What on Earth is this map? Using machine learning and data analysis to find a map's depicted region and projection
Abstract
Different geographic maps serve different purposes; they show various areas of the world with distinct projections. Knowing which part of the world a map represents in what projection is often crucial when reading a mapfor the same space can be projected in numerous ways. This project, written in the Wolfram Language with Mathematica, aims to identify the depicted region and projection of a map input as an image. The algorithm uses various methods such as image processing, machine learning and neural networks, and data analysis and to imitate the human brain in interpreting the mapit reads the labels on the map and uses the information it can obtain from the web, studies the outlines and boundaries to determine which continent the map could belong to, and compares different characteristics of the projection to reach a conclusion.
Introduction
The algorithm is divided into two parts: i) finding region depicted, and ii) determining projection used. The first part involves two different threadsone that reads the labels, and the other that analyzes the map as a whole. Once properly processed and analyzed, they each output continent and city information of the input map, respectively. Then, they are combined to output the region depicted by the map.
The second part utilizes the information gathered from the second part: when labels are read, their on-map coordinates are also recorded. The algorithm draws triangles of sets of three cities, and compares its parameters (angles, area, and distance) to real-world parameters, also supplied from the first part of the algorithm. A simple comparison allows the algorithm to conclude which one of the three parameters are conserved, and thus which category of projections the map falls into.
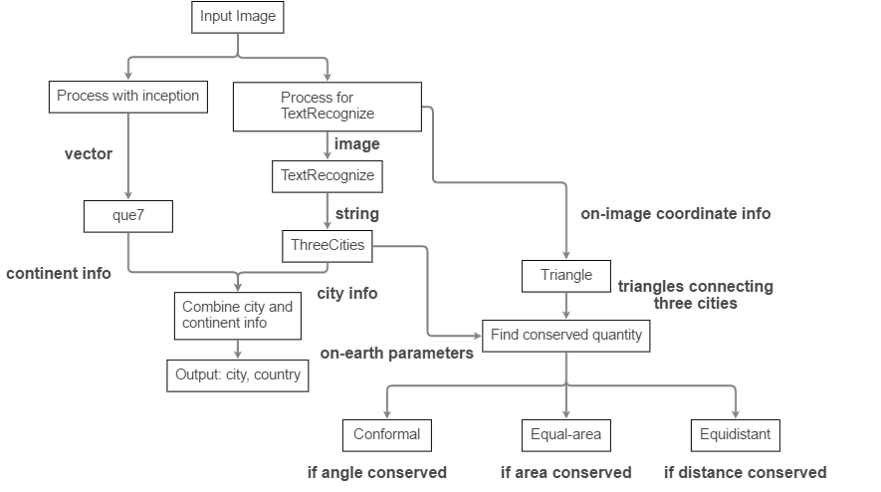
Inception and que7
Inception is a neural network developed by Google. Google uses it to interpret imagesit is able to detect, or see 2048 everyday objects, such as cars, apples, or dogs, in any given picture with a respectable accuracy. It is a series of convolution layers and batch normalization layers, followed by a number of neural network graphs. Here, I modified it to suit my needsinstead of seeing 2048 objects, I only need it to be able to distinguish between the 6 continentsAfrica, Asia, Europe, North and South America, and Oceania. I wrote a 19-layer network chain, to complement a part (first 30 layers) of inception. With the network chain, I trained the continent classifier, que7, with 9051 continental or subcontinental maps, and a validation set of 2585. With inception and que7, the algorithm is able to identify the continent of a given map of continental or subcontinental scale, distorted or rotated, with a 92.9% accuracy.
