In this post, my goal is to walk through a few of the processes I tested and worked with in the Email functions in Wolfram Language. As a newcomer to Wolfram Language before the Summer School started, learning how the language works and getting used to programming with it was a complete paradigm shift. In addition, it was very interesting to learn how the language treats MailItems as pieces of data and how to access its different properties in order to sort them and do any meaningful analysis. In the end, the functionality in my project was able to clearly present analysis based off of properties of messages, though there is much more I would have liked to do, which I will discuss later in the post.
Beginning: Connecting to the Mail Server
mail=MailServerConnect[]
First things first, getting access to the server. Easy enough, but this very first step taught me very quickly how persnickety the mail functionality might turn out to be. After doing some brainstorming of potential analytics and visualization techniques, I cracked open some of the mail connection functions, but nothing was working. Each run of MailServerConnect[] would return an error, regardless of if credentials were correct or not. Turns out my version of the email connection paclet was not up-to-date and thus non-functional. Thanks to Carlo emailing the dev for some advice, a quick update was an easy fix for the problem (though it took more time to figure out than I would have liked).
inbox=mail["INBOX"]
normal@inbox
Connected to the inbox, now let's look at what information the inbox stores:
<|"Path" -> "INBOX", "Name" -> "INBOX", "TotalMessageCount" -> 12639,
"UnreadMessageCount" -> 37, "ObjectType" -> "MailFolder",
"InternalID" -> 1|>
So the properties of the inbox itself don't tell us anything particularly useful. However, this really isn't a problem: each message has its own properties that are much more informative:
In[6]:= propsOfMessage = inbox[-1]["Properties"]
Out[6]= {"PERMANENTFLAGS", "UIDVALIDITY", "UIDNEXT", \
"TotalMessageCount", "RECENT", "HIGHESTMODSEQ", "UnreadMessageCount", \
"ObjectType", "Path", "InternalID", "MessagePosition", "Flags", \
"Name", "From", "FromAddress", "FromName", "ToList", "ToAddressList", \
"ToNameList", "CcList", "CcAddressList", "CcNameList", "BccList", \
"BccAddressList", "BccNameList", "ReplyToList", "ReplyToAddressList", \
"ReplyToNameList", "OriginatingDate", "Subject", "Body", \
"Attachments", "MessageID", "OriginalMessage"}
All this one line of code is doing is displaying what properties/tags each email has attached to it. Most have blatantly obvious meanings, like "ToList" and those similar to it; but some I still do not know quite what they mean, like "UIDVALIDITY".
The Search
MailSearch[inbox,<|"any tag from above" -> "any string you want to search corresponding to the tag"|>]
These tags immediately come in handy when sorting through the inbox, as you can quickly plug in the search criteria you need. However, using this function as a method of grabbing and sorting emails is horribly inefficient and the search results are all wrapped in another layer of data, making them harder to access as easily.
Analysis
emailsFromInbox=inbox[-75;;];
Now for the actual analysis. For reference,emailFromInbox is just a list of the 75 most recent mail items from inbox. Pre-loading this list of mail items into a variable makes analysis more efficient than grabbing one email at a time. The timing just to reach the server and come back with the mail item is:
In[9]:= timings = Table[Timing[inbox[1 ;; n]][[1]], {n, 1, 10}];
In[10]:= approx[x_] = Fit[timings, {1, x}, x]
Out[10]= -0.65 + 0.330114 x
Obviously, this scales up rather quickly if run on large groups of emails, so pre-loading onto a variable to only do once is just better.
For the first visualization,
emailMostCommonWords[number_Integer?Positive] := (
noList = WordList["Stopwords"];
WordCloud[
WordCounts[
StringJoin[
Table[
inbox[-x]["Body"],
{x, number}
]]],
WordSelectionFunction ->
((StringLength[#] < 10) &&
! (MemberQ[noList, #]) &&
(! NumberQ[#]) &)
])
emailMostCommonWords[15]
This simple WordCloud implementation grabs the most used meaningful words from your past x messages. Here is the output for my last 15: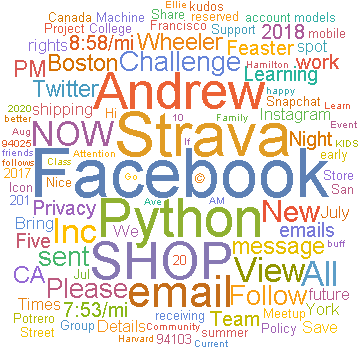
It's pretty clear from a glance that I still haven't turned off email notifications from Facebook for birthdays, and that the two most common senders are from the running/cycling social and logging website Strava.com
Second is a quick glance at who has been emailing me the most over the past 50 emails received, showing the top 15 senders.
