Where Stephen and I disagree
I was watching this live CEO-ing about various functions to add to the language in some future release and I commented:
When we have MapAt or Extract I feel like ColumnMap doesn't gain us much... I'm in favor of a tighter core language. Fewer symbols with clearer documentation on how best to use them.
To which Stephen responded:
The reason is--and it's a change over the last 30 years in what I believe about language design--if there's a piece of functionality that you can readily name or which you can bundle under that name, it makes sense to do it
And I've been thinking about that sporadically since and I feel that his view and mine aren't necessarily incompatible, but that his is more wrong than mine.
Why I disagree
First I'd like to note that his answer doesn't totally clash with my views on programming (unlike some--much?--of what he says in these twitch streams). A well-designed function optimized by an expert will always be better than an equivalent function cobbled together in haphazard fashion by someone who is not an expert. One of the cute things about writing WL code is that you can chain together functions in a way that basically self-documents and this type of view point is
But I'd like to note why I think it's a dangerous argument to make and will ultimately make end-users' lives worse. I have three core reasons for disagreeing:
- Too many functions makes writing code harder
- Too many functions makes maintaining code harder
- Too many functions makes optimizing code harder
On the other hand I enjoy having a large collection of well-designed functions to work with and it's what makes WL development more addictive than C++ dev.
So the question is can we have it both ways? Can we have a large collection of optimized functions that auto-document without bloating the core language to the point that it requires knowing the idiosyncrasies of Mathematica and the specific functions you want to use to know how to best write a program?
That I am even willing to pose this question obviously indicates that I believe the answer to be yes.
First though, I should back up my previous assertions on why too many functions is a bad thing.
Too many functions makes writing code harder
If you work with Mathematica regularly you are used to typing a symbol and having the autocompletion popup give you tons of alternates. In the current "System`" namespace there are 6256 Names. Knowing which of these functions is best to use can be a major headache. As just one quick example, we can do many of the same things with Part, Extract, and Take, but each has its own subtle differences; its own flavors. And knowing which to use and when can make life difficult. The fact that Part has a convenient alias makes this less of an issue but this type of issue abounds.
Furthermore, there are hundreds of functions in Mathematica that could be better expressed as a subcase of a single parent function. Rather than having to memorize function names and usages, it would be nicer to have a single parent function with top-notch documentation that supplies these subcases via the FEPrivate`AddSpecialArgCompletion system. The times that's freed up by not needing to memorize symbols and specialized use cases and bugs and quirks can be applied to actually writing code instead.
Too many functions makes maintaining code harder
This view point comes from the other side. For the actual developers, the more functions they have which are exposed at top-level, the more potential for nasty edge cases that have to be handled on a function-by-function basis. The more stuff that's exposed in the public API, the more bloated it is, the more surface-area in which cracks can form.
Many complaints I see on the StackExchange arise out of specific cases not being handled by function X but being appropriately handled by sister function Y. These are clearly places where a dev did good work improving Y, but forgot that X required a similar treatment. On the other hand, if they were both under a function Z then the case could be handled (e.g. data appropriately canonicalized) before ever passing into X or Y leading to a single point to fix.
