Very interesting, Marco! The Wiki data can actually be used to reflect on what candidates people view as related. Again your data:
fullnames = {{"Donald", "TRUMP"}, {"Jeb", "BUSH"}, {"Scott", "WALKER"}, {"Marco", "RUBIO"},
{"Chris", "CHRISTIE"}, {"Ben", "CARSON"}, {"Rand", "PAUL"}, {"Ted", "CRUZ"},
{"Mike", "HUCKABEE"}, {"John", "KASICH"}, {"Carly", "FIORINA"}};
data = ParallelMap[WolframAlpha[#[[1]] <> " " <> #[[2]],
{{"PopularityPod:WikipediaStatsData", 1}, "ComputableData"}] &, fullnames];
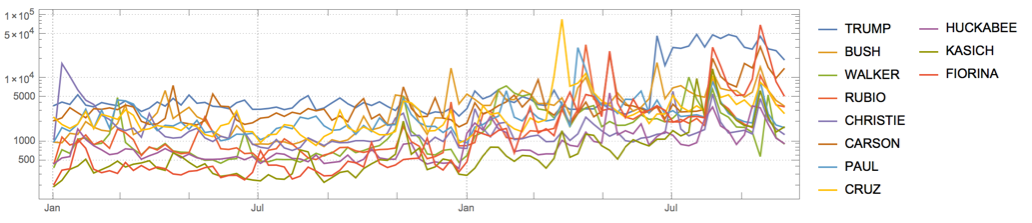
But I'll get the last year to be fair to the recent campaign and use log plot to see better the details:
recent = TimeSeriesWindow[#, {{2014, 1, 1}, Now}] &@ TemporalData[data];
DateListLogPlot[recent, PlotRange -> All, PlotTheme -> "Detailed", AspectRatio -> 1/4,
ImageSize -> 800, PlotLegends -> fullnames[[All, 2]]]
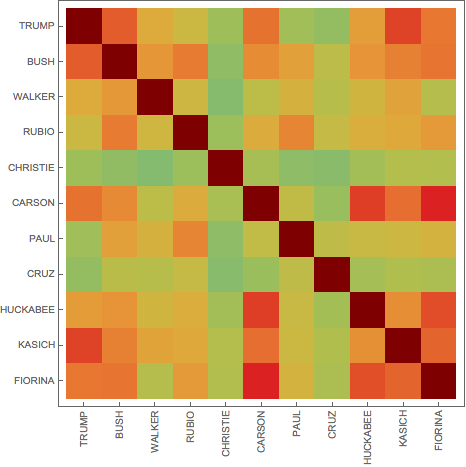
Let's get mutual correlation matrix - note the diagonal INfinity trick - for the self-edge removal in WeightedAdjacencyGraph.
m = Outer[Correlation, #, #, 1] &@
QuantityMagnitude[Normal[recent][[All, All, 2]]] (1 - IdentityMatrix[Length[fullnames]]) /. 0. -> Infinity;
Significant negative correlations are hard to get in such data, but positive values can be quite high:
m // Flatten // Sort

MatrixPlot[m, FrameTicks -> {Transpose[{Range[11], #}], Transpose[{Range[11], Rotate[#, Pi/2] & /@ #}]},
ColorFunction -> "Rainbow"] &@fullnames[[All, 2]]
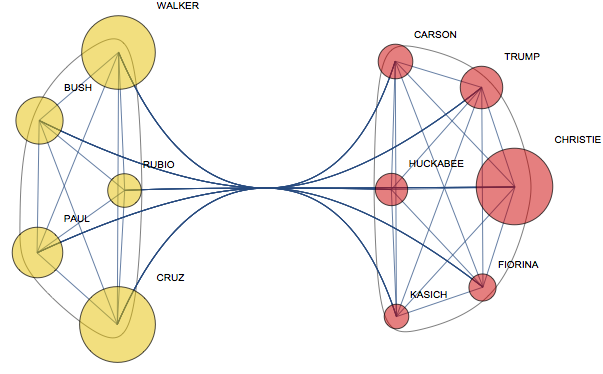
So we are getting a complete weighted graph:
g = WeightedAdjacencyGraph[m, VertexLabels -> Thread[Range[11] -> fullnames[[All, 2]]],
VertexSize -> "ClosenessCentrality", VertexStyle -> Opacity[.5]];
FindGraphCommunities still react on EdgeWeight:
comm = FindGraphCommunities[g]
{{1, 5, 6, 9, 10, 11}, {2, 3, 4, 7, 8}}
So I wonder if anyone with actual knowledge of politics can see in this clustering some truth:
CommunityGraphPlot[g, comm]