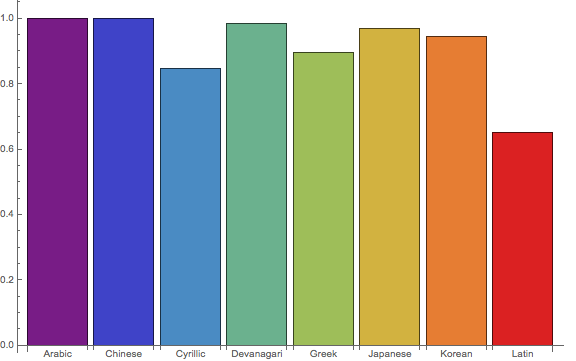
The accuracies recognizing Cyrillic, Greek, and Latin characters are rather low because some of their characters are very similar. The accuracy recognizing Latin characters is especially low because I tested on a random sample of all fonts, and Latin characters can look very different in different fonts, while many fonts don't support other writing systems.
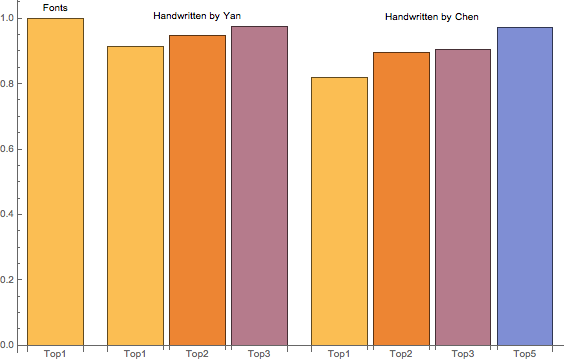
Here is the bar chart of accuracies recognizing a random sample of 200 Chinese characters, tested on characters generated by the computer (different fonts), handwritten by Yan, Zhenqing (709-785, one of the best calligraphers in Chinese history, images from http://www.shufazidian.com/), and handwritten by myself (written on paper, scanned, and processed using Mathematica):
Two short examples of how it works (first handwritten by Yan, second handwritten by myself):

