
Abstract
The objective of this project was to use machine learning to classify texts as either prose or poetry. I trained a model using texts obtained from the ExampleData function and the Open Library service. The model's accuracy rate was 91%. I then deployed my model as a Resource Function and as a microsite. Possible avenues for further exploration include adding more texts (especially modern literature) to the training data and expanding the model to classify foreign language texts.
Introduction
Much of human literature can be considered either prose and poetry. Prose refers to language written in its ordinary form. Its characteristics include a natural flow of words and the organization of sentences into blocks of text (paragraphs). Meanwhile, poetry is a more decorative form of literature, using devices not usually found in prose such as rhythm and rhyme to express its ideas. While there are clear linguistic differences between prose and poetry, the divide between the two genres is not always clear. For example, the stream of consciousness narrative mode (used in prose) can exhibit poetic elements, and the prose poem organizes text as paragraphs instead of stanzas as in traditional poetry. In this project, I hope to differentiate between these two genres by creating a classifier using machine learning and the Wolfram language.
Methods
Training Data
I obtained the training data from two sources: the ExampleData function and the Open Library resource. I wrote a function called sentenceBlock that returns a sample of about 100 words from a text.
Divide and Conquer: The sentenceBlock Function
The sentenceBlock function takes a list of sentences. It then picks a random starting point and concatenates consecutive sentences to create a block of text until the total word count reaches 100. The function then returns the text block.
sentenceBlock[textSentences_] :=
Module[{len = Length[textSentences], i, wordCount = 0, block = "", s},
i = RandomInteger[{1, len}];
While [i <= len && wordCount < 100,
s = textSentences[[i]];
wordCount += (StringCount[s, " "] + 1);
block = StringJoin[block, s];
i += 1
];
block
]
Using sentenceBlock to split up a text instead of feeding the entire text into the neural net at once conserves memory when training the model. Without this function, it is possible that the neural net would run out of memory when handling large texts, which can contain hundreds of thousands of words.
One method of obtaining training data was using the ExampleData function:
pride = ExampleData[{"Text", "PrideAndPrejudice"}];
prideSentences = TextSentences[pride];
prideTraining = Table[sentenceBlock[prideSentences] -> "Prose", 200];
The advantage of this method was that each text was already processed. Therefore, it was quite easy to split the text into a list of sentences and then collect training data using sentenceBlock. However, because there were only a limited number of texts available in ExampleData, I had to use another method to collect more training data.
keatsPoems = openlibrary["BookText", {"BibKeys" -> {{"OLID", "OL7171138M"}}}];
keatsRaw = keatsPoems[[1]];
keatsClean = StringTake[keatsRaw, {37680, -7180}];
keatsSplit = StringSplit[keatsClean, "."];
keats1 = DeleteCases[keatsSplit /. s_?StringQ /; StringLength[s] < 20 -> "", ""];
keatsSentences = StringJoin[#, "."] & /@ keats1;
keatsTraining = Table[sentenceBlock[keatsSentences] -> "Poetry", 500];
The advantage of this method was that Open Library contained an almost unlimited number of texts. However, it was often difficult to get the texts I wanted. Due to copyright law, I was unable to obtain contemporary literature from Open Library. For older texts, sometimes only one out of 50+ editions contained the full text of the book. Despite this issue, Open Library was invaluable to my project, providing 70% of the poetry training data over half of the total training data.
Finally, I collected all my training data into a single variable.
