Address: https://www.wolframcloud.com/objects/zhamilya.bilyalova/Questionator
The goal of this project was to create a classifier using the neural network or a classify function to determine if a piece of text a question.
Introduction
The training dataset consists of 20000 lines of questions and statements with their corresponding classes of questions or not questions taken from
- Quora Question Pairs Dataset
- Summaries of Wikipedia articles
- Movie lines (to have examples that are most similar to everyday language.)
New parameters were created using Text analysis capabilities of Wolfram Language and different statistical models were applied inside classify function. A linear neural net was created and performed classification with 90% accuracy. Comparably, the best classify function had an accuracy of 85.5%.
Classify
Original dataset without new parameters:
Best performed when Markov Chain was increased to order 5 and Feature extractor was set to SegmentedWords.
Method: Markov
Accuracy: 73%
With three new parameters:
Parts of Speech - creates a numerical sequence representing Parts Of Speech
5W1H questions - gives the position of the first 5W1H question
An example of the training set: {"The toddler years are a time of great cognitive, emotional and social development", {4,7,7,15,4,7,10,1,1,13,1,3,1,7,13} , 0 } -> Not a Question, "How come The Simpsons predicted things correctly see the image", {2,15,4,12,15,7,2,13,15,4,7,13,13} , 1 } -> "Question"}
Method: Gradient Boosted Trees
Accuracy: 85.5%
Neural Net
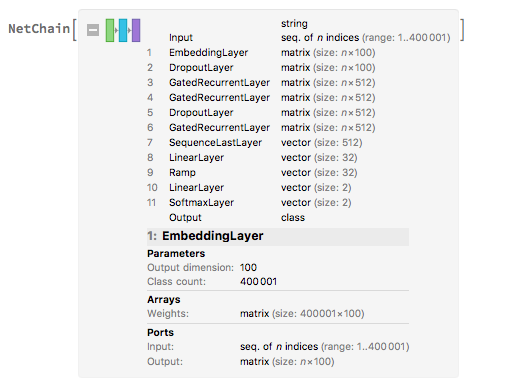

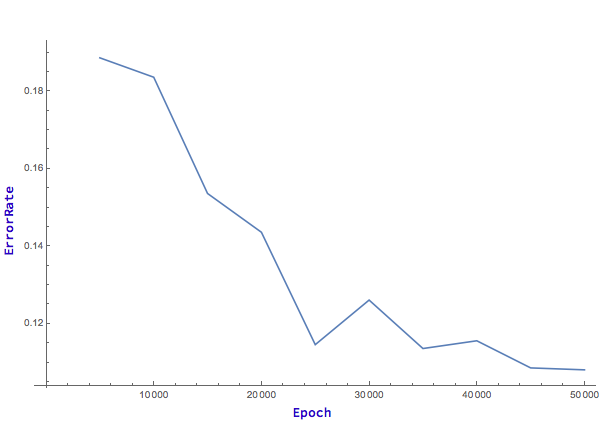
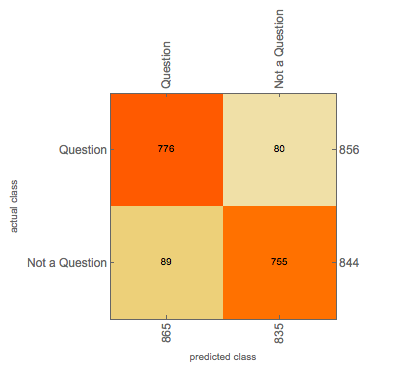
Examples of misclassified sentences: "I would rather we all stay-- Don't stop just slow down." -> "Not a Question", "I'm shipping out sooner than I thought." -> "Not a Question", "You're saying I have no choice." -> "Not a Question", "Answer the phone." -> "Not a Question", "Big fan." -> "Not a Question", "She." -> "Not a Question"
We can notice that most misclassified sentences are hard to classify even for a human because whether a person asks a question or makes a statement can depend also on the tone, previous question or conversation.
An attempt to improve my neural net by changing embedding layers to (taken from Wolfram Neural Net Repository) :
- GloVe 100-Dimensional Word Vectors Trained on Wikipedia and Gigaword 5 Data "using an original method called Global Vectors (GloVe). It encodes 400,000 tokens as unique vectors, with all tokens outside the vocabulary encoded as the zero-vector."
- ELMo Contextual Word Representations Trained on 1B Word Benchmark. "It produces three vectors per token, two of which are contextual, meaning that they depend on the entire sentence in which they are used. These word vectors are aimed at being linearly combined."
It did not improve the neural net but only decreased to 65% of accuracy. It is possible that when applying ELMo there was an error and in future, it can be used again to try and improve the original neural net.
Future work
This classifier has a lot of applications. For instance, it can be used in autocorrection or for analyzing audio transcripts for devices like Siri. The future work for me will include improving the accuracy of the neural network by optimizing it's architecture and allowing the network to, for example, comprehend contextual questions. If you have any ideas, please let me know! Thank you for reading this post!


