Abstract
This project seeks to determine the correlation between the questions asked by Supreme Court justices during oral argument appeals and justices' votes to affirm or reverse the decision. Using over 3,000 oral argument transcripts from the past 28 years, this project will primarily utilize Mathematica machine learning capabilities to examine these transcripts; attempting to find a mechanism that suggests which way a justice will vote according to the questions asked by said justice in a trial. Secondly, this project will examine larger patterns of vote direction in the Supreme Court and suggest further areas of research with this data.
Data Sources
In order to assemble the main dataset used in this project, I used GNU Wget to pull all available pdfs from the preassembled repository of oral arguments on the Supreme Court's website [1]. I then used Textract to batch convert the .pdf files to .txt files, and regex to run preliminary text cleaning measures on the .txt files, resulting in 3,590 relatively clean transcripts ranging in cases argued in 1980 to 2016. As an aside, I realize that I could have used Mathematica to do much of this preliminary cleaning, but was limited as I was unable to access Mathematica prior to attending the Wolfram Summer School.
My second database was a collection of opinion results and the votes of respective justices, which is maintained by Washington University Law [2]. Both of these data sources are available to the public in the footnotes.
Data Visualization
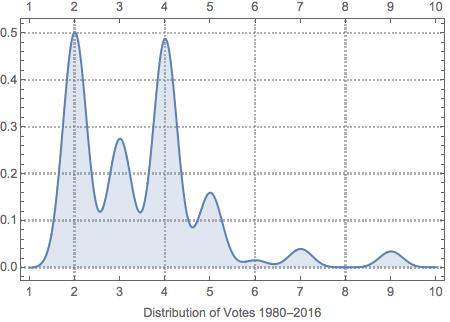
Below are three graphs. The first shows the overall distribution of votes over the available oral arguments where the votes respectively were coded as below. As you can see, the vast majority of the cases resulted in the case being either affirmed or reversed and remanded.
- 1 = stay, petition, or motion granted
- 2 = affirmed (includes modified)
- 3 = reversed
- 4 = reversed and remanded
- 5 = vacated and remanded
- 6 = affirmed and reversed (or vacated) in part
- 7 = affirmed and reversed (or vacated) in part and remanded
- 8 = vacated
- 9 = petition denied or appeal dismissed
- 10 = certification to or from a lower court
- 11 = no disposition
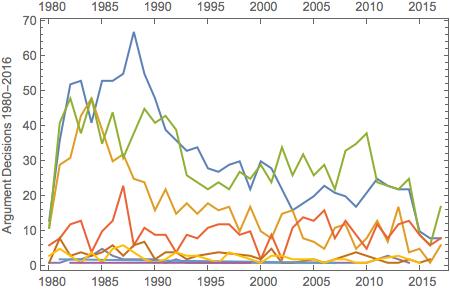
Then, I plotted the distribution of votes over time. As you can see below, the quantity of affirmed cases peaked around 1990 and decreased since then.
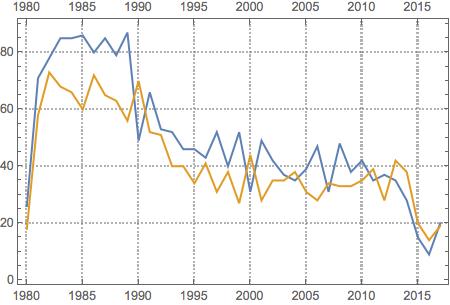
Finally, I plotted the distribution of Supreme Court decisions over time coded as liberal or conservative. It is interesting to note that the vast majority of cases have been decided in a liberal direction, and only just recently have more conservative-leaning decisions been made.
Training Classification
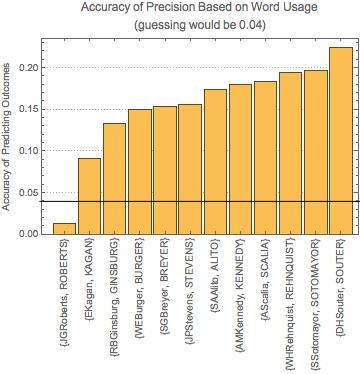
As oral argument transcripts weren't standardized until the 2000's, many transcripts in the 80's and 90's did not specify who was asking which question. This resulted in about half of the justices having less than 300 collected statements. I only ran machine learning measures on those with more than 300 statements for greatest accuracy. I then ran what each justice said along with their vote through a machine learning process, hoping to be able to predict vote from individual statements. This yielded an accuracy rate of about 15-25% with a few outliers:
`wordbag[votes_, {justice_, lastName_}] := Module[
{readyForClassify, trainingData, testingData, fakeJudge,
judgeOfFakeJudge},
readyForClassify =
MapAt[ToString,
MapAt[StringJoin, votes[{justice, lastName}], {All, 1}], {All, 2}];
{trainingData, testingData} =
TakeDrop[RandomSample@readyForClassify,
IntegerPart[0.8 Length[readyForClassify]]];
Length[trainingData];
fakeJudge = Classify[trainingData];
ClassifierMeasurements[fakeJudge, testingData]
]`
Sentiment Analysis
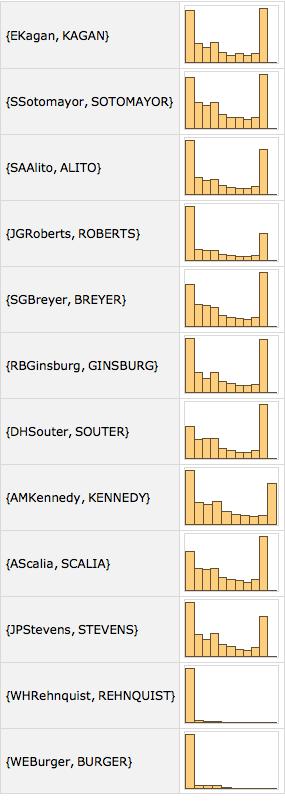
Due to time constraints, I was unable to create a similar function to run each justices' statements through machine learning. However, the dataset below shows that the majority of what each justice says tends to be negative, with few moderately positive statements, and a strong upswing in very positive statements. This pattern is repeated multiple times throughout various justices' collected statements, suggesting many varied possibilities for future research.