poetryData = RandomSample[
Join[
aeneidTraining, beowulfTraining, bostonTraining, boyTraining,
byronTraining, eliotTraining, keatsTraining, poeTraining,
poundTraining, sonnetTraining, tennysonTraining, wasteTraining,
whitmanTraining
]
];
proseData = RandomSample[
Join[
aliceTraining, constitutionTraining, citiesTraining, donTraining,
ivanhoeTraining, magnaTraining, platoTraining, prideTraining,
speciesTraining, waldenTraining
]
];
trainingData = RandomSample[
Join[
poetryData,
proseData
]
];
Training the Model
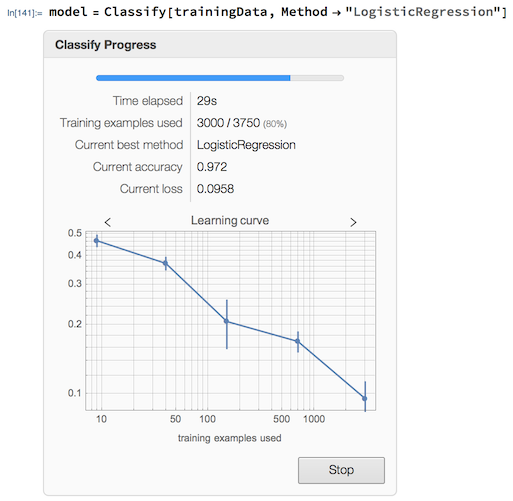
I used the Classify function to train my model from trainingData.
model = Classify[trainingData, Method -> "LogisticRegression"]
Visualizations
I wanted to visually compare the prose-like/poetic nature of the input text with other texts, so I used NumberLinePlot and plotted each text as a point indicating my model's confidence in its classification. After experimenting with color scales, I decided on a Yellow-Cyan-Magenta color scheme. Finally, I also created a legend for my plot.
textList = {
"\"I Have a Dream\"\!\(\*
StyleBox[\" \",\nFontSlant->\"Italic\"]\)(Martin Luther King): \!\(\*
StyleBox[\"PROSE\",\nFontWeight->\"Bold\"]\)",
"\!\(\*
StyleBox[\"Ender\",\nFontSlant->\"Italic\"]\)\!\(\*
StyleBox[\"'\",\nFontSlant->\"Italic\"]\)\!\(\*
StyleBox[\"s\",\nFontSlant->\"Italic\"]\)\!\(\*
StyleBox[\" \",\nFontSlant->\"Italic\"]\)\!\(\*
StyleBox[\"Game\",\nFontSlant->\"Italic\"]\)\!\(\*
StyleBox[\" \",\nFontSlant->\"Italic\"]\)(Orson Scott Card): \!\(\*
StyleBox[\"PROSE\",\nFontWeight->\"Bold\"]\)",
"\"A Rose for Emily\" (William Faulker): \!\(\*
StyleBox[\"PROSE\",\nFontWeight->\"Bold\"]\)",
"\"Excelsior\" (Henry Wadsworth Longfellow): \!\(\*
StyleBox[\"POEM\",\nFontWeight->\"Bold\"]\)",
"\"Friends, Romans, countrymen, lend me your ears\" (Shakespeare): \
\!\(\*
StyleBox[\"POEM\",\nFontWeight->\"Bold\"]\)",
"\"[Because I could not stop for Death - ]\" (Emily Dickinson): \!\
\(\*
StyleBox[\"POEM\",\nFontWeight->\"Bold\"]\)",
"\"[anyone lived in a pretty how town]\" (e. e. cummings): \!\(\*
StyleBox[\"POEM\",\nFontWeight->\"Bold\"]\)",
"Your Text"
};
ppPlot[result_] := Grid[
{
{
If [result < 50, type = "Prose", type = "Poetry"];
Graphics[
Text[
Style[StringJoin[type, " (",
