Goal: Extracting Readable Text from Byte Arrays + Identifying File Format for Snippets of Byte Arrays [=/ Headers]. With potential application as improved function or as part of a simple data carver.
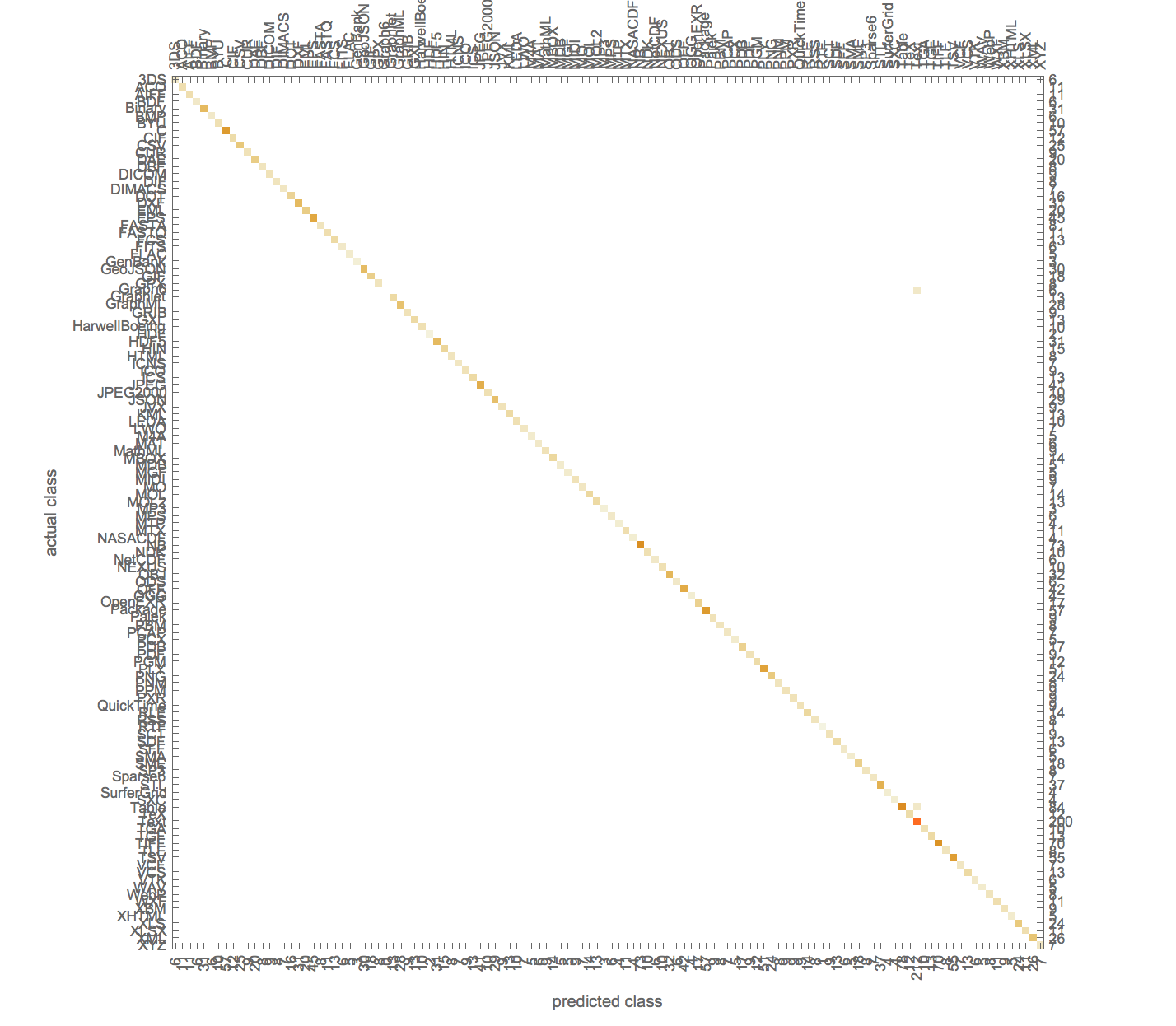
Summary of Results: The FileFormat Function in the Wolfram Language, works by reading the magic# also known as the file header. Without the header the language is unable to recognize the file. Readable Text was Extracted from the Byte Arrays, giving the reader metadata and in many cases the contents of the file. A Machine Learning Approach was used to differentiate between the different file formats of 128 byte snippets, which doesn't contain the magic number of the file. As seen by the graph below, the accuracy was astounding. However, the machine was not extensively tested on outside files.
Process: Files were extracted from the Wolfram Example Database. Next the code was analyzed to determine which character encoding system was likely used. That was system was then applied to extract Readable Text from the Files. For the Machine Learning portion, A Classify Function was trained on random snippet of the files with a size of 128 bytes, excluding the header of the text. It was then tested again on the Example Database and few outside files.
Future Work: Work is being on how such a result could help partially recover corrupted files. Many corrupted files are often due to splits between once homogenous content of various file forms. With the headers and footers missing or misplaced, computers cannot recognize the individual segments. By Analyzing the File Formats in sections, sections could potentially be stitched back together. Building such a Data Carver would only work for certain types of corrupted files. More advanced approaches are required for higher levels of corruption.


