Is This A Joke?
Is This A Joke? is a project to use machine learning to determine if things are funny. However, many things contribute to what makes up humor, with context, timing and content appearing to me to be the most important. I decided to classify jokes in the format question + answer, as it is a common format for jokes, and it also happens regularly in casual conversation.
Method
My first challenge was to find a good data set of jokes. I copied jokes down from various sources by hand before figuring out WL could connet to reddit and pull posts from r/Jokes. This appears to be my biggest issue despite the ease of using reddit. As reddit only allows WL to access the most recent 1000 posts and only about one third of the posts are in a Q/A format, my training data set wasn't as large as I'd wanted.
FixRedditDataJoke[redDat_] := (
Cases[
Values /@ redDat[[2]][[All, {"Title", "Selftext"}]],
{x_String, y_String} /; Characters[x][[-1]] == "?"
]
/.
{a_String, b_String} :> {a, StringSplit[b, {".", "!", "
"}][[1]]}
)
reddit = ServiceConnect["Reddit"]
DataSetJoke =
RandomSample[
FixRedditDataJoke[
Normal@reddit["SubredditPosts", "Subreddit" -> "Jokes",
"ShowThumbnails" -> False, MaxItems -> 1000,
"StartIndex" -> 1]]];
My next major challenge was finding a collection of normal questions and answers, something that isn't generally recorded. I ended up using r/AskReddit, which isn't optimal but was the best I could find.
QandA[post_] := {post["Title"],
First@TextSentences@
First[reddit["PostCommentsData", "Post" -> post["URL"]][
"Comments"]]["Body"]}
posts = reddit["SubredditPosts", "Subreddit" -> "AskReddit",
"ShowThumbnails" -> False, MaxItems -> n][[2]];
postsD = Select[posts, #["CommentsCount"] > 0 &];
DataSetNormal = RandomSample[Normal[QandA /@ postsD]];
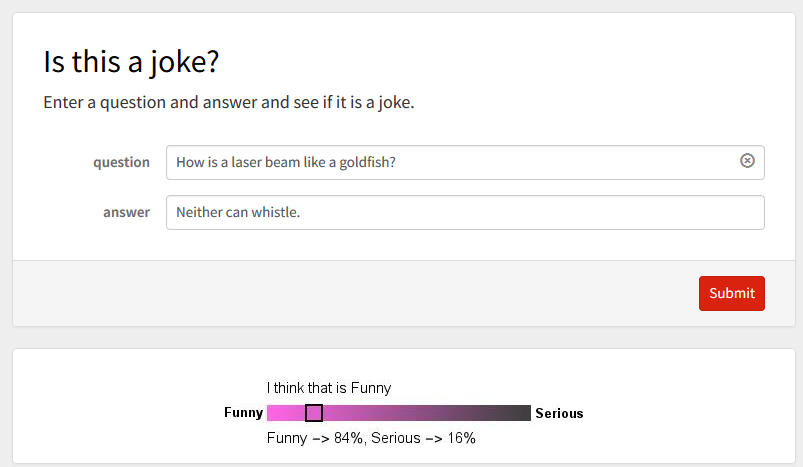
The microsite is simply a form page. I planned to have it upload the user input jokes to a databin, but haven't had time to do that yet.
FormPage[FormObject[{"question" -> "String", "answer" -> "String"},
AppearanceRules -> <|"Title" -> "Is this a joke?",
"Description" ->
"Enter a question and answer and see if it is a joke."|>][<|
"question" -> "How is a laser beam like a goldfish?",
"answer" -> "Neither can whistle."|>],
(
funny =
1 - FunnyOrNotWithDucks[{#question, #answer},
"Probability" -> "Funny"];
width = 1/64;
height = 1/16;
Graphics[Join[
{Black,
Text[Style["Funny", Larger, Bold], {-width, height/2}, {1, 0}]},
Table[{Blend[{RGBColor[1, .4, .9], GrayLevel[.25]}, x],
Rectangle[{x, 0}, {x + width, height}]}, {x, 0, 1 + width,
width}], {EdgeForm[Thick],
Blend[{RGBColor[1, .4, .9], GrayLevel[.25]}, funny],
Rectangle[{funny, 0}, {funny + height, height}], Black,
Text[Style["Serious", Larger, Bold], {1 + width*3,
height/2}, {-1, 0}]}, {Black,
Style[#, Larger] &@
Text["I think that is " <>
FunnyOrNotWithDucks[{#question, #answer}], {0,
height*1.5}, {-1, -1}]},
{Black,
Style[#, Larger] &@
Text["Funny -> " <>
ToString[Floor@(Normal@(100 - 100*funny))] <>
"%, Serious -> " <>
ToString[Ceiling@(Normal@(100*(funny)))] <>
"%", {0, -height*.5}, {-1, 1}]}],
ImageSize -> Medium]
) &]
Results
The classifier built from this data worked great on test data separated from the same source, about 90% accuracy, but this doesn't mean it works well on all data. Using jokes and normal questions polled from other students it had an accuracy of 90% on a sample of 15 jokes and 15 normal QAs. The classifier is currently on a microsite here.
Future
While it surpassed my expectations, the classifier isn't as versatile as it could be. The plan is to have the input QAs entered on the site saved and labeled by users to improve the classifier. There are also several other directions I plan to analyze, mainly classifying freeform jokes such as stories and classifying pictures such as memes.


