Name Origins
Introduction
My name is Sophia Balkovski and I attended the 2017 Wolfram Summer Camp from June 25th to July 7th. At this camp, I worked on this project.
Description
The aim of this project was to be able to use machine learning to classify the country of origin of a name. The code takes in a data set of names and their corresponding countries of origin to find patterns between countries with similar names.
Click here to try it out
The Process
The dataset consisted of a list of names and a series of numbers from 0-13 describing the "strength" of the name of each particular country. of names assigned a set of weights to each name based on its popularity in each respective country. The values were processed so that when added up, the value of the name in each country would be approximately the same. This was done by dividing each value for a country by the respective total for that name, multiplying everything by 10, and rounding to the nearest one. The United States of America were excluded.
The names were put in a separate list for each country they corresponded to the number the names that corresponded to each country. So for example if the name "Lisa" had a weight of 5 for Great Britain and 3 for Italy, in the list of names for Great Britain, "Lisa" would be inputted five times and only three times in the Italy list.
Next, an association of the form "country" -> "names"` was created and put inside a classifier function. Each list of names was randomized and divided in two to create a training and test set.
The accuracy of this project is at a 61% and can still be improved. However, the accuracy is not a good way to measure the results as it only measured if the name provided by the dataset matched the country with the highest ranking.
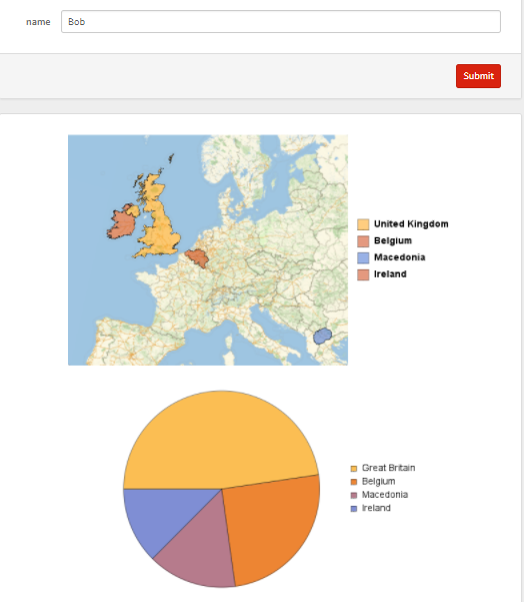
The website locates the most probable countries on a map and creates a pie chart with the probabilities that the name is from each respective country Along with that, it also returns a map with the countries the name is from and a pie chart of the countries.