Abstract
The problem of scene parsing is a difficult one. Despite this complexity, the ability to correctly analyse the environment is critical for the development of autonomous systems such as self-driving cars. Here I describe the procedure to develop a model for semantically segmenting urban street scenes. The aim of my project is to implement a deep neural network in the Wolfram Language which can perform a pixel-wise semantic segmentation of the images contained in the Cityscapes dataset. The dataset used is a challenging one consisting of a comprehensive set of images from various kinds of urban settings.
Note:
I have tried to write this post for 2 kinds of readers - those who want a high level overview of what this project does, and those who want to implement a similar model on their own and are looking for guidelines. To cater to both these kinds of readers, I have included as little code in this post as possible, but have referenced the relevant files on my GitHub repo as and when required. So if you want to see how I did any of the things I've shown here, just scroll around and you will find a link to the relevant file on GitHub.
Project
Neural Netwok Design Overview
Here let's set some ground rules for the design of our network. It doesn't have to be very detailed, but we must know what we are doing since the preprocessing of our data will depend upon the network design.
On the Cityscapes benchmarks page, there is a list of papers which have achieved a high accuracy on this dataset. As of this writing, the paper with the highest accuracy (with accompanying code) is PSPNet. It uses the 101-layer pretrained ResNet network, appended with a custom pyramid pooling scheme.
Data Preparation
We must first prepare the data to be fed into the neural network of our design. We will be passing in images of urban scenes into the network. However, they are too large (2048 x 1024 pixels) to be processed easily. PSPNet crops the images to ~720 pixels for this reason. Since we will be working under limited time and a modest GPU, we shall crop the images to 256 x 256.
There is a problem with this, however. In an image of 2048 x 1024, a crop of 256 x 256 classes will contain a very small subset of the image, which will in turn contain very few of the classes we want to classify. So our network will not be able to see many classes at once, in the same image. To address this issue, let's resize the images to 1/4 of the original resolution (that is, to 1024 x 512 pixels).

The cropped images look like this:

We will feed in the ImageData of the input images and get the output mask as an array (which will be the ImageData of the output mask). The masks are also resized and cropped in the same way. The code for resizing and cropping the input images and masks is in the file GetData.nb on my GitHub repo.
Since we will be using the pretrained weights of ResNet, we must also include the preprocessing that ResNet uses. It subtracts the mean of all images in its dataset from each image before feeding the image into the network. We must extract this mean image, as shown below.
Neural Network Design Details
This is what the entire ResNet looks like in Mathematica:
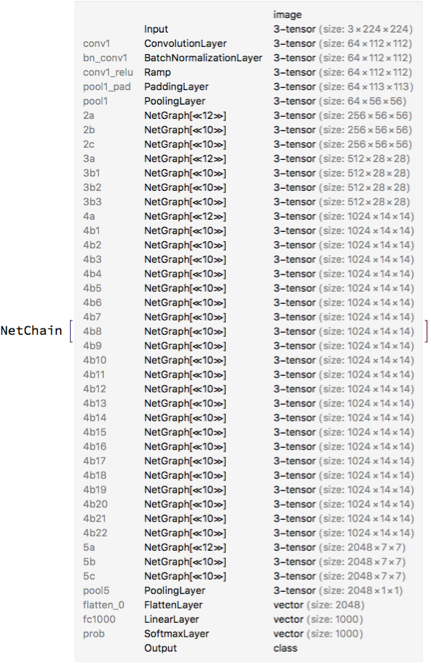
Phew, that's deep! By the way,
meanImg = Normal[NetExtract[resnet, "Input"]]["MeanImage"]
gives us the mean image of ResNet, which we'll subtract from each input image before sending it into the network (as I'd said above).
As the PSPNet paper says, I will chop off the last few layers from layer 5a onwards. Then, I will add a pyramid pooling module which is a series of pooling layers of various sizes. The PSPNet authors have upsampled the images a bit too much for my taste (this could be because they train on the coarse annotations of the Cityscapes dataset). Since we want to train on the fine annotations, I replaced some of the upsampling by deconvolutions (which is basically a learned upsampling). The entire design code of the neural network is in the file network.nb on my GitHub repo.
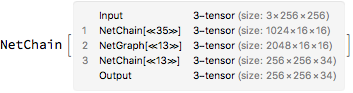
The final network isn't much to look at because the entire ResNet, the pyramid pooling and other layers have each been compressed to a single line (a NetGraph or a NetChain).
Train the network
Now let's begin the most fun part of the project - actually training the neural network. For this, I am using an AWS instance with the NVIDIA Tesla K80 GPU. I uploaded all my files onto the remote machine and have written a script to train the network. This script can be found as (surprise!) script.wl on my GitHub repo.
A convenient way I like to view my training (on a MacBook) is as such:
- Open 2 terminal windows and log into the AWS instance on both
- Set them up in OS X Split View
- Run the training script in a
tmux session on one, and a watch nvidia-smi on the other
- This shows us the training progress on one side, and the GPU memory usage on the other.
Remember that a batch size must be chosen such that it is the largest number of files which can comfortably fit on the GPU/CPU. Here is a screenshot of the network training:
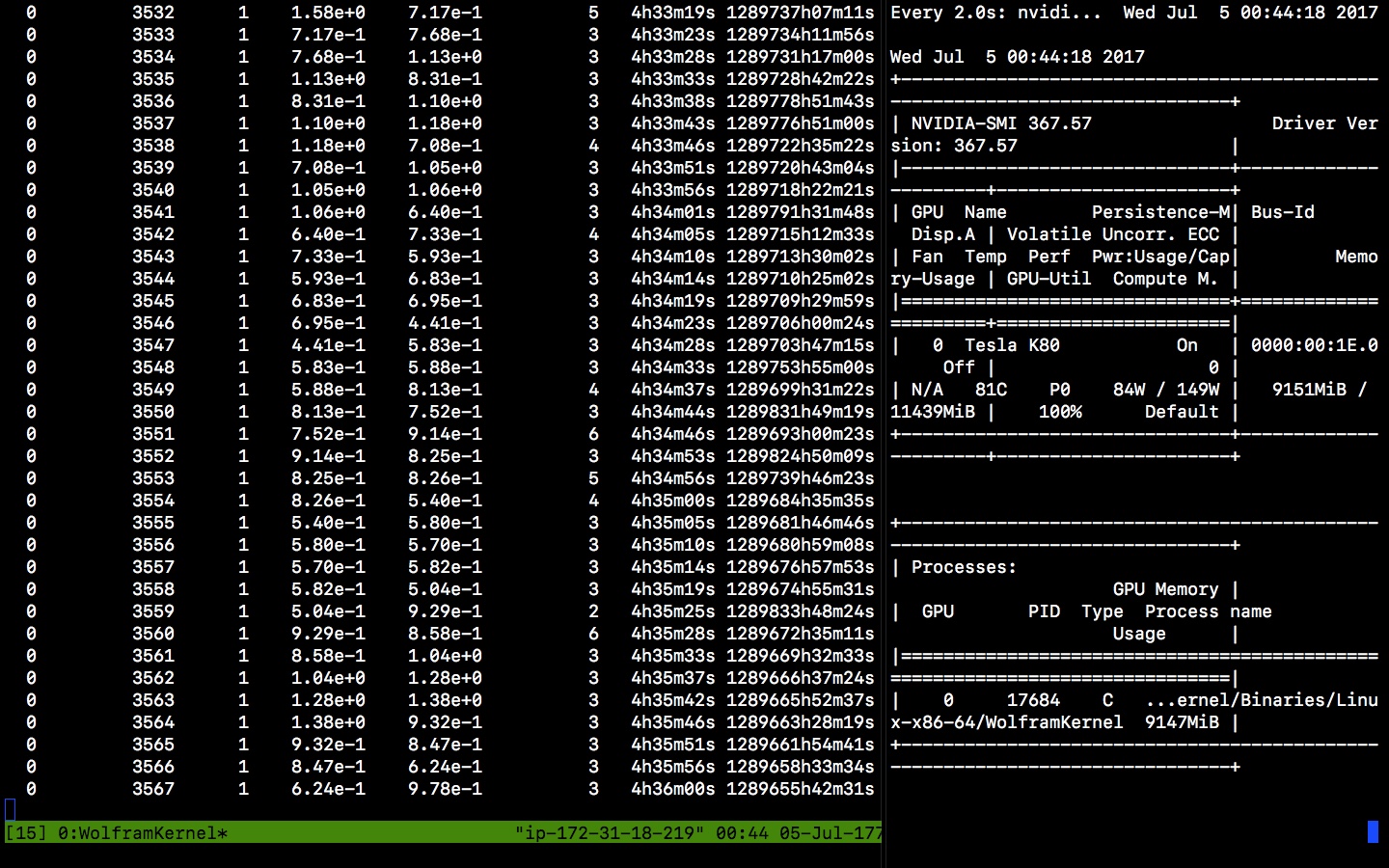
We can see the training loss, time spent, etc on the left, and GPU information on the right.
Here is the output of watch nvidia-smi a bit more clearly:
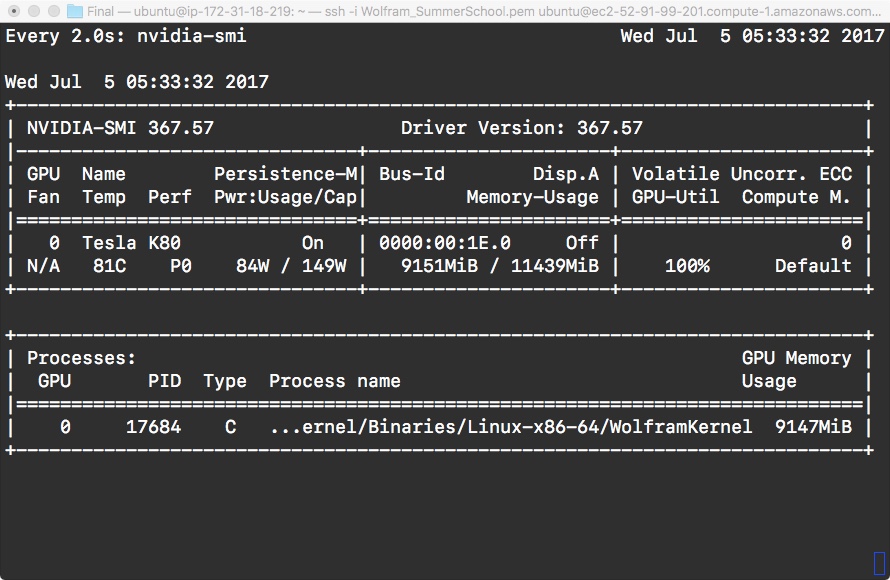
When the training error is reasonable or when you are bored out of your mind waiting for the network to finish training, download the network to your local machine and test it on images!
Test Performance
For my test file, see test performance.nb on GitHub.
I have organised the paths on my machine such that I can randomly pick an image to visualise it with this code:
i = RandomInteger[{1, Length @ testPics}];
input = testPics[[i]];
pixelResult = pixelPredict[net, input];
ImageCollage[
{
ArrayPlot[pixelResult, ColorRules -> colorRules],
fip @ trialFiles[[i]],
ArrayPlot[importer @ coarseMaskFiles[[i]], ColorRules -> colorRules],
ArrayPlot[importer @ maskFiles[[i]], ColorRules -> colorRules]
}
]
This is the output I get from the above piece of code:

In clockwise direction starting from top left, these images are:
- Output of my neural network
- Input image
- Fine annotation of the Cityscapes dataset
- Coarse annotation of the Cityscapes dataset
As we can see, the network output is better than the coarse annotation, but not as good as the fine annotation. Moreover, it has some difficulty detecting small or thin objects such as poles, signs, etc. I suspect this is because of the large amount of upsampling in the network. If we add more deconvolutions instead, I am confident that the accuracy will further increase.
Let's see the incorrectly classified pixels in white:

Yup, as I said, small / thin objects are not so easily spotted by this guy.
If we measure the accuracy for this image (percentage of correctly classified pixels):
(1. - Mean @ Flatten[
Unitize[pixelResult - testMasks[[i]]]
]) * 100
We get 83.6151. Hey, not too bad for a day's work!
In my GitHub repo, I have included the code to test the network on the entire test set (3,800 images). But beware! Running it on a CPU takes forever, it is much better to run it on a GPU.
References:
- Zhao, Hengshuang, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. "Pyramid Scene Parsing Network." [1612.01105] Pyramid Scene Parsing Network. CVPR (IEEE), 27 Apr. 2017. Web. 25 June 2017.
- He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep Residual Learning for Image Recognition." [1512.03385] Deep Residual Learning for Image Recognition. CVPR, 10 Dec. 2015. Web. 25 June 2017.
- Cordts, Marius, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. "The Cityscapes Dataset for Semantic Urban Scene Understanding." [1604.01685] The Cityscapes Dataset for Semantic Urban Scene Understanding. CVPR, 07 Apr. 2016. Web. 25 June 2017.


