Project on GitHub: https://github.com/lne817/WSS-17
Patent Claims Analytics
Patent claims are formally worded statements within a patent application or patent, which clearly explain the invention, and define the scope of the invention. In order to enforce the full scope of a patent, it is imperative for inventors, firms, and companies to make sure that the patent's scope is not covered by prior publications and competitors' patents (referred to as "prior art") available in the public domain. For this reason, most companies with a patent portfolio spend a substantial amount of resources in searching for potentially troubling prior art. Therefore, this project is a first step to optimize this process and offers an analytic tool to better categorize and analyze the relationship between a granted patent with other patents by clustering them based on claim term frequency.
Constructing Patent Analysis Dataset
Patent grant full text (without images) from USPTO Bulk Data Storage System (https://bulkdata.uspto.gov) are downloaded as zip files and extracted into xml files. Each patent is parsed by separating with headings of xml files and parsed. For each patent, patent information including the patent number, title, number of claims, claim text, three most frequently used words is extracted.
parsePatent[files_, numberOfPatents: (n_?IntegerQ /; Positive[n])|All, streamPosition_ : 0] :=
Module[
{patentsStream, patent},
patentsStream = OpenRead[files];
SetStreamPosition[patentsStream, streamPosition];
Do[readPatent[Find[patentsStream, "<doc-number>",
RecordSeparators -> {{"<?xml version=\"1.0\" encoding=\"UTF-8\"?>"}, {"</us-patent-grant>"}}]], numberOfPatents];
Close[patentsStream];
]
readPatent[patent_] :=
Module[
{patentStream, patentInfoList, patentInfoRaw, patentInfo, claimsRaw, claims, words},
patentStream = StringToStream[patent];
patentInfoList = {"<doc-number>", "<invention-title id=", "<number-of-claims>"};
patentInfoRaw = Find[patentStream, #] & /@ patentInfoList;
patentInfo = StringReplace[patentInfoRaw, Shortest["<"~~__~~">"] -> ""];
claimsRaw = FindList[patentStream, "<claim-text>"];
claims = StringReplace[StringJoin[claimsRaw], {Shortest["<"~~__~~">"] -> " ", StringExpression[a:NumberString,"."] -> StringExpression[ToExpression[a],":"]}];
AssociateTo[claimText, {patentInfo[[1]] -> claims}];
words = DeleteCases[base[StringDelete[DeleteStopwords[ToLowerCase[StringJoin[claims, " ", patentInfo[[2]]]]], Alternatives@@dropList]], Alternatives@@blackList];
AppendTo[patentAnalysisMatrix,
<|patentInfo[[1]] -> <|"Title" -> patentInfo[[2]], "# Claims" -> patentInfo[[3]], "Words" -> Select[Keys[WordCounts[words]], LetterQ][[1;;3]]|>|>];
(*Print[WordCloud[words]]*)
Close[patentStream];
]
The most frequently used words are cleaned with separate lists of words to be dropped for better characterizing each patent.
Clear@base;
base[w_] :=
With[{tmp = WordData[w, "BaseForm", "List"]},
If[(Head[tmp] === Missing) || tmp === {}, w, tmp[[1]]]];
SetAttributes[base, Listable];
blackList = {"doi", "ed", "isbn", "pmid"};
dropList =
{"wherein", "claim", "said", "-", "&#", "x2018", "x2019", "x201c",
"x201d", ";", "/", "'", ".",
StringExpression[" ", NumberString, " "],
StringExpression[" ", NumberString, ", "]};
Then, we obtained a dataset with three most frequently used words in each patent for further analyses. 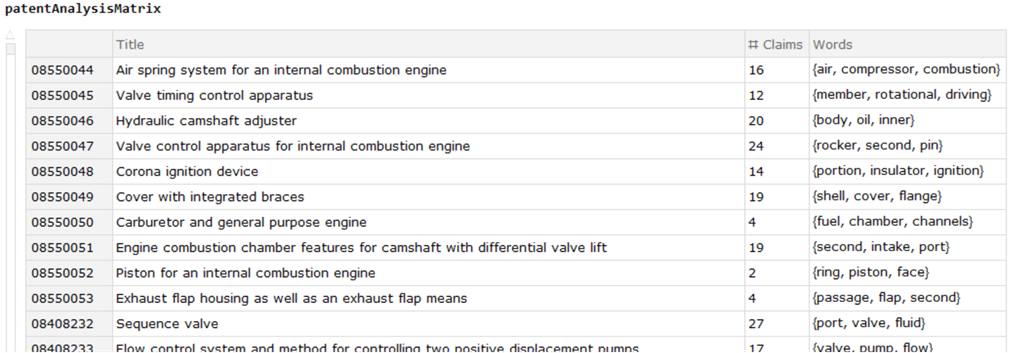
Clustering with Vector Representations of Words with NetModel, GloVe
GloVe is used to turn three most frequently used words in claim text into [3 x 100]-dimensional vector representations, allowing us to group them together with semantically similar data in a vector space.
