The Yanny/Laurel clip is the internet meme du jour, so I thought I'd take a quick look at it. If you haven't heard of it yet (what, have you been under a rock for the last five hours?), some people hear "Yanny", and some people hear "Laurel". But why? And what's the deciding factor?
The original clip repeats the phrase twice, so I simply took one of them using AudioTrim.
aud = AudioTrim[
Import["https://video.twimg.com/ext_tw_video/996218345631318016/pu/\
vid/180x320/E4YbExw0wX1ACH5v.mp4"], {Quantity[1, "Seconds"],
Quantity[1.8, "Seconds"]}]
First I decided to take a look at this clip, and compare with just the words "Yanny" and "Laurel". Thankfully WL has SpeechSynthesize built in, so it was easy to compare the spectrogram.
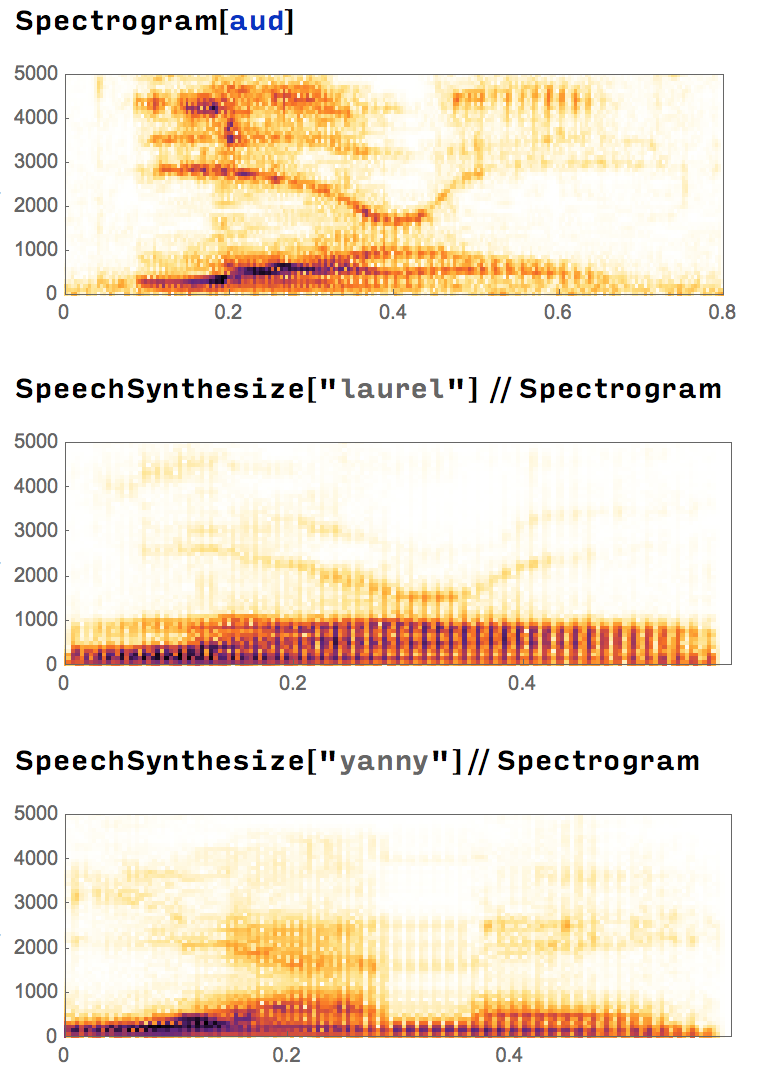
I think this is quite interesting - it looks like our original clip is much closer to "Laurel" than "Yanny".
In the New York Times article above, Twitter user @xvv mentioned that pitch shifting the clip has an impact on what you hear. A bit of playing around in a Manipulate gave me the same impression!
Manipulate[
Module[{a = AudioPitchShift[aud, x]},
Audio[a]
],
{x, 0.7, 1.3, 0.005}]
If I move the slider around, I hear "Yanny" on the left and "Laurel" on the right. If I move the slider around the middle, what I hear tends to change based on which of the two I heard previously, the result of some weird "echo" in my brain that seems to say that "a sound I heard previously is similar to the sound I'm hearing now, thus they are the same sound".
Anyway, this gave me an idea. I was wondering if it was possible to see exactly where the sound changes from Yanny to Laurel. I didn't have time to listen to every small pitch shift, as well as that "echo" influencing which sound I heard. Thankfully, computers these days are able to do all kinds of things, so I used the (quite recently added) Deep Speech 2 Neural Network to do this for me.
