Collecting Data
In order to perform analysis on Wikipedia articles, we need to define our set. Since the computational field is relatively small, we can do this by searching for "Computational" on Wikipedia and filtering out all results that don't contain "computational" or "journal".
Link Analysis
We can use the WikipediaData[] function in the Wolfram Language to collect all necessary information we need. By creating a graph where a node is an article in our set and a directed edge is a link, we can create a directed graph showing how articles within the set are linked.
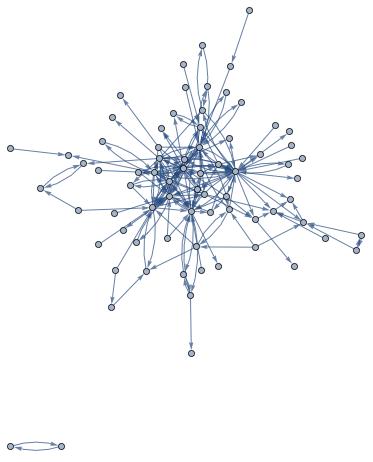
If we run CommunityGraphPlot[] on this graph, we can see how articles are sub-grouped based on their links.
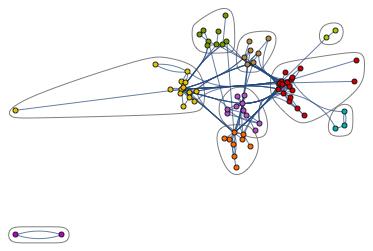
We can then coalesce these groups into individual points to see more clearly how the groups interact with each other.
If we automatically label the groups by word frequency we end up with this:
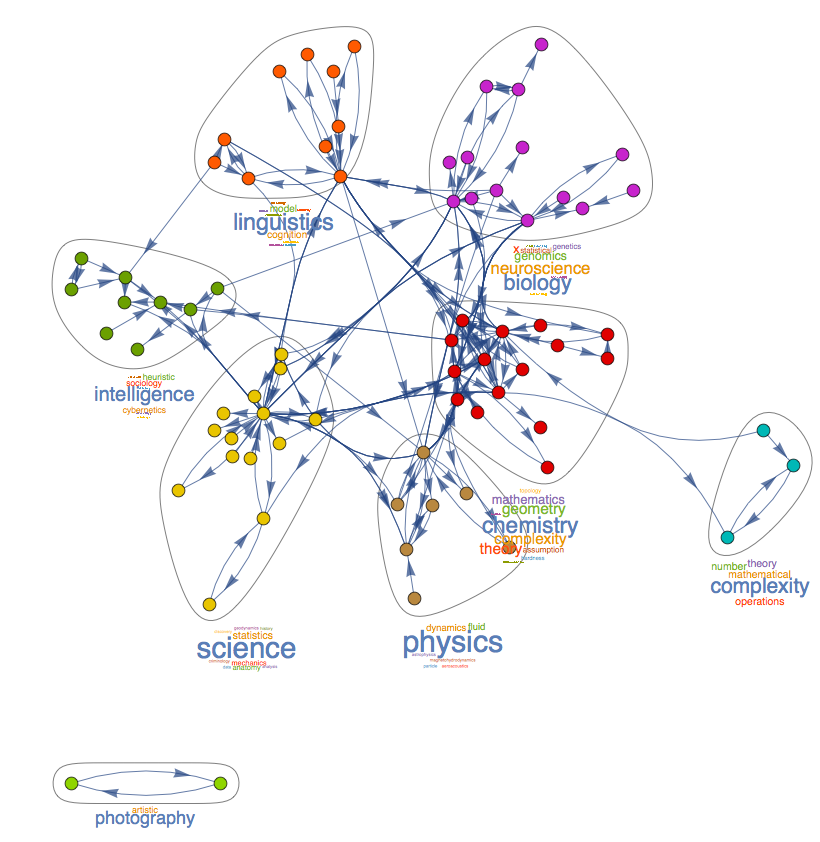
Edit Histories
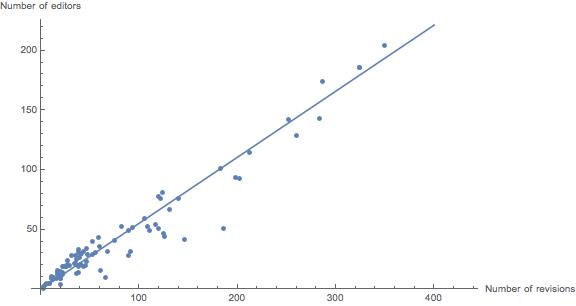
Using https://tools.wmflabs.org/xtools-articleinfo/ we can easily collect data on the edits over time from any Wikipedia article.
