When trying to build a news aggregator, I had a problem of finding the category names of news articles, since different websites are using different tags for their content. So, it is very difficult to find them on the webpage and align them. For solving this problem, I have used machine learning methods to build a classifier that automatically recognizes the category of the news article. It receives the URL of the article and gives the category name as an output. The structure of the project is presented below.
- Creating the Training Set and the Test Set
- Training the Classifier with Different Methods and Testing
- Creating a Function that Extracts the Body of the Article
- Retraining the Classifier with the Lists of Exact Bodies of the Articles
- Creating the Form
Creating the Training Set and the Test Set
In order to make the program recognize the category of an article, I needed to have a list of articles on which the program would train. So, I first used the 'Import' function on the links of politics and sport categories of several news websites and got their hyperlinks. These hyperlinks included not only the ones of exact articles, but also those of different subsections of the webpage. Since the URLs of the articles included keywords that others did not have, I could check the presence of the keyword in the hyperlinks and could take the ones that had the keyword in them. The following code is an example of the described filtering done on the list of hyperlinks imported from theweek.com ("articles" is the keyword present in the hyperlinks of the articles).
politicsList = Cases[URLlist, a_ /; Part[StringSplit[a, "/"], 4] == "articles"];
After having the links of the articles, I imported them and put in two lists of the categories of politics and sport. I did the same steps for creating another two test lists.
Training the Classifier with Different Methods and Testing
When I had the needed sets, I started training the classifier and testing it; however, its accuracy was very low. I tried training with different methods, such as Markov method and NaiveBayes method, but none of them worked well.
Then, I noticed that the lists of the articles I had imported included other content from the website besides the exact article texts; so, I needed to have a function that would take the body parts of the articles.
Creating a Function that Extracts the Body of the Article
Since the articles were separated from ads and other useless content with multiline whitespace characters, I used a moving average of the percentage of whitespace characters over a 600-character window to estimate what the main body of the article was. After looking at a few plots, I picked a threshold and used this technique on all the articles. The plot of an example article is presented below.
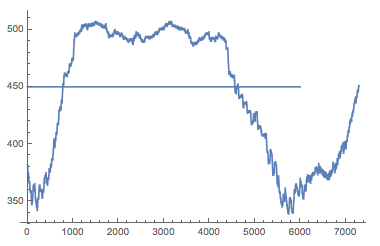
The code of the function that extracts the body of the article is the following.
getBody[testTexts_] := Module[{TestCharList, firstcut, lastcut},
TestCharList = Map[
If[
StringLength[#] > 600,
MovingMap[Count[False], StringMatchQ[Characters[#], WhitespaceCharacter], 600],
ConstantArray[600, StringLength[#]]
] &,
testTexts
];
firstcut = Map[First[FirstPosition[#, x_ /; x > 450, {1}]] &, TestCharList];
lastcut = MapThread[#1 + First[FirstPosition[Drop[#2, #1], x_ /; x < 450, {Length[#2] - #1}]] &,
{firstcut, TestCharList}];
MapThread[StringTake[#1, {#2, #3}] &, {testTexts, firstcut, lastcut}]
]
Retraining the Classifier with the Lists of Exact Bodies of the Articles
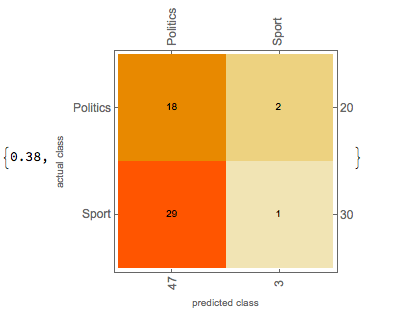
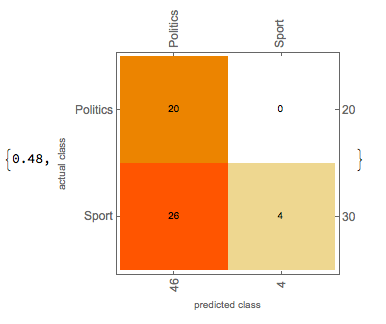
After having the getBody function I applied it on training and testing sets. Again, I trained the classifier both with Markov method and with NaiveBayes method. The getBody function helped a lot and the accuracy of the classifier grew significantly. The results of the classifiers of the two methods are shown below. 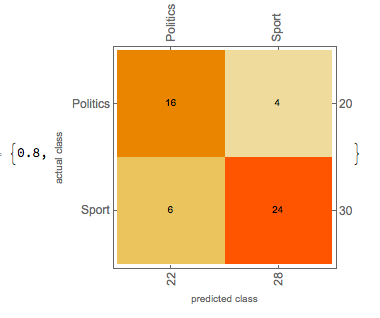
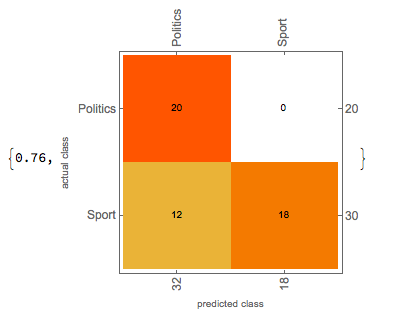
Creating the Form
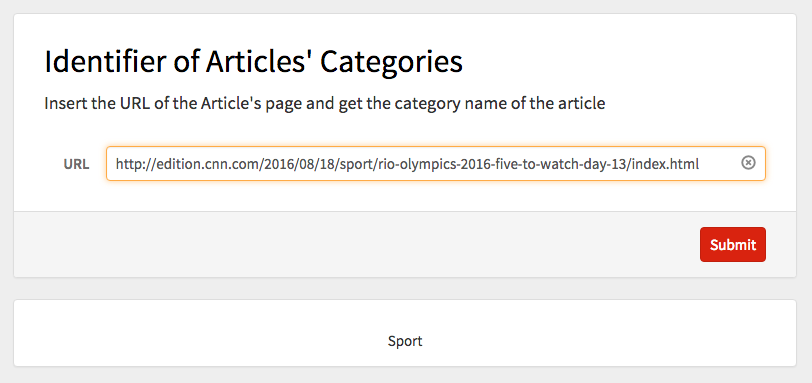
The classifier that used NaiveBayes method had higher accuracy, so I used it when creating the form. The latter includes the title of the project, the description of the program, and a window for inserting the URL of the article. The program takes the URL given by the user, imports the text of the webpage, applies getBody function on it, puts in the classifier, and gives the name of the category right in the page of the form. At the end, I CloudDeployed the form.
CloudDeploy[FormPage["URL" -> "URL", First[catIdentifyNg[getBody[{Import[#URL, "Plaintext"]}]]] &,
AppearanceRules -> <| "Title" -> "Identifier of Articles' Categories",
"Description" -> "Insert the URL of the Article's page and get the category name of the article"|>]]
You can access the form by clicking here.
 Attachments:
Attachments:


