My Summer School project was to implement the image style transfer algorithm presented in https://arxiv.org/pdf/1603.08155v1.pdf. Style transfer is a process which takes a content image and a style image as inputs and produces a third image, featuring the content of the first with the graphical style (textures, lines, colors) of the second. As suitably said, a picture (produced by my implementation) is worth a thousand words:
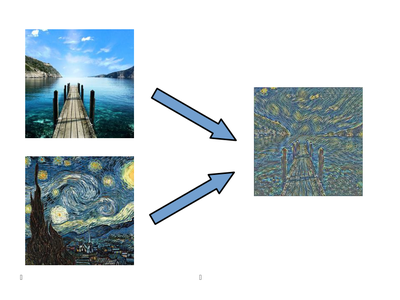
The result is obtained by training a deep convolutional neural network which takes the content image as input and produces the style-transfered one for a particular fixed style. After the training, the style transfer operation can thus be performed with a single forward pass in the net. The style transfer "magic" is encoded in the loss function, obtained by using a pre-trained network for image classification (in this case the 16-layer VGG16 deep network http://www.robots.ox.ac.uk/~vgg/research/very_deep/). The loss function is made made a weighted sum of two components: the first penalizes for differences between the content of the output and the content input, while the second for differences in style between the output and the style input. Both these informations are obtained by feeding the output, content and style images into the VGG16 and extracting its high-level feature representation from various hidden layers (check the paper for details). In addition, total variation regularization (https://en.wikipedia.org/wiki/Total_variation_denoising) is used for smoothing possible harsh artifacts in the final output. Summing up, the process can by summarized in the following sketch:
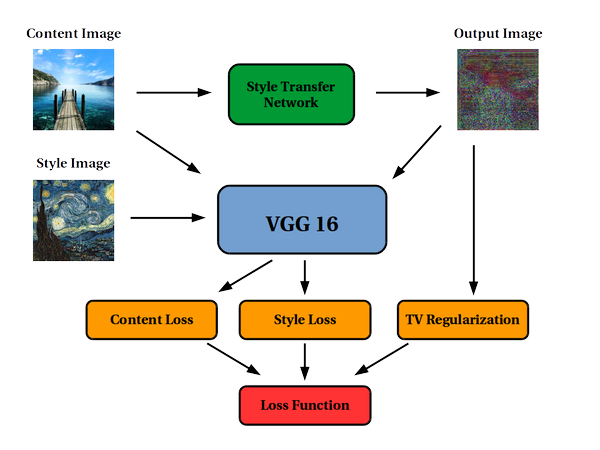
The project was carried out with the (soon to be released) new Mathematica 11. However, the new Mathematica neural network framework does not support the definition of a custom, "non-conventional" loss function as the one described above, and so the project had to be carried out using the MXNetLink package, a lower-level Wolfram Language interface for the MXNet framework (https://github.com/dmlc/mxnet). Here is an MXNetLink code snippet for a single residual block of the style transfer net, featuring convolutional, batch normalization and ReLU activation layers:
residualBlock[inputsymbol_] :=
Block[{convolutional1,convolutional2,batch1,batch2,relu},
convolutional1 = MX`Convolution["kernel"->{3,3},"num_filter"->128,"pad"->{1,1},"stride"->{1,1},"data"->inputsymbol];
batch1 = MX`BatchNorm["data"->convolutional1];
relu = MX`Activation["act_type"->"relu","data"->batch1];
convolutional2 = MX`Convolution["kernel"->{3,3},"num_filter"->128,"pad"->{1,1},"stride"->{1,1},"data"->relu];
batch2 = MX`BatchNorm["data"->convolutional2];
inputsymbol + batch2
]
For performance purposes all the modules in the above sketch have been implemented in a single, composite MXNet network, thus featuring the style transfer network, the VGG and the loss layers tied together. Since only a subset of the VGG network was needed, some parts of the network have been chopped out. Also, three chopped copies were produced, each for a single image of the above sketch. Some parts of the chopping and linking operations was not possible even in MXNetLink, and had to be performed by tweaking the even-lower-level JSON representations of the networks (but still in Mathematica). For example, the following function chops off all the layers coming after a given layer in an MXNet symbol:
netTrim[mxNetSymbol_,layerName_String] :=
Block[{jsonForm,position,newNodes,newArgNodes,newHeads},
jsonForm = MXSymbolToJSON[mxNetSymbol];
position = First@Flatten@Position[#["name"]&/@jsonForm["nodes"],layerName];
newNodes = jsonForm["nodes"][[;;position]];
newArgNodes = Select[jsonForm["arg_nodes"],(#<=position)&];
newHeads = Select[jsonForm["heads"],(#[[1]]<=position)&];
MXSymbolFromJSON[<|"nodes"->newNodes,"arg_nodes"->newArgNodes,"heads"->newHeads|>]
]
After building the full system the training can finally be performed. Following the original paper, the MS COCO database was used for the training data, consisting of more than 80,000 images (http://mscoco.org/dataset/#download). Two different different images, namely Van Gogh's "Starry Night" and a pencil freehand drawing were chosen as benchmark styles. An example of a training loop running for two epochs over the MS COCO database, whose image paths are accessed from the list called "names":
Do[
Do[
nextInput = {ImageData[FastImageImport[names[[i]]],"Byte",Interleaving->False]};
NDArraySet[executorFullNet["ArgumentArrays","inputimg"],nextInput];
MXExecutorForward[executorFullNet,True];
MXExecutorBackward[executorFullNet,{ndOne,ndZero}];
RunOptimizerStep[optimizer];
If[Mod[i,100]===0,Print["epoch: "<>ToString[epoch]<>", image: "<>ToString[i]]];,
{i,Length[names]}
];,
{epoch,2}]
The symbols ndOne and ndZero are constant NDArray instances of ones and zeroes needed to start the back-propagation properly. The trainings for the benchmark styles ran overnight on two different GeForce GTX TITAN X GPUs. After the trainings, the two networks could successfully perform style transfer on any image in a few seconds on an ordinary laptop CPU.
Time for some results (original, "Starry Night" transfer, freehand transfer):



According to personal taste, the relative weights of the content, style and TV regularization losses can be fine tuned for a given style (for example the "Starry Night" transfer net could get benefit from giving more emphasis on the content).