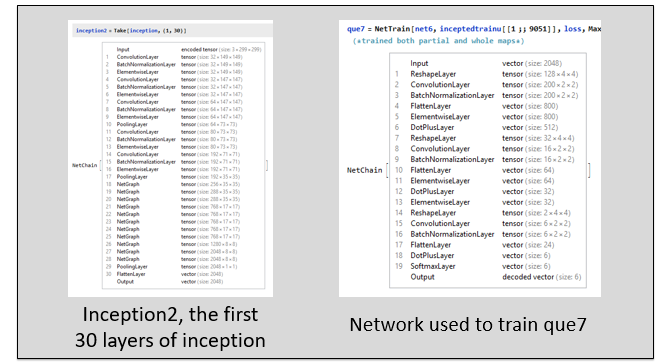
Finding depicted region
Depending on how much information is available, the algorithm outputs different amount of information. Most ideally, it outputs 3 cities, and their respective countries. If there is not enough available information, the algorithm has alternative functions that work with 1 or 2 cities as well. 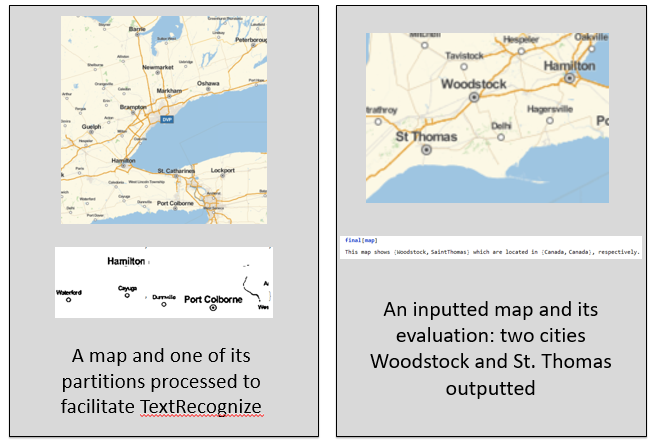
An inputted map is first "adjusted:"
adjust[x_] := Module[{w, y, z},
w = ImageResize[#, 300] & /@
Flatten[ImagePartition[x, {{150}, {50}}, {75, 25}]];
y = ImageApply[Max, #] & /@ ImageAdjust /@ w;
z = Sharpen /@ y;
Binarize /@ z]
then is run TextRecoznize with the BoundingBox parameters. An interpreter is run on the recognized text to identify cities. Using information from CityData, possible combinations of cities are tested as a function of distance, and with the help of the continent classifier, and the best one is selected and outputted.
Determining projection
From the first part of the algorithm, there is already enough information obtained to approach determining the used projection. Parameters of triangles connecting three cities are compared in pairs to determine which variable is conserved. As shown in the flowchart, conservation of angle, area, and distance gives us conformal, equal-area, and equidistant projections, respectively.
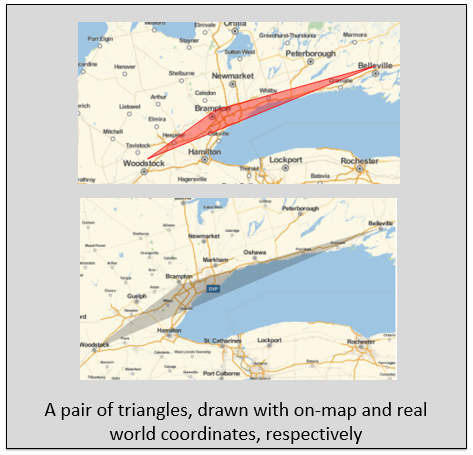
Given three or more cities, "triangles" can be drawn:
triangle[x_(*a list of cities found*), y_ (*most probable city-triples*)] :=
Module[{asc, cts, out},
asc = Association[x];
cts = y["CityTriple"];
out = Association["CityTriple" -> cts,
"Coordinates" -> asc /@ cts[[All, 2, 1]]];
out
]
and their parameters can be compared to real-world parameters:
legratio[{x_List, y_List, z_List}] :=
Module[{legone, legtwo, legthree, min},
legone = Norm[x - y];
legtwo = Norm[y - z];
legthree = Norm[z - x];
min = Min[{legone, legtwo, legthree}];
{{legone, legtwo, legthree}/min, min}
]
where real-world parameters can be obtained by replacing Norm[x-y] with GeoDistance[x,y] above. Discrepancies on each parameters can be compared, and the least discrepant quantity is determined to be conserved.
Conclusions
In the first part of the project, a combination of the machine learning and data analysis approaches proved more efficient than singular approaches. The neural networks 92.9% accuracy (over 1293 test images) complements the data analysis approach. On the other hand, in the second part, using machine learning to determine a specific projection proved almost pointless due to similarity of different projections in many parts of the world. Instead, a data analysis approach to determine which category the projection falls into seems more useful and insightful. More specific identification of the projection or improvement in processing of the map image to facilitate TextRecognize could be a good future direction in this project.
Please feel free to contact me at jmin10@jhu.edu with questions or comments. Thanks!
I would like to mention that the project was done via the Mentorships program; and to thank Giorgia Fortuna for her time in advising me, and Alison Kimball for her guidance through the system.
Updated code for this project is here.


