
Introduction
My name is Likith Palabindela and I attended the 2018 Wolfram Summer Camp. The project I worked on was a derivative of my interests, machine learning and neural networks, which were just some of the skills I learned and improved on over the span of the two weeks. I tried to create a neural network that identified the type of font when an image of the text was inputted.
Machine learning is the branch of Artificial Intelligence that deals with machines and computers learning how to perform specific tasks with a high accuracy. This is done by supervised or unsupervised learning: supervised learning is the process of giving the network a specific set of inputs and outputs and letting it learn from that data, while unsupervised learning depends only upon feeding in a specific input and relying on the network to figure out the differences between the data set. The neural network does this by using a specific type of algorithm pertaining to the data. Some of the most common algorithms are linear/logistic regression, decision tree, and K-means.
In a CNN (convolution neural network), the end goal is to take an input of an image and give a desired output, which is usually a list of probabilities corresponding to a list of outputs. The 3 most common layers in a CNN are a Convolution Layer, Ramp, and a Pooling Layer. A Convolution Layer converts an image into a list of matrices using a kernel of defined size and other defined parameters. A Ramp is a simple function that outputs 0 if the input is negative and outputs the input if the input is a non-negative number. A Pooling Layer is essentially a down-sampler: it takes a matrix as an input and takes the largest number in the kernel size to transform it to a smaller sized matrix. In addition, a Linear Layer performs the dot product of the weights and inputs and adds the bias to it: $$ y=\text{wx}+b$$The command Flatten Layer converts an n-sized tensor to a vector and a Dropout Layer prevents overfitting by taking in a percentage as an input, and the percentage defines how often a layer is removed.
Procedure
The hardest and most important part of the project was producing the data. At the beginning, I made a program that would rasterize a 120x120 pixel image of string of letters and special symbols. I weighted the characters to match their specific usage in the English language, while the symbols were arbitrarily assigned weights.
Alpha = Join[Alphabet[],
ToUpperCase[Alphabet[]], {"." , ";", "/", "!", "(", ")", "?",
"\n", " "}];
weights = {8.167, 1.492, 2.782, 4.253, 12.702, 2.228, 2.015, 6.094,
6.966, .153, .772, 4.025, 2.406, 6.749, 7.507, 1.929, .095, 5.987,
6.327, 9.056, 2.758, .987, 2.36, .25,
1.974, .074, .5, .5, .5, .5, .5, .5, .5, .5, .5, .5, .5, .5, .5,
.5, .5, .5, .5, .5, .5, .5, .5, .5, .5, .5, .5, .5, .1, .1, .1 , .1,
.1, .1, .1, .5, .2};
trainingSet =
ImagePad[#, {{90, 30}, {80, 40}} - {{ImageDimensions[#][[1]],
0}, {ImageDimensions[#][[2]], 0}}, White] & /@
Table[Rasterize[
Style[StringJoin[
RandomChoice[weights -> Alpha, RandomInteger[{2, 8}]]],
FontFamily -> #, Black, FontSize -> 20], RasterSize -> 50],
500] & /@ fontlist;
This is an example of what a randomly generated Comic Sans MS picture looked like: 
I generated 500 pictures for each of the 10 fonts, which translated to 5000 pictures in total as my training set. The next step was actually creating the neural net to process the images and classify them. The first net I used the was Ademxapp Model A taken from the Wolfram Neural Net Repository. The first problem I faced arose here: I was training a neural net programmed to identify the main object in an image, to recognize font types. The Mathematica kernel would crash every time I tried to train the net on my GPU, and it would take about 2 hours to train on my CPU, which was unacceptable. I recognized this huge error and took advantage of a much simpler net - LeNet, which was used to identify any handwritten digit in a picture. I used the backbone for LeNet and modified it according to my data's needs.
learnedNet = NetChain[
{
ConvolutionLayer[20, 5],
Ramp,
PoolingLayer[2, 2],
ConvolutionLayer[50, 5],
Ramp,
PoolingLayer[2, 2],
ConvolutionLayer[70, 5],
Ramp,
PoolingLayer[2, 2],
DropoutLayer[.5],
FlattenLayer[],
LinearLayer[500],
Ramp,
DropoutLayer[0.5],
LinearLayer[10],
SoftmaxLayer[]
},
"Input" -> NetEncoder[{"Image", {120, 120}, "Grayscale"}],
"Output" -> NetDecoder[{"Class", fontlist}]
]
I added a Convolution Layer, followed by a Ramp and Pooling Layer, and a couple of Dropout Layers to the LeNet network in order to make the error the lowest possible. The error was very low (around 1%), but the net would only recognize the font from images that were generated by the previous function. After testing the net with screenshots I took of text from online sites, I realized that I would need to train the neural net on data that was somewhat practical. With this in mind, I took a lot of screenshots of texts with different fonts and made a function that would crop a random spot on the image to a 120x120 image.
