The Problem at Hand: Given a large document, how can Mathematica tell which words are important?
There are of course, a few quick and easy ways to find Keywords, but here we investigate some more involved methods.
Our Corpus will be a chapter of Harry Potter and the Sorcerer's Stone. Originally, I did this exploration using the US Code, but it is difficult to follow along with what is happening if we do not already have some familiarity with the corpus.
We may first try to build a word cloud of the corpus using WordCloud[ ]. This is a fast and intuitive way to visualize keywords, and a good starting point. 
Unfortunately it is not particularly helpful, in that all this Word Cloud seems to say is the Harry, Dudley, Petunia, and Vernon are important in this chapter. It is immediately obvious that Harry Potter would be important in a book about Harry Potter, and the rest of the keywords only hint that this chapter is from the beginning of the book.
Here is the main problem to overcome. We want to search for keywords that are not series specific Jargon. Ideally, we want words important in the context of their document, not just words that appear frequently.
We attempt to refine our Frequency Analysis by comparing the frequency of words against some sample text. There are two ways we can form the relevance factor, we can try rank movement, or coefficients. We will try rank movements first.
When we use Rank movement, we are seeing how far up or down a word moves in a sorted list of frequencies. For example, if "Apple Apple Banana" was my corpus, and "Apple Apple Banana Banana Banana" was my sample text, I would first create a sorted frequency list for my corpus, <|Banana->.33, Apple->.66|>, and a sorted frequency list for my sample text, <|Apple->.4, Banana->.6|>. Because Banana moved down one place in my lists, I associate "-1" with "Banana", and because Apple moved up one place in my lists, I associate "1" with Apple. In the end, I get <|Banana->-1, Apple->1|>. Because Apple has a higher movement score, Apple is considered to be more relevant.
Of course, using a sample text necessitated that I first find some standard reference sample text appropriate for the genre. I used random passages from other Harry Potter books for my sample text. You can find candidates for sample texts in ExampleData. I used a union of Alice in Wonderland, Don Quixote, and Beowulf for my other projects.
Below I present the Word Cloud whose word weights are the ranking score. 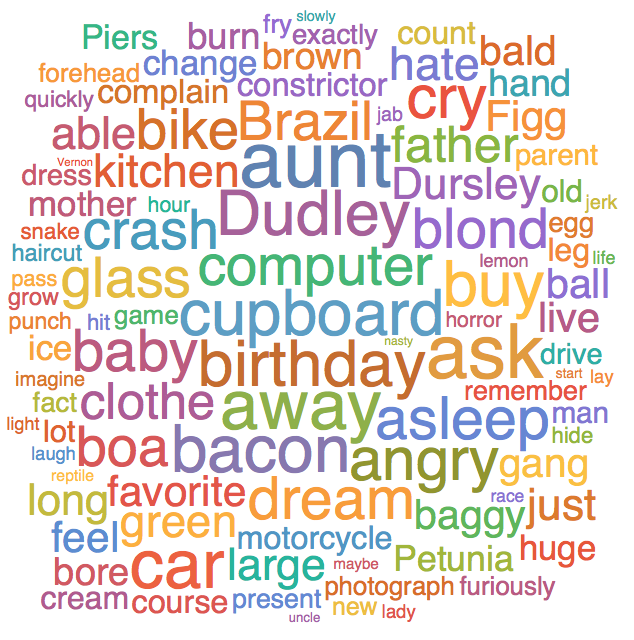
It is a slight improvement, in that Harry Potter is removed as not particularly mentioned in this passage compared to other passages in Harry Potter, but it is a far cry from providing useful plot relevant details.
My last shot at standard Frequency Analysis is Frequency Analysis against a General Word Frequency Table. Lucky for me, Mathematica comes with WordFrequencyData[ ] which can simply look up how often a word is used generally.
This time I use coefficient scores instead of ranking scores, where the relevance score is calculated by dividing out the frequency of a word in the corpus and the frequency of its use in general.

Not particularly an improvement. Really this method works best when we have a very large corpus, and one chapter of Harry Potter is quite small. Additionally, this method has trouble dealing with proper nouns, as looking up their frequency often doesn't return anything.
So what are we to do? Is there a simple way to distinguish between jargon and plot relevant keywords?
Well, we can look at Tf-Idf analysis, which can be successful in underweighting jargon. Tf-Idf is a very common document search function, where the term-frequency and inverse-document frequency are multiplied to give a relevancy score. Here's how it works:
counter[term2_, corp2_] :=
Count[MemberQ[TextWords[#], term2] & /@ corp2, True]
idf[term_, corp_] :=
Log10[Divide[Length[corp], counter[term, corp]]] // N
First we have the idf term. Inverse-Document Frequency is meant to measure how much information a word contains. It's formula is Log_10[N/d] where "N" is the total number of documents in the corpus, and "d" is the number of documents that a term appears in.
idf["example", {"This is an example. Apple Apple.",
"This is another example. Apple Apple Apple Apple.",
"This is yet another example. Banana Banana Banana Banana"}]
0.
idf["Apple", {"This is an example. Apple Apple.",
"This is another example. Apple Apple Apple Apple.",
"This is yet another example. Banana Banana Banana Banana"}]
0.176091
idf["Banana", {"This is an example. Apple Apple.",
"This is another example. Apple Apple Apple Apple.",
"This is yet another example. Banana Banana Banana Banana"}]
0.477121
The Idf score for "example" is zero, because it appears in every document of our corpus. The Idf score for "banana" is higher than that of "apple" because apple appears more frequently than banana across documents.