First initialising the network (simple as usual):
nm = NetModel["Deep Speech 2 Trained on Baidu English Data"]
First, I used a simple Manipulate to see whether the network actually hears the sound differently.
Manipulate[
MapAt[
StringJoin[#] &,
nm[AudioPitchShift[aud, x], {"TopNegativeLogLikelihoods", 5}
], {All, 1}],
{x, 0.8, 1.1, 0.1}
]
And yes, in fact it does! When pitch shifted downwards, the network hears "yeary","yearly","yeay" and so on, and when shifted upwards, it hears "laurel","loural","lourl" and the like.
Since we can plot this data, we should. The following code is a bit awkward - I hadn't even had a coffee at this point. Essentially, if the network hears a word that starts with a "y", we take it that a human would hear the word "Yanny", and if the network hears a word that starts with an "l", a human would hear the word "Laurel". I throw away other words since it doesn't appear that regular humans are hearing "mento" or something else weird.
First, we'll get the first character of the prediction and its score for every 0.001 interval of pitch shift between 0.7 and 1.3.
tbl = ParallelTable[
x -> Normal[
KeyMap[First,
Association@
NetModel["Deep Speech 2 Trained on Baidu English Data"][
AudioPitchShift[aud, x], {"TopNegativeLogLikelihoods", 1}]]],
{x, 0.7, 1.3, 0.001}]
That data is pretty easy to plot, so we do so, dropping letters that aren't "y" or "l".
ListPlot[KeyValueMap[
{#1,
KeyValueMap[
Function[{k, v}, Switch[k,
"y", {k, v},
"l", {k, -v},
_, Nothing
]],
Association@#2]}
&,
Association@tbl] /. {x_, {{l_, y_}}} -> Tooltip[{x, y}, l],
PlotRange -> All, PlotMarkers -> Automatic, Axes -> {True, False},
Frame -> {{False, False}, {True, False}},
FrameLabel -> {{"", None}, {"Pitch Shifted By", False}},
FrameTicks -> All,
PlotLabel -> "Above the line is Yanny, below the line is Laurel"]
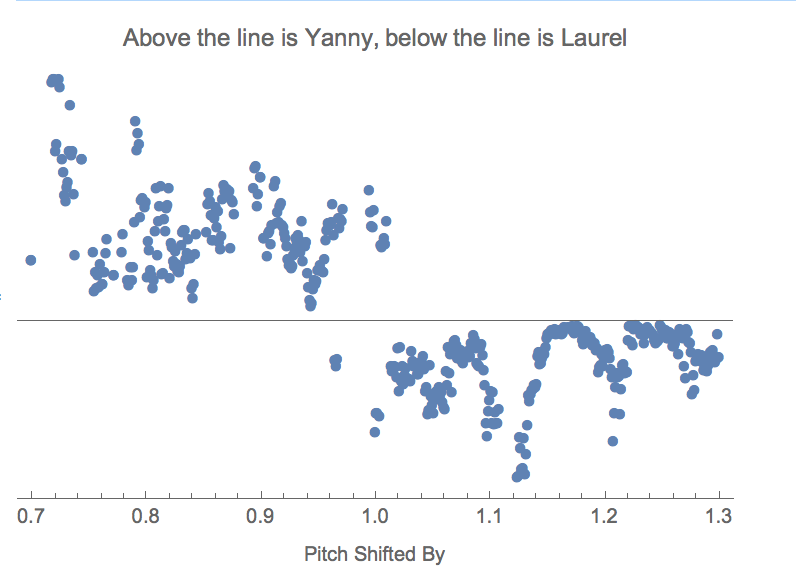
In the above image, the distance from the centre line is the uncertainty. Above the line is where the network heard "Yanny" or something like it, and below the line is where the network heard "Laurel" or something like it.
We can see that right in the centre, right at the original pitch, is where the network switches between "Yanny" and "Laurel". This indicates that only small variations in the pitch of the clip will cause regular non-computers to hear the clip differently also.
Finally, I wanted to make a small animation displaying what's happening when you pitch shift, and the impact that it has on what you (or the network) hears.