We can look at various statistics such as number of unique editors versus number of total revisions. Three of one hundred articles have been removed as outliers to more easily view the majority.
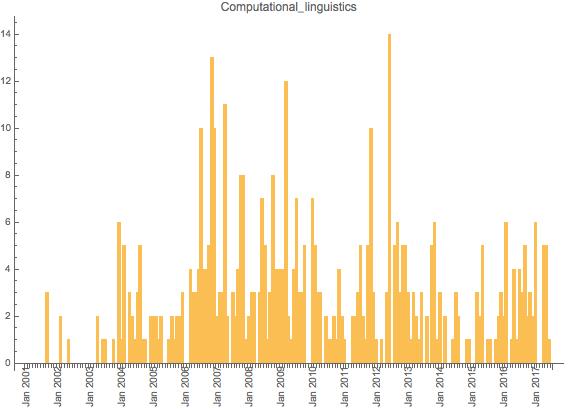
We can also look and see how all of our articles have been edited over time.
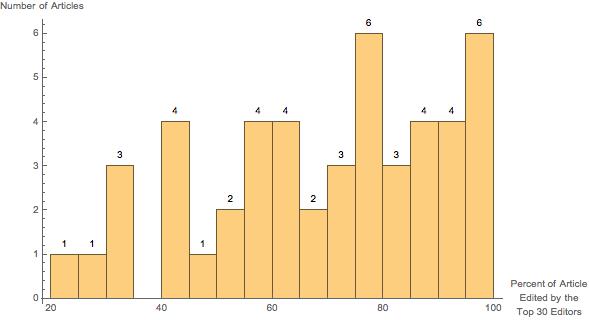
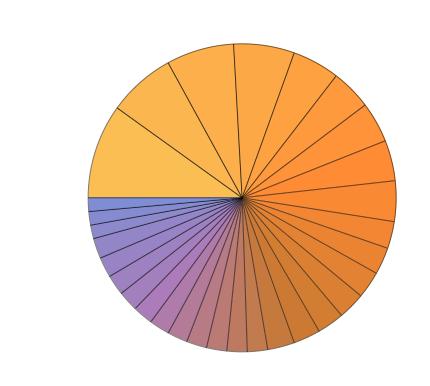
If we look at the composition of the top 30 editors, we can see what percent of edits made by the top 30 editors each editor made. For computational biology, it looks like this:
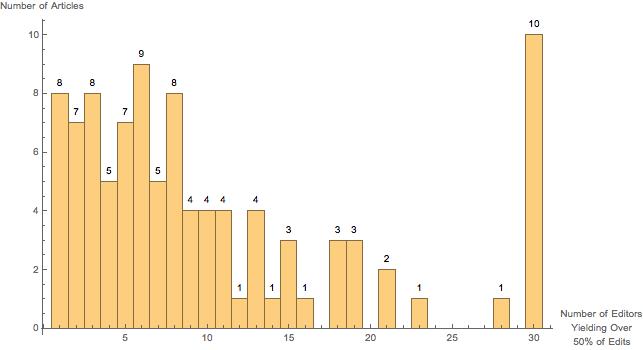
Another interesting graph we can look at is seeing how many editors it takes to reach over 50% of an article's total edits. Individualized data is not provided past the top 30 editors, leading to the spike at 30.
Lastly, we can look and see of articles that have more than 30 editors, what percentage of total edits did the top editors contribute.