This imports the images from my desktop and was repeated 10 times in total:
wingdings =
Import[#] & /@
FileNames["*",
"C:\\Users\\Likith Palabindela\\Desktop\\testing net\\wingdings"];
algeria =
Import[#] & /@
FileNames["*",
"C:\\Users\\Likith Palabindela\\Desktop\\testing net\\algeria"];
This function generates random 120x120 images from the screenshots:
randomImages[img_, n_] :=
ImageTake[img, {#[[2]], #[[2]] + 119}, {#[[1]], #[[1]] + 119}] & /@
Thread[{
RandomInteger[{1, ImageDimensions[img][[1]] - 120}, n],
RandomInteger[{1, ImageDimensions[img][[2]] - 120}, n]
}]
Generating 100 random images for each screenshot(2 out of the 10 functions):
imagelist = {randomImages[times[[#]], 100] & /@ Range[7],
randomImages[calibri[[#]], 100] & /@ Range[6]};
Threading each image to the type of font, so it is easy to input into the net(2 out of the 10 functions):
threadlist =
Flatten[{Thread[
Flatten[randomImages[times[[#]], 10] & /@ Range[7]] ->
"Times New Roman"],
Thread[
Flatten[randomImages[calibri[[#]], 10] & /@ Range[6]] ->
"Calibri"]]
This is an example of what a picture from the function looks like: 
I then successfully trained the 6,500 randomly generated image on my neural net: 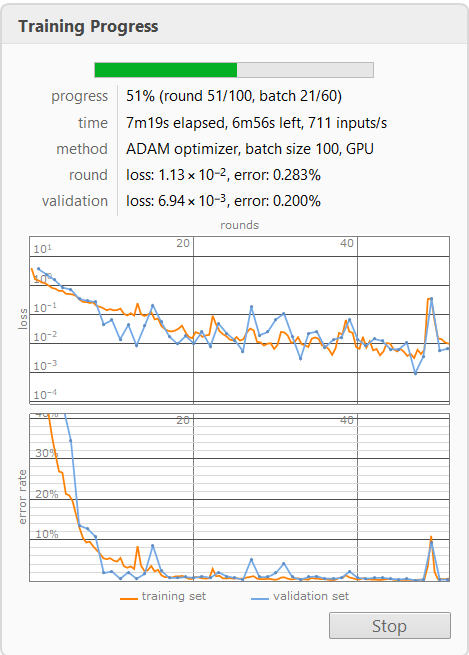
Conclusion
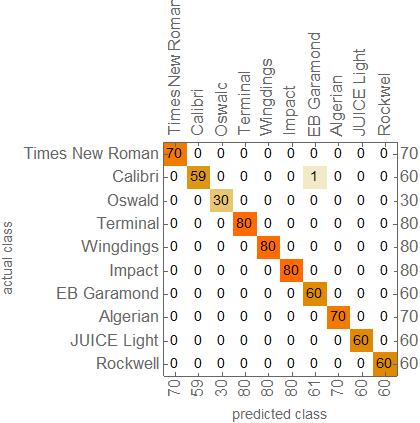
The neural net was successfully trained on my generated data with a final accuracy of 99.69%. The net, however, is only useful when used in conjunction with the image generating function. It has trouble recognizing any other format that would be used in real world application. Although the functionality of the neural net is limited, it could be fixed with the right type of training data. Expanding on the struggles I had with this project, selecting and modifying the right type of neural net should be one of the top priorities alongside getting an accurate and practical data set. In the future, this net could be improved by being trained on images of sentences, separate words, and even bold and italic fonts.
Acknowledgements
I want to thank my mentor Michael Kaminsky for helping me complete this project and solve any problem I had throughout the duration of the 2 weeks.
 Attachments:
Attachments:


