Many scientific readability indices have been developed to determine the reading levels of texts since the late 1940's. Indices based on ratios of word and syllables counts, ratios of 'easy' words to total words used, and other textual characteristics dominate in these approaches. Popular indices such as the Fry Readability Graph, Flesch Reading Ease Test, Dale-Chall Raw Score, SMOG and FOG tests have been widely used for assessments in the military, education, and for various other purposes. The State of Florida uses one such test to verify that insurance policies are readable!
The common structure of most current readability formula is that it consists of a limited number of parameters that reflect either the reading difficulties on the word level, or on the sentence level. For example, the parameters average sentence length and number of different words are often used. Almost every readability formula consists of parameters that represent either semantic or syntactic complexity. The parameters get a score of how well they correlate with the classified data and then the parameters, or combinations of parameters, with the highest score are used in the formula. The output of a readability formula is usually a classification into the level of education the reader needs to be able to understand the text.
Below are some examples of classical readability tests:
Dale-Chall Raw Score for Reading Level The original Dale-Chall Formula was developed for adults and children above the 4th grade level, and aimed to correct certain shortcomings in the Flesch Reading Ease Formula. It was a sentence-length variable plus a percentage of hard words[LongDash] words not found on the Dale-Chall long list of 3000 easy words, 80 percent of which are known to fourth-grade readers.
Clear[ASL, PDW, a, b, c]
a = 0.1579; b = 0.496; c = .6365;
PDW[text_] := 1 - Total[WordFrequency[text, daleChalls3000]]
ASL[text_] := N[Mean[WordCount /@ TextCases[text, "Sentences"]]]
DaleChallRawScore[text_] := a * PDW[text] + b * ASL[text] + c
Automated Readability Index The Automated Readability Index (ARI) relies on characters per word instead of syllables per word which distinguishes this measurement from many other types of readability measurements. It is easier to calculate accurately since determining the number of characters is easier than determining syllables.
Clear[a, b, c, sentences, wordcounts, characters]
a = 4.71; b = 0.5; c = 21.43;
sentences[text_] := Length[TextCases[text, "Sentences"]];
wordcounts[text_] := WordCount[text];
characters[text_] := StringLength[text];
ARI[text_] :=
a *characters[text]/wordcounts[text] +
b*wordcounts[text]/sentences[text] - c
Coleman - Liau Formula
a = 5.89; b = 0.3; c = 15.8;
Coleman[text_] :=
a*characters[text]/wordcounts[text] -
b*sentences[text]/(100*wordcounts[text]) - c
Limited Utility of Traditional Readability Scores Many studies have been done on the accuracy of traditional systems for reading level indexation. One interesting study by Reck & Reck in 2012, "Generating and Rendering Readability Scores for Project Gutenberg Texts", applying various scoring systems to 15,000 digitized texts. The results demonstrated that many of the commonly-used scoring systems produced relatively narrow score distributions.
Additionally, a common characteristic in all methods is that they have been developed for documents with at least 10 sentences or 100 words. Therefore, traditional scoring systems may be unreliable when the size of the text drops below the requirement, as frequently occurs in the current media environment.
Readability Scores for 15,000 Books in the Gutenberg Project
Distribution of Readability Scores: (1) Automated Readability Index, (2) Flesch Reading Ease, (3) Coleman-Liau 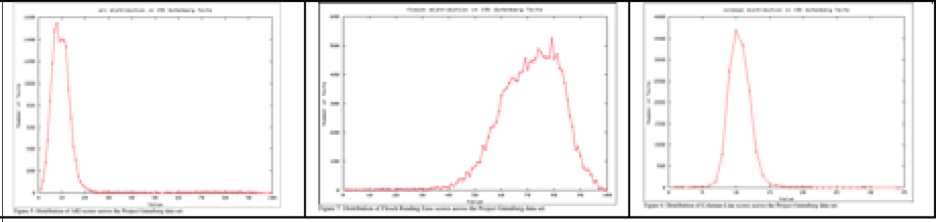
This study also identified that the distribution of counts of syllables per word, words per sentence, and characters per word are narrow in the Gutenberg Project data set, which helps explain the narrow distributions of the readability indices.