net = NetModel[
"GloVe 100-Dimensional Word Vectors Trained on Wikipedia and Gigaword-5 Data"]
wordToVec = net /@ Normal[patentAnalysisMatrix[All, "Words"]];
Dimensions /@ wordToVec // Tally (* Same dimension checked *)
c = ClusterClassify[Values[wordToVec]]
Time-Series Data using USPTO's Classification Systems
Patents are classified by the USPTO into patent classes and subclasses based on the subject matter of the patent claims. Thus, we can use patent class/subclass information to group or cluster patents that have common claimed subject matter. Here, instead of the USTPO's patent classification systems which have large numbers of categories and largely designed for administrative purposes, thus limiting their value for research purposes, the National Bureau of Economic Research (NBER) categories, which Hall, Jaffe, and Trajtenberg (2001) developed by aggregating USPC classes into six economically relevant technology categories (and 37 sub-categories) and classified granted patents accordingly, were applied to create the times series data.
The number of patent grants in Computers & Communication has been greatly increased, suggesting that they are more probable to be invalidated and the applicants would need more than mere implementation for their inventions to be patent eligible. 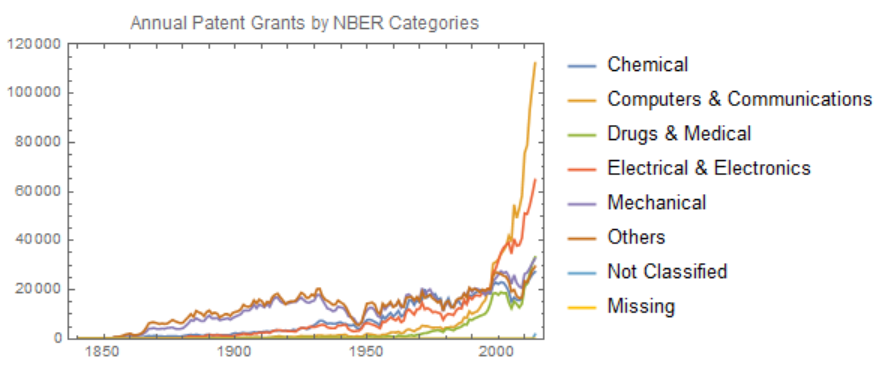
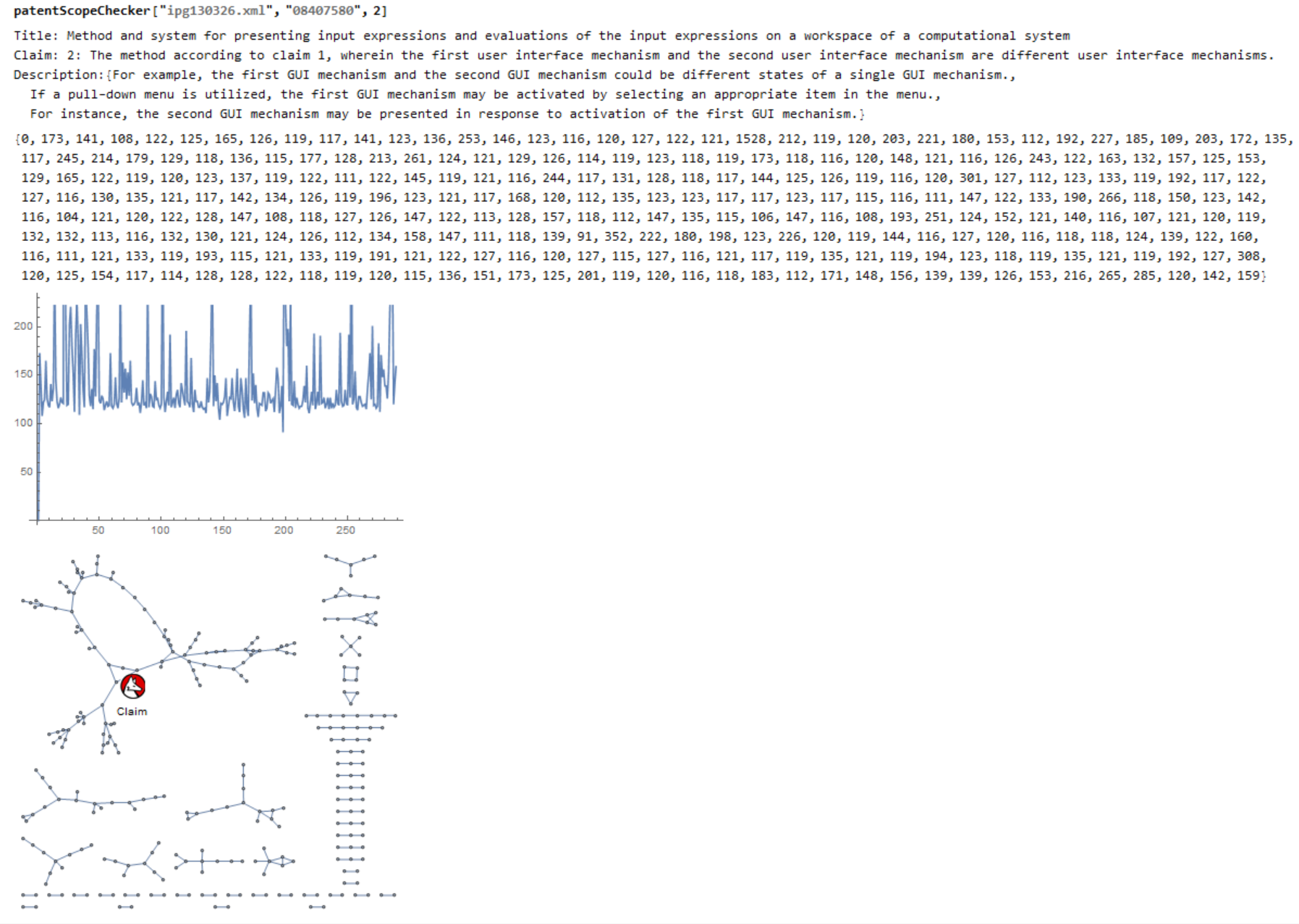
Scope Checker
Lastly, we often need to explore the description (or specification) part of patent documents to clarify the scope and details which are claimed in the patent. There is also a requirement for a patent application called "Sufficiency of Disclosure" which means that it should contain sufficient information or details of patent claims so that others can reproduce. Therefore, by constructing the distance matrix between the claim sentence and description sentences, we would be able to find the most similar and related text with a given claim sentence.