ToString[Max[result, 100 - result]], "% confidence)"], Bold,
FontSize -> 16], {50, 0}],
AspectRatio -> 1/10,
ImageSize -> Large
]
},
{
Show[NumberLinePlot[
{
{mlkProse}, {cardProse}, {faulknerProse},
{longPoem}, {shakePoem}, {dickPoem}, {cummingsPoem},
{result}
},
PlotLabel ->
Style["How does your text compare to other literature?", Bold,
FontSize -> 14],
PlotStyle -> {
{Darker[Blend[{Yellow, Cyan, Magenta}, mlkProse/100], 0.1],
PointSize[0.02]},
{Darker[Blend[{Yellow, Cyan, Magenta}, cardProse/100], 0.1],
PointSize[0.02]},
{Darker[Blend[{Yellow, Cyan, Magenta}, faulknerProse/100],
0.1], PointSize[0.02]},
{Darker[Blend[{Yellow, Cyan, Magenta}, longPoem/100], 0.1],
PointSize[0.02]},
{Darker[Blend[{Yellow, Cyan, Magenta}, shakePoem/100], 0.1],
PointSize[0.02]},
{Darker[Blend[{Yellow, Cyan, Magenta}, dickPoem/100], 0.1],
PointSize[0.02]},
{Darker[Blend[{Yellow, Cyan, Magenta}, cummingsPoem/100],
0.1], PointSize[0.02]},
{Darker[Blend[{Yellow, Cyan, Magenta}, result/100], 0.1],
PointSize[0.03]}
},
Spacings -> None,
PlotRange -> {0, 100},
AspectRatio -> 1/10,
ImageSize -> Large,
Ticks -> {
{
{0, Style["More prose-like", Larger, Bold, Darker@Yellow]},
{50, Style["Don't know", Larger, Bold, Darker@Cyan]},
{100, Style["More poetic", Larger, Bold, Darker@Magenta]}
}
}
], PlotRangePadding -> {{Scaled[0.05], Scaled[0.05]}, {0, 1}}]
},
{
SwatchLegend[
{
Blend[{Yellow, Cyan, Magenta}, mlkProse/100],
Blend[{Yellow, Cyan, Magenta}, cardProse/100],
Blend[{Yellow, Cyan, Magenta}, faulknerProse/100],
Blend[{Yellow, Cyan, Magenta}, longPoem/100],
Blend[{Yellow, Cyan, Magenta}, shakePoem/100],
Blend[{Yellow, Cyan, Magenta}, dickPoem/100],
Blend[{Yellow, Cyan, Magenta}, cummingsPoem/100],
Blend[{Yellow, Cyan, Magenta}, result/100]
},
textList
]
}
},
Spacings -> {1, 2}
]
Here is a sample graphic generated by ppPlot:
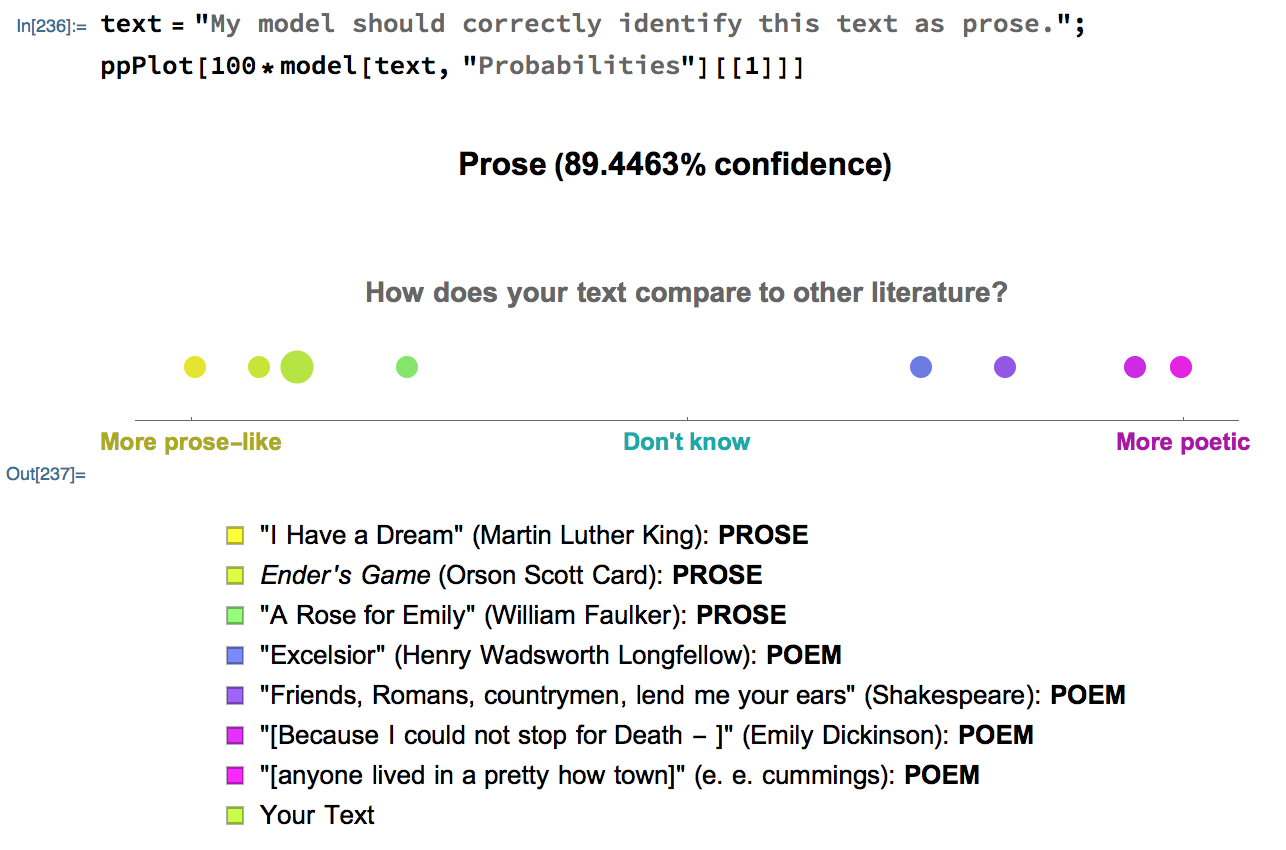
Deploying the Microsite
I created a microsite which allows users to enter text as input. The microsite then prints the model's classification and confidence level and the plot comparing the input text with other texts.
ppClassify[text_] := Module[{model = CloudGet[
CloudObject[
"https://www.wolframcloud.com/objects/michaelyw11/PP_Model"]],
result = 100*model[text, "Probabilities"][[1]]},
ppPlot[result]
]
CloudDeploy[
FormPage[