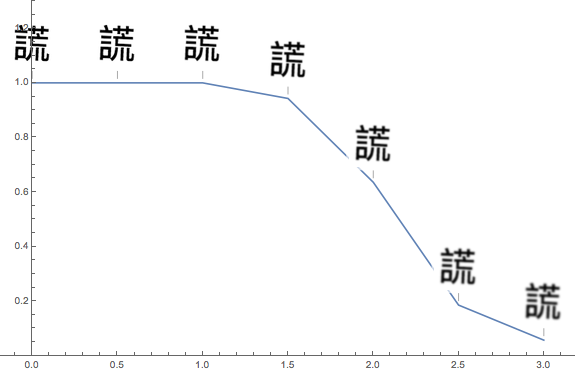
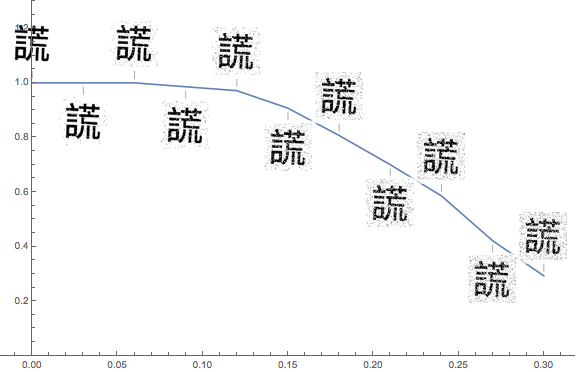
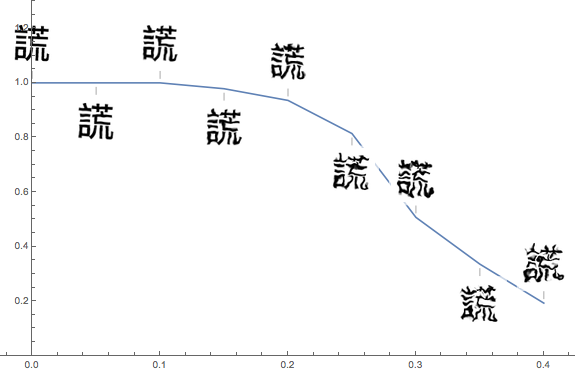
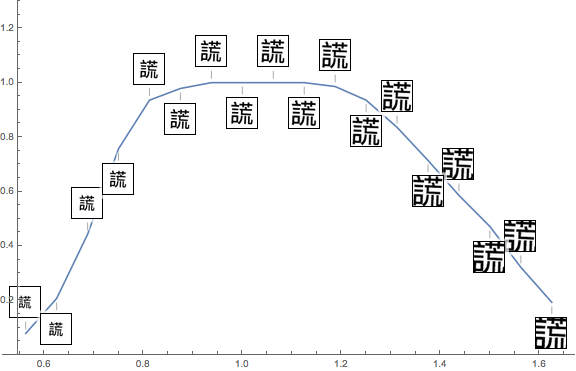
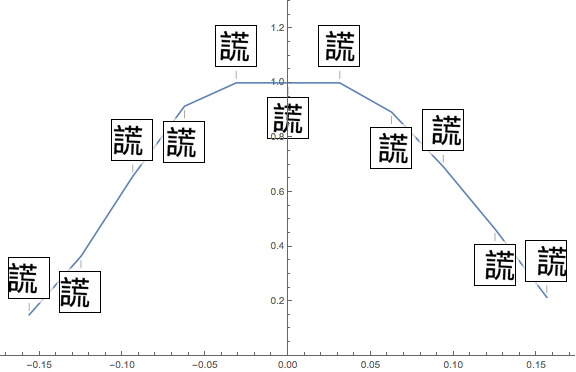
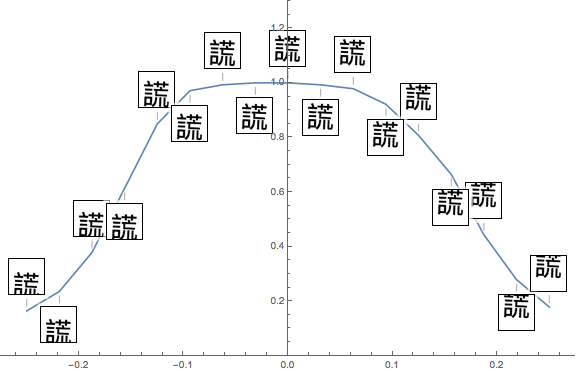
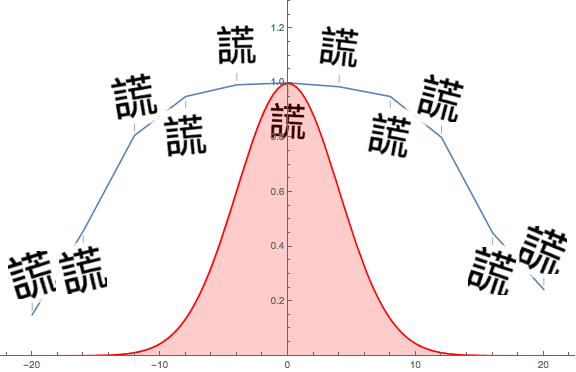
I also tested my network on many variations of the images, including blurring, adding noise, distortion, zooming in and out, horizontal and vertical movement, and rotation:
Acknowledgements
I would like to thank my mentor Vladimir Grankovsky for helping me along the whole project and Matteo Salvarezza and Timothée Verdier for helping me set up AWS GPU computing services.
References
- Image source for Yan's handwritten Chinese characters: http://www.shufazidian.com/
- My GitHub repository: https://github.com/MatthewChen7211/WSS2017