Distribution of Scoring Factors: (1) Syllables Per Word, (2) Characters Per Word, (3) Words Per Sentence 
Variability of Readability Scores Within One Book
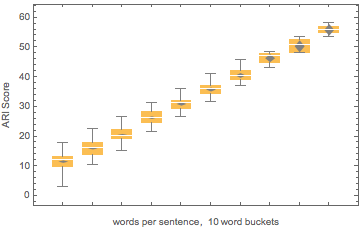
The limitations of traditional text readability scores become clear when their dependence on simple word- and syllable-counting factors. For example, within a single book or block of text, individual sentences can have widely varying readability scores. Below, I show data from a single book sample from the Gutenberg Project, suggesting that there is very high correlation of the ASI score with the count of words in each particular sentence:
sampleData = TextSentences[ Import["http://www.gutenberg.org/cache/epub/14916/pg14916.txt"]][[\ 101 ;; 1000]];
wordCount = WordCount /@ sampleData; k = 10;
Do[ assoc[i] = Select[ Association[ Sort[ Thread[sampleData -> wordCount]] ], # >= i10 && # < i10 + 10 & ], {i, k} ];
Do[
scoreARI[i] = ARI /@ Keys[assoc[i]],
{i, k}
]
means = Mean@*scoreARI /@ Range[k];
standardD = StandardDeviation /@ scoreARI /@ Range[k];
Needs["HypothesisTesting`"];
Quiet[Remove[NormalCI]];
MapThread[
NormalCI[#1, #2] &,
{means, standardD}
];
plot1 = BoxWhiskerChart[scoreARI /@ Range[k], "Diamond",
PlotLabel -> "ARI Scores", AxesLabel -> {"", "Passage Length,"}];
Show[plot1,
FrameLabel -> {{HoldForm[ARI Score],
None}, {RawBoxes[
RowBox[{RowBox[{"words", " ", "per", " ", "sentence"}], ",", " ",
RowBox[{"10", " ", "word", " ", "buckets"}]}]], None}},
PlotLabel -> None]
New developments in readability scoring systems
One such approach the Lexile Framework for Reading, based research led by A. Jackson Stenner and Malbert Smith, and funded by U.S. The National Institute of Child Health and Human Development (NICHD). The Lexile framework utilizes quantitative methods, based on individual words and sentence lengths, rather than qualitative analysis of content to produce scores. Accordingly, the scores for texts do not reflect factors such as multiple levels of meaning or maturity of themes. In the US, Lexile measures are reported from reading programs and assessments annually; about half of U.S. students in grades 3rd through 12th receive a Lexile measure each year. In addition to being used in schools in all 50 states, Lexile measures are also used in 24 countries outside of the United States. See https://lexile.com/ for additional information.
Random sampling and testing with the Lexile scoring system produced similar results to those of ASI above; a high correlation between sentence length and Lexile score can often be observed, using a free text analyzer for text up to 1000 characters, at https://la-tools.lexile.com/free-analyze/. The Lexile scoring algorithm is not publicly disclosed, nor is the distribution of Lexile scores among books ranked by the company.
Need For More Accurate Readability Scoring Systems
With an increasing amount of text read by children and adults appearing not in books but online in websites, blogs, articles, research papers, and other media, there is clearly a need for new readability scoring systems. A variety of human-labeled reading indices are currently available on the Internet: Examples include grade level rankings by Amazon.com and Scholastic.com, Readable.io, the Classroom Library Company, and others. These rankings are subjective and only apply to entire books, and only a small subset of text that a student or adult may encounter online.
In future, I hope to further explore the possibility of training a neural network to evaluate reading level reflecting text context, sentence structure, topic area, vocabulary level, and other factors that human beings take into account when deciding what to read.