{"Text" -> "TextArea"},
ExportForm[ppClassify[#Text], "PNG"] &,
AppearanceRules -> <|
"Title" -> "Prose vs. Poetry Classifier"|>
],
CloudObject["prosepoetry"],
Permissions -> "Public"
]
The microsite can be found at https://www.wolframcloud.com/objects/michaelyw11/prosepoetry.
Deploying the Resource Function
I also deployed the model as a resource function called ProseOrPoetry. The documentation can be found at https://www.wolframcloud.com/objects/michaelyw11/ProseOrPoetry
Analysis & Future Work
In testing, my model achieved an accuracy rate of 91%. I found that my model was significantly less reliable when classifying modern poetry compared to other texts. This could be explained by both my inability to find modern texts for my training data due to copyright restrictions and by the increasing similarity between modern poetry and prose.
Regarding future work, in addition to increasing the amount of training data (especially modern poetry) to improve my model's accuracy, I can also create similar models to classify texts in foreign languages such as prose or poetry.
A few interesting remarks:
- My model's certainty seems to reflect the actual prose-like/poetic nature of the texts. For example, the model is very certain that Martin Luther King's "I Have a Dream" speech is prose, while the model is less certain about William Faulkner's "A Rose for Emily", which exemplifies his style of including poetic elements in his prose.
- Increasing the amount of line breaks in the input text also increased the model's likelihood to classify the text as poetry. Thus, it appears that my model was able to differentiate between paragraphs (used in prose) and the stanzas (used in poetry).
- Replacing periods by question marks or exclamation points also increased the model's likelihood to classify the text as poetry. This suggests that poetry contains more emotion than prose.
Conclusion & Acknowledgements
In this project, I achieved my objective of using machine learning to classify texts as either prose or poetry. I really enjoyed working on this project during my time at the Wolfram Summer Camp, and I would like to give a big thank you to my mentor, Rob Morris, as well as the other mentors at the Wolfram Summer Camp for helping me with the project.