Too many functions makes optimizing code harder
This thought comes out of what I know / have heard about the hot new language Julia. By writing a tight, optimized core language and building everything on top of that the Julia devs were able to build a flexible, efficiently compilable dynamic language. In essence, the fewer functions you use as building blocks the better you can optimize your code. Given that so much high-performance Mathematica code has to be written in a procedural manner to be able to use Compile (and that there's a next-gen compiler coming out that sounds like it should be like Julia-lite) if there were a tighter core-language that could be better compiled we could do much more with optimizing our code. Obviously it's too late to turn back the clock and prevent the bloat now, but it's worth being wary of introducing ever more core-language functions with questionable breadth of use
How we can reconcile these views
As I noted earlier, I think it's possible to reconcile Stephen's desire for ever more named bundles of functionality and my desire for tighter interfaces. The key is to put those named bundles of functionality into deeper contexts and build a tight interface on top of them. To some extent Mathematica already does this. The Entity system may have many-too-many functions in it leading to lack of clarity as to how to best work with Entities, but it could have been much, much worse:
Names["EntityFramework`*"] // Length
(* Out: 92 *)
As a concrete example of how this can be done though, I'd like to tell a story of part of a package I've been developing in my free time and on weekends for a bit over a year now. At some point last spring I learned about paclets. At that point I started working on a set of tools for working with paclets. Over a few months I ended up with about 18 functions for this:
PacletAPIUpload - for uploading paclets via an API like the Google Drive APIPacletAutoPaclet - for auto-generating a paclet from a package file or directory or GitHub repoPacletBundle - for bundling a paclet with .gitignore-type protectionsPacletInfo - for extracting the Paclet expressionPacletInfoAssociation - for converting/extracting the Paclet expression into an Association for ease of usePacletInfoExpression - for converting Options into a PacletPacletInfoGenerate - for autogenerating a "PacletInfo.m" file from a directory and optionsPacletInstalledQ - for testing whether a paclet has been installedPacletInstallPaclet - for installing paclets (especially from GitHub repos)PacletLookup - for fast, batch Lookup of paclet informationPacletOpen - for opening a paclet's directoryPacletRemove - for removing a paclet from a serverPacletSiteBundle - for exporting the "PacletSite.mz" filePacletSiteInfo - for extracting the PacletSite from a server or directoryPacletSiteInfoDataset - for turning the PacletSite into a DatasetPacletSiteUpload - for uploading the "PacletSite.mz" to a serverPacletSiteURL - for getting the upload URL for a serverPacletUpload - for uploading a paclet to a server
This is a lot of functions to memorize. And it gets clunky to have to apply changes to 18 functions at once (okay probably only at most 5 at once) when I could do it at some parent level function instead.
So sometime in the past month I moved these into a lower-level context that my package does not automatically push onto the $ContextPath and made them subcases of a function that is clearer and easier to maintain (and which is on the path), PacletExecute. This allows me to have a very simple interface to work with, but still allows these functions to be accessible:
PacletExecute["GeneratePacletInfo", "Function"]
(* Out: BTools`Paclets`PacletTools`PacletInfoGenerate *)
This way those who know what they're doing and who can truly make use of a specialized function like this can still have it. But now in general the interface is so much cleaner. And even better this allows us to better take advantage of autocompletions:
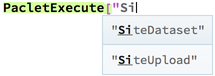
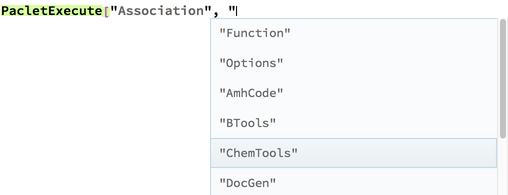
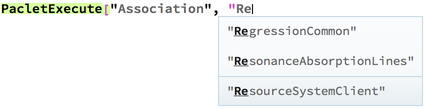
PacletExecute["Association", "ResourceSystemClient"][[1]]
<|"Extensions" -> <|"Kernel" -> <|"Symbols" -> {"System`$PublisherID",
"System`$ResourceSystemBase", "System`CreateResourceFunction",
"System`PublisherID", "System`ResourceAcquire",
"System`ResourceFunction",
"System`ResourceFunctionInformation", "System`ResourceObject",
"System`ResourceRegister", "System`ResourceRemove",
"System`ResourceSearch", "System`ResourceSubmissionObject",
"System`ResourceSubmit", "System`ResourceSystemBase",
"System`ResourceUpdate"}, "Root" -> "Kernel",
"Context" -> {"ResourceSystemClient`"}|>,
"FrontEnd" -> <|"Prepend" -> True|>|>, "Loading" -> "Automatic",
"Location" ->
"/Applications/Mathematica.app/Contents/SystemFiles/Links/\
ResourceSystemClient", "MathematicaVersion" -> "11.3+",
"Name" -> "ResourceSystemClient", "Version" -> "1.9.2.1"|>
I hope this provides food-for-thought if not for Stephen Wolfram himself, at least for those who read this. And hopefully in the future we start to see cleaner, simpler APIs and more subcontexts.