commonEmailers = TakeLargest[Counts@Map[#["FromAddress"] &, emailsFromInbox], 15];
PieChart[Values[commonEmailers],
ChartLabels -> Placed[Keys[commonEmailers], "RadialOuter"]]
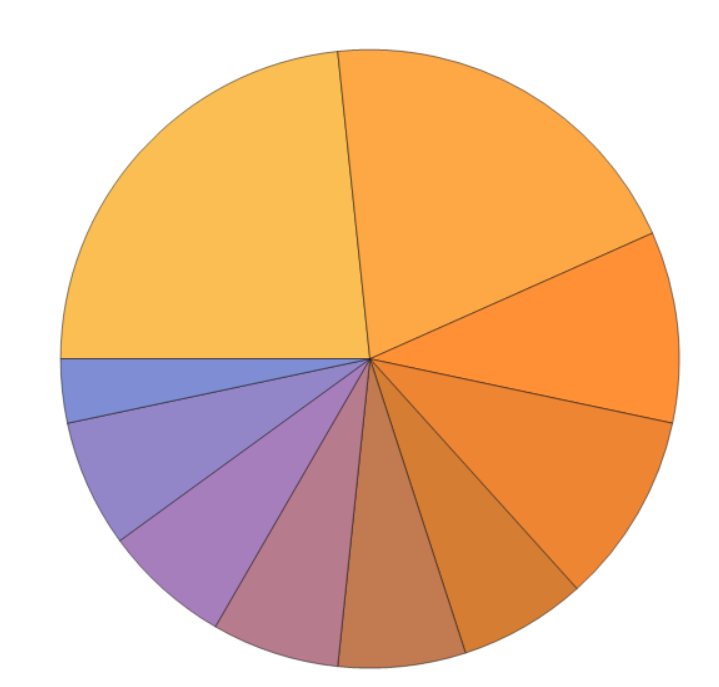
Finally, to confirm any lingering doubts that most emails into this mail account are for notifications instead of conversations with groups of people, a graph of people who email me and who I email:
edges = Flatten@Map[
Function[
{message},
fromList =
If[StringQ@message["FromAddress"], message["FromAddress"],
"weird"];
toList = Select[message["ToAddressList"], StringQ];
ccList = Select[message["ToAddressList"], StringQ];
If[
fromList === "weird",
Nothing,
{
DirectedEdge[fromList, #] & /@ toList,
Flatten@Outer[UndirectedEdge, toList, ccList]
}]],
emailsFromInbox
];
Graph[edges, VertexLabels -> "Name"]
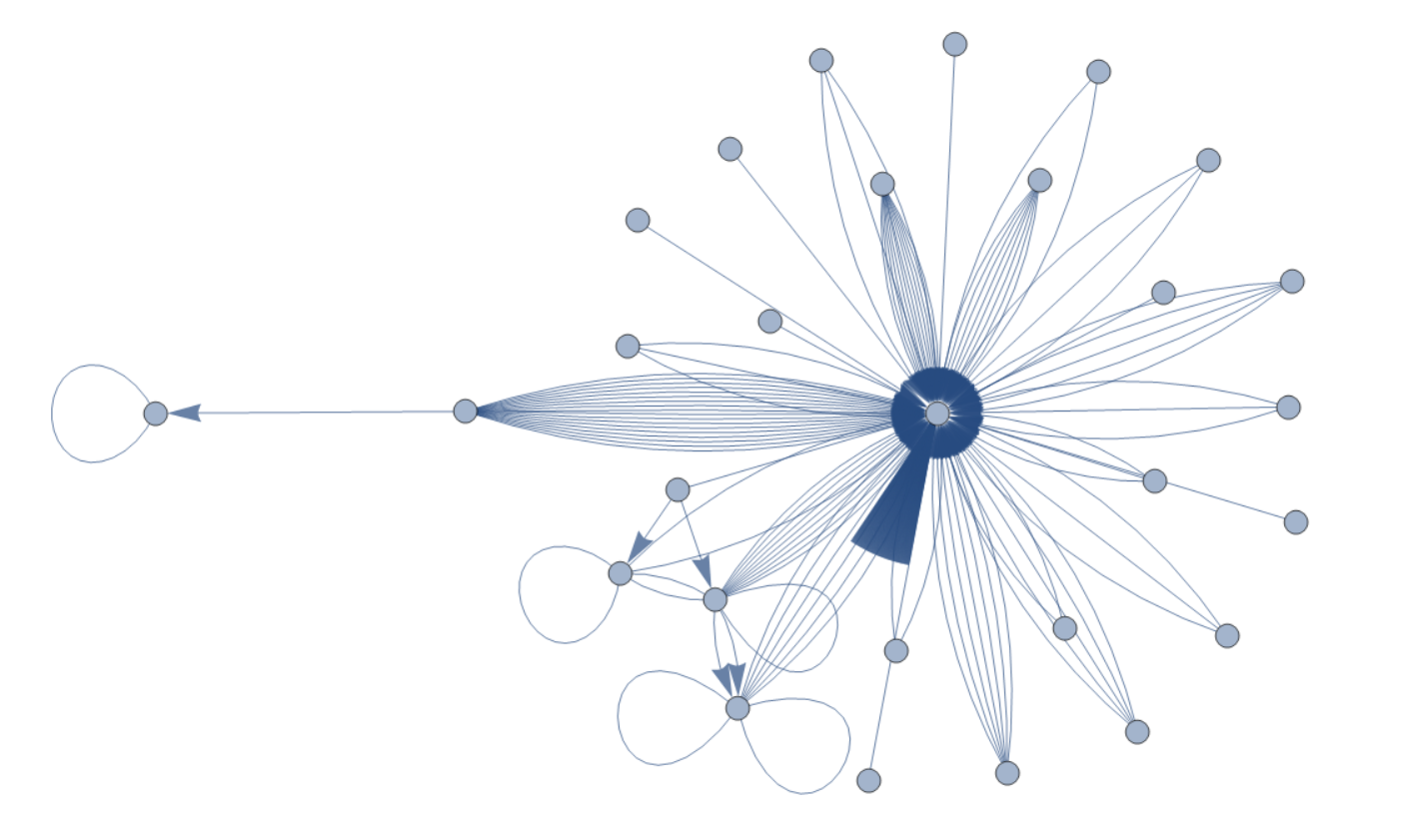
Any directed edge represents an email from the node to the node being pointed to, and an undirected edge represents people who were co-recipients of the same email (either on the CC list or the list of direct recipients).
Future Work
One area within mail I did not get to during my time working on this project was dividing the analysis into distinct groups of people, and making the results searchable. Analysis on larger groups who communicate more often could yield much more interesting conclusions, such as which groups or individuals are left out most often, or which groups are most like a clique.
Contact Information
Andrew Wheeler, axwheele@hamilton.edu