patentScopeChecker[files_, patentNum_, claimNum_] :=
Module[
{patentsStream, patent, patentTitleRaw, patentTitle, patentText, patentTextRaw, patentSpec, claimsRaw, claims},
patentsStream = OpenRead[files];
patent =
Find[patentsStream, patentNum, RecordSeparators -> {{"<?xml version=\"1.0\" \ encoding=\"UTF-8\"?>"}, {"</us-patent-grant>"}}];
patentTitleRaw = StringCases[patent, Shortest["<invention-title id=" ~~ __ ~~ "</invention-title>"]][[1]];
patentTitle = StringReplace[patentTitleRaw, Shortest["<" ~~ __ ~~ ">"] -> ""];
patentSpec = StringReplace[StringCases[patent, Shortest["<description id=" ~~ __ ~~ "</description>"]], "\n" -> " "];
patentTextRaw = StringReplace[patentSpec, {Shortest["<" ~~ __ ~~ ">"] -> "", StringExpression[NumberString, "."] -> ""}];
patentText = TextSentences[StringJoin[patentTextRaw]];
claimsRaw = StringReplace[StringCases[patent, Shortest["<claims id=" ~~ __ ~~ "</claims>"]], "\n" -> " "];
claims = Flatten[TextSentences[StringTrim[StringReplace[claimsRaw,
{Shortest["<" ~~ __ ~~ ">"] -> "", StringExpression[a : NumberString, "."] -> StringExpression[ToExpression[a], ":"]}]]]];
Print["Title: ", patentTitle, "\nClaim: ", claims[[claimNum]], "\nDescription:", Nearest[patentText, claims[[claimNum]], 3]];
PrependTo[patentText, claims[[claimNum]]];
distanceToText = DistanceMatrix[patentText][[1]];
Print[distanceToText] // MatrixForm;
Print[ListLinePlot[distanceToText]];
Print[NearestNeighborGraph[patentText, VertexLabels -> {patentText[[1]] -> "Claim"}]];
Close[patentsStream];
]
Searching for details of the claim 2 in US8407580, one of the patents by Stephen Wolfram, demonstrates that the Scope Checker successfully detects the relevant details in the description/specification part of a patent document for a given claim text. These sentences correspond to the three smallest values in the DistanceMatrix between the claim text and the description text, and NearestNeighborMatrix demonstrates how the claim text is related to the description text.