Dear Mengyi,
I have just completed training your network on a data set that is about 10 times larger than yours (and might have a better overall quality, because I did not use Wikipedia anymore).
This is the network I used:
net4 = NetChain[{
embeddingLayer,
ElementwiseLayer[Tanh],
LongShortTermMemoryLayer[100],
NetBidirectionalOperator[{LongShortTermMemoryLayer[40],
GatedRecurrentLayer[40]}],
NetBidirectionalOperator[{GatedRecurrentLayer[30],
LongShortTermMemoryLayer[30]}],
LongShortTermMemoryLayer[30],
NetBidirectionalOperator[{LongShortTermMemoryLayer[10],
GatedRecurrentLayer[10]}],
LongShortTermMemoryLayer[10],
NetMapOperator[LinearLayer[3]],
SoftmaxLayer["Input" -> {"Varying", 3}]},
"Output" -> NetDecoder[{"Class", {"a", "b", "c"}}]
];
And here are the results:
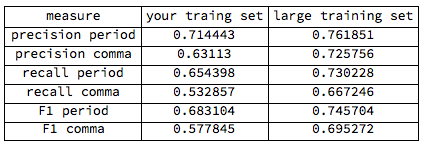
It turns out that all values got somewhat better, especially the comma values gained.
My actual corpus is at least 5-10 times larger than what I have been using, but I will need another GPU setup and/or other tricks to be able to run it on the entire corpus (10000 books of Gutenberg + other texts).
I am happy to make the trained network (163 MB) available upon request. If you are outside Germany, you can also easily download the Gutenberg dump.
Cheers,
Marco