MapAt[Chop@Classify["Sentiment", #, "Probability" -> "Negative"] &,
mergedVotes[[1]][[2]], {1, All}]
sentimentToVote =
Map[Function[{vote},
MapAt[Chop@
Classify["Sentiment", #, "Probability" -> "Negative"] &,
vote, {1, All}]], KeyTake[mergedVotes, significantConvo], {2}];
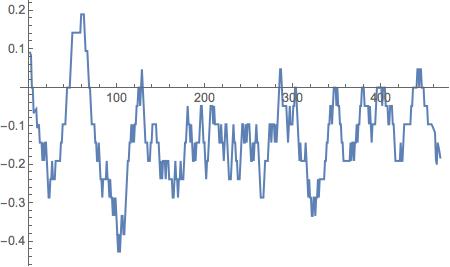
Additonally, I plotted sentiment processed language over a transcript. This was especially interesting in regards to predicting case outcomes, and I will do more of this type of examination in the future.
plotemotion[emotion_String] :=
ListLinePlot[{MeanFilter[
ReplaceAll[
Classify["Sentiment", emotion], {"Positive" -> 1,
"Negative" -> -1, Indeterminate -> 0, "Neutral" -> 0}], 10]},
PlotRange -> All, Joined -> True]
plotemotionmean[mean_String] :=
Mean@ReplaceAll[Classify["Sentiment", mean]]
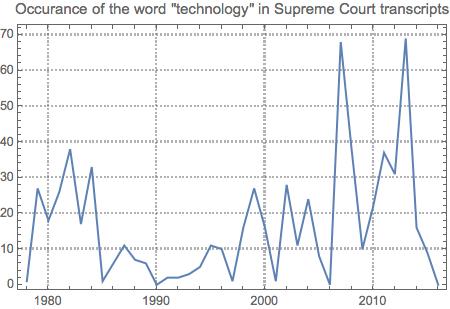
Word Frequency Across Cases
The final measure I looked at in this project was word usage frequency over time. I coded the below example with "technology", but any word can be substituted.
wordCounts = Map[
Function[
{entry},
yearAbbreviation = First@StringSplit[entry["Docket"], "-"];
year = If[
StringMatchQ[First@Characters@yearAbbreviation, "0" | "1"],
"20" <> yearAbbreviation,
"19" <> yearAbbreviation
] /. years;
{year, StringCount[entry["RawText"], "technology"]}
],
docketAndText];
DateListPlot[Total /@ GroupBy[wordCounts, First][[All, All, 2]],
PlotTheme -> "Detailed",
PlotLabel ->
"Occurance of the word \"technology\" in Supreme Court transcripts"]
I packaged this up, and created an interactive cloud page where vistiors can see how frequent word usage is throughout oral argument history: Word Frequency Cloud object.
Future Possibilities
There is a need for further work to clean the data I used. As mentioned above, a significant portion of the transcripts from the 1980's has minor OCR errors that could be easily remedied with appropriate tools.
In the future, I plan to further examine the link between emotionally classified language and votes as well as the interaction between justices and the attorneys arguing the case. Additionally, there may perhaps be a stronger link between the number of the words spoken by the justice and the resulting vote, or alternatively, there may be a correlation between the frequency of particular words used and the outcome of the case. Originally, I was intending to examine gendered dynamics between justices, but, due to a limited number of female justices (4), this was not possible. However, there are many potential future hypotheses to be studied in regards to gendered dynamics between the justices and female attorneys. Finally, a more detailed analysis of the political alignment of each justice and respective direction of vote is needed. I look forward to continuing to develop these directions in the near future.
Finally, I'd like to thank Roy Garringer for his help in gathering and cleaning the data which I used, and Kyle Keane for his constant much-needed assistance throughout this project.
Footnotes
[1] www.supremecourt.gov/oralarguments/argumenttranscript/2017
[2] scdb.wustl.edu
Contact Information
hannah.r.garringer@gmail.com
Notebook available on GitHub: https://github.com/hannahgarringer/OralArguments