Animate[
Module[{a = AudioPitchShift[aud, x]},
GraphicsGrid[{{
Spectrogram[a, ImageSize -> Large],
Rasterize@StringJoin@nm[a]
}, {
Rasterize@StringJoin["Pitch shifted by ", ToString@x]
}}, ImageSize -> Large]
],
{x, 0.7, 1.3, 0.005}]
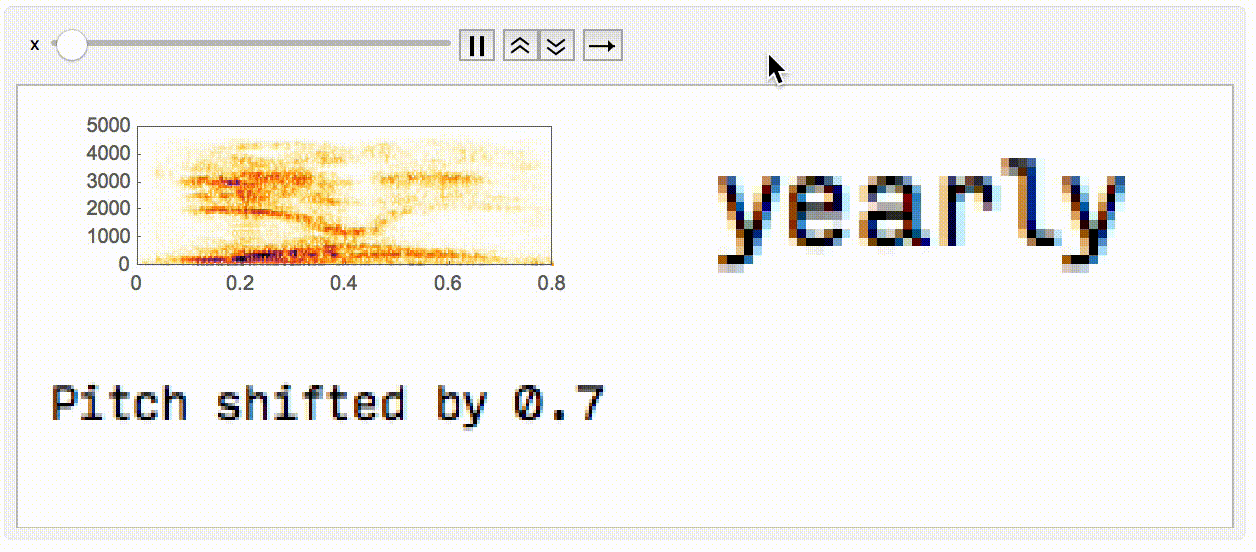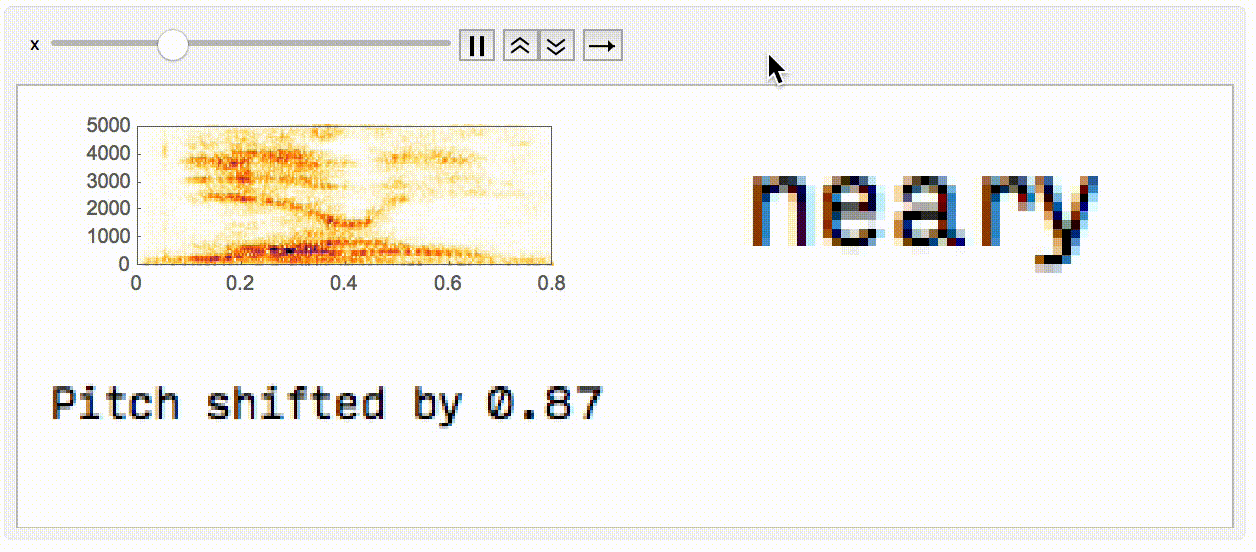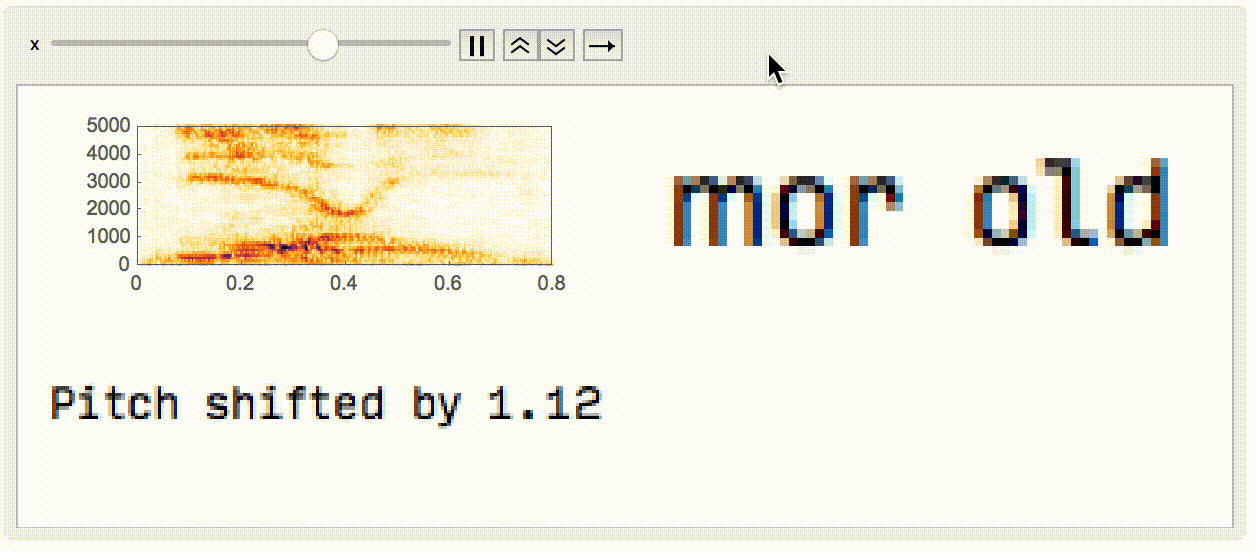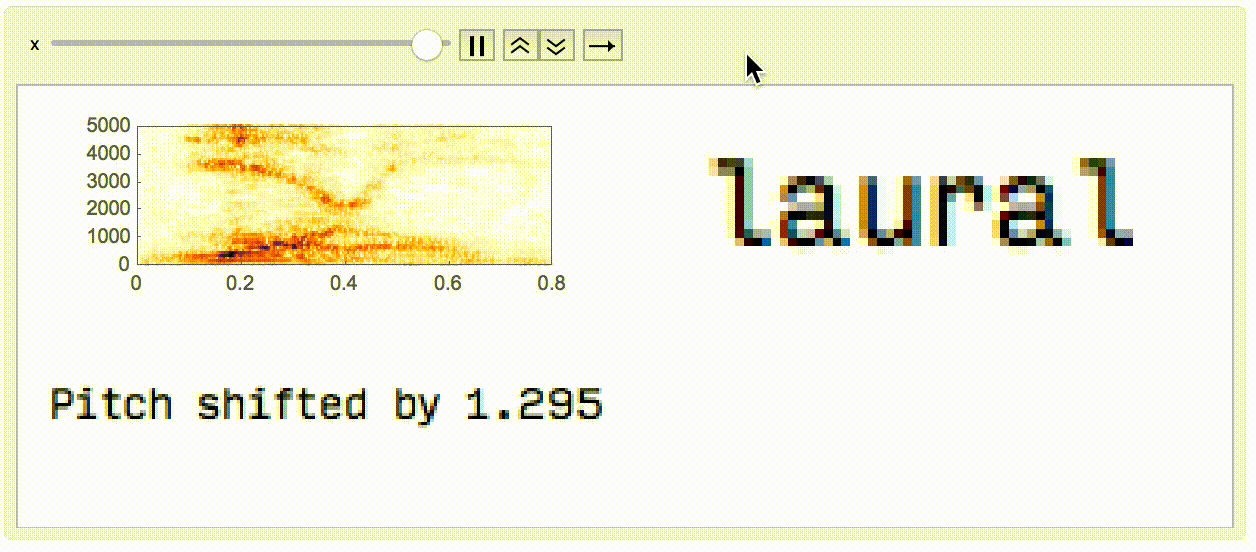
In conclusion, I think that tiny differences in the pitch of what you hear can have a big difference on what your brain parses as a word. These differences in pitch might be from the speakers you're using, the shape of your ear, your age, who knows. If nothing else, it's pretty cool that we can use a neural network for this as an analog to humans susceptible to echoes of sounds they've recently heard.
This is my first post to the forums so I hope you found it interesting! Please consider checking out Tough Soles - it's got nothing whatsoever to do with this but it is my life's work! :)