We then multiple Idf by Tf, or Term Frequency, shown here:
tfd[{term3_, doc_}] :=
Times[WordCount[doc], WordFrequency[doc, term3]]
tfc[term4_, corp4_] := Map[tfd, Tuples[{{term4}, corp4}]]
The term frequency just counts how many times a word appears in a document. tfd is calling term frequency on a document, which will output a number, while tfc is calling term frequency on a corpus, which will output a list of numbers, one number for each document in the corpus.
So finally, we have Tf-Idf, shown here:
tfidf[{word_, corp4_}] :=
Sort[AssociationThread[
corp4 -> Times[idf[word, corp4], tfc[word, corp4] ]], Greater]
Calling Tf-Idf on a word and a corpus will result in a list of documents in the corpus sorted by relevancy. I should say that this is not really a true Tf-Idf function, as it can only take one word, but for this project I only needed it to work with one word searches. Typically Tf-Idf can take in search phrases, which it then breaks down into individual terms.
But this is still not what we want. In fact, it is exactly the opposite of what we want. Tf-Idf takes in a word, and spits out a sorted list of documents, but we want a function that takes in a corpus, and spits out a sorted list of words. Can we construct a reverse tTf-Idf function that preserves the good qualities of a Tf-Idf search?
We can certainly try.
I introduce, reverse Tf-Idf score.
revtfidf[inputcorp_] :=
With[{nonstop =
Flatten[DeleteDuplicates /@ StemCorpus /@ inputcorp]},
AssociationThread[
nonstop -> (Sort[tfidf[{#1, inputcorp}], Greater] &) /@ nonstop]]
revtfidffvalues[inputcorp_] :=
With[{nonstop =
StringTrim[
Flatten[DeleteDuplicates /@ StringSplit /@ inputcorp], ("." |
"," | ";" | ":" | "(" | ")" | "[" | "]" | "'" | "\"" | "'")]},
Sort[AssociationThread[
nonstop -> (Total[tfidf[{#1, inputcorp}]] &) /@ nonstop],
Greater]]
StemCorpus[x_] :=
Join[DeleteStopwords[
DeleteCases[
Map[ToString, (First[Flatten[WordData[#, "BaseForm"]]] & /@
DeleteCases[(TextCases[x, "Word"]),
Alternatives @@ (TextCases[x,
"ProperNoun"])])], ("NotAvailable" |
"First[{}]")]], (TextCases[x, "ProperNoun"])]
It's a lot, but the concept is simple. We deconjugate our corpus, then run Tf-Idf on every deconjugated non-stop word, then associate the sum of the scores to the word. Here, we use the idf portion to weigh down jargon, and weigh up words used in specific sections.
Here is a word cloud of our chapter of Harry Potter, split by setting changes, weighted by reverse Tf-Idf scores. See if you can guess what the main event of the chapter is.

If you guessed that this is the chapter where Harry Potter talks to a snake at the zoo, then vanishes the glass letting the snake escape, then you are correct! As you can see, reverse Tf-Idf is much better at finding document relevant keywords than our other methods. It's particularly good at finding major plot points in books. Below, I passed 2 chapters from the beginning of Harry Potter and the Sorcerer's Stone, 2 chapters from the middle, and 2 chapters from the end to our reverse Tf-Idf calculator, and set the results to a Word Cloud. 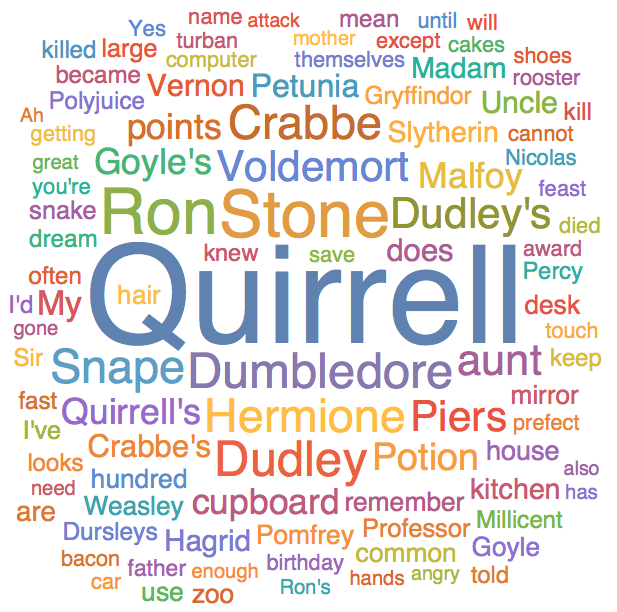
Our Tf-Idf has successfully detected that Professor Quirrell is a major plot point in Harry Potter. This is accurate, as Quirrell (Spoiler Alert) is revealed to be hiding Voldemort behind his Turban!
I will stop here for now, but there are many ways that this function can be improved. Off the top of my head I can think of a coreference function to catch indirect references, or a noun phrase version which can catch important phrases as well as words. I have applied this function to a selection of other documents, mostly legal documents, but I thought it would be more engaging to dive into a more familiar work.
Thank you for your time!
-Justin Shin


