With all the marvelous new functionality that we have come to expect with each release, it is sometimes challenging to maintain a grasp on what the Wolfram language encompasses currently, let alone imagine what it might look like in another ten years. Indeed, the pace of development appears to be accelerating, rather than slowing down. However, I predict that the "problem" is soon about to get much, much worse. What I foresee is a step change in the pace of development of the Wolfram Language that will produce in days and weeks, or perhaps even hours and minutes, functionality might currently take months or years to develop. So obvious and clear cut is this development that I have hesitated to write about it, concerned that I am simply stating something that is blindingly obvious to everyone. But I have yet to see it even hinted at by others, including Wolfram. I find this surprising, because it will revolutionize the way in which not only the Wolfram language is developed in future, but in all likelihood programming and language development in general. The key to this paradigm shift lies in the following unremarkable-looking WL function WolframLanguageData[], which gives a list of all Wolfram Language symbols and their properties. So, for example, we have:
WolframLanguageData["SampleEntities"]

This means we can treat WL language constructs as objects, query their properties and apply functions to them, such as, for example:
WolframLanguageData["Cos", "RelationshipCommunityGraph"] 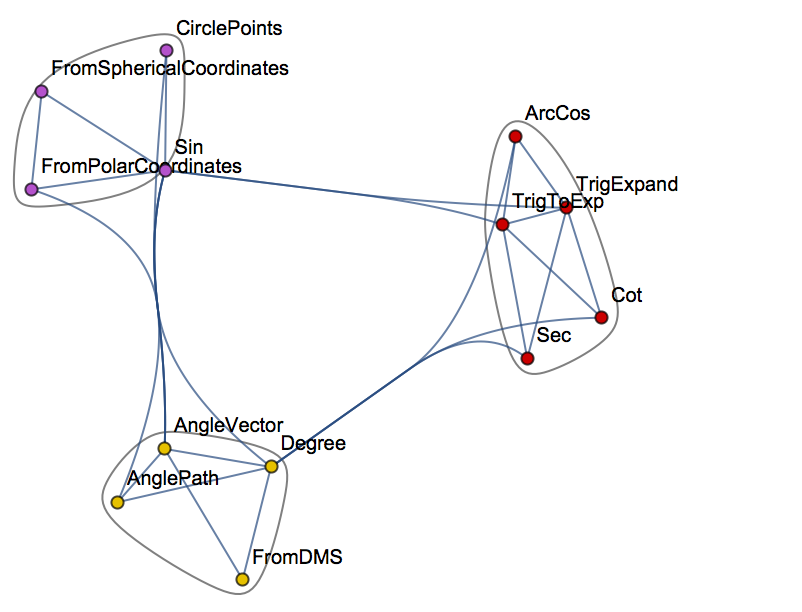
In other words, the WL gives us the ability to traverse the entirety of the WL itself, combining WL objects into expressions, or programs. This process is one definition of the term Metaprogramming.
What I am suggesting is that in future much of the heavy lifting will be carried out, not by developers, but by WL programs designed to produce code by metaprogramming. If successful, such an approach could streamline and accelerate the development process, speeding it up many times and, eventually, opening up areas of development that are currently beyond our imagination (and, possibly, our comprehension).
So how does one build a metaprogramming system? This is where I should hand off to a computer scientist (and will happily do so as soon as one steps forward to take up the discussion). But here is a simple outline of one approach.
The principal tool one might use for such a task is genetic programming:
WikipediaData["Genetic Programming"]
In artificial intelligence, genetic programming (GP) is a technique whereby computer programs are encoded as a set of genes that are then modified (evolved) using an evolutionary algorithm (often a genetic algorithm, "GA") it is an application of (for example) genetic algorithms where the space of solutions consists of computer programs. The results are computer programs that are able to perform well in a predefined task. The methods used to encode a computer program in an artificial chromosome and to evaluate its fitness with respect to the predefined task are central in the GP technique and still the subject of active research.
One can take issue with this explanation on several fronts, in particular the suggestion that GP is used primarily as a means of generating a computer program for performing a predefined task. That may certainly be the case, but need not be.
Leaving that aside, the idea in simple terms is that we write a program that traverses the WL structure in some way, splicing together language objects to create a WL program that does something. That something may be a predefined task and indeed this would be a great place to start: to write a GP metaprogramming system that creates WL programs that replicate the functionality of existing WL functions. Most of the generated programs would likely be uninteresting, slower versions of existing functions; but it is conceivable, I suppose, that some of the results might be of academic interest, or indicate a potentially faster computation method, perhaps. However, the point of the exercise is to get started on the metaprogramming project, with a simple(ish) task with very clear, pre-defined goals and producing results that are easily tested. In this case the objective function is a comparison of results produced by the inbuilt WL functions vs the GP-generated functions, across some selected domain for the inputs.
I glossed over the question of exactly how one traverses the WL structure for good reason: I feel sure that there must have been tremendous advances in the theory of how to do this in the last 50 years. But just to get the ball rolling, one could, for instance, operate a dual search, with a local search evaluating all of the functions closely connected to the (randomly chosen) starting function (WL object), while a second long distance search jumps randomly to a group of functions some specified number of steps away from the starting function.
[At this point I envisage the computer scientists rolling their eyes and muttering doesnt this idiot know about the {fill in the bank} theorem about efficient domain search algorithms?].
Anyway, to continue. The initial exercise is about the mechanics of the process rather that the outcome. The second stage is much more challenging, as the goal is to develop new functionality, rather than simply to replicate what already exists. It would entail defining a much more complex objective function, as well as perhaps some constraints on program size, the number and types of WL objects used, etc.
An interesting exercise, for example, would be to try to develop a metaprogramming system capable of winning the Wolfram One-Liner contest. Here, one might characterize the objective function as something interesting and surprising, and we would impose a tight constraint on the length of programs generated by the metaprogramming system to a single line of code. What is interesting and surprising? To be defined thats a central part of the challenge. But, in principle, I suppose one might try to train a neural network to classify whether or not a result is interesting based on the results of prior one-liner competitions.
From there, its on to the hard stuff: designing metaprogramming systems to produce WL programs of arbitrary length and complexity to do interesting stuff in a specific domain. That interesting stuff could be, for instance, a more efficient approximation for a certain type of computation, a new algorithm for detecting certain patterns, or coming up with some completely novel formula or computational concept.
Obviously one faces huge challenges in this undertaking; but the potential rewards are also enormous in terms of accelerating the pace of language development and discovery. It is a fascinating area for R&D, one that the WL is ideally situated to exploit. Indeed, I would be mightily surprised to learn that there is not already a team engaged on just such research at Wolfram. If so, perhaps one of them could comment here?


