The Conway's Game of Life have a very simple set of rules that can be summarized in Mathematica with two lines:
GameOfLifeRule[{1,2|3}|{0,3}] := 1
GameOfLifeRule[{center_Integer, sum_Integer}] := 0
If the center cell is alive (1) and it has 2 or 3 neighbors (sum), it will live (1). If the center cell is dead (0) but it has 3 neighbors (sum), it will live (1). Otherwise, all shall die (1).
In this post, we'll manually construct a Neural Network (NN) that can give the next state of the Game of Life. It will require no training whatsoever and we'll use only our knowledge of the rules of the game.
First NN
Let's ''train'' a very simple NN that will able to tell what is the next state of the board given the center cell and the sum of its neighbors. First, we generate the data for the NN (only 18 elements).
data = Flatten@Table[
{center, sum} -> List@GameOfLifeRule[{center, sum}]
, {sum, 0, 8}, {center, 0, 1}]
And then create a very simple NN. The values of the Weights and Biases below were chosen after a 1-min simulation was run and then rounded. And then the layer ElementwiseLayer[#^5 &] was added to make the final output either 0 or 1 more sharply. The NN bellow doesn't need to be trained as it is already "trained".
net = NetChain[{
LinearLayer[2, "Weights" -> {{0,3},{-4,-4}},
"Biases" -> {-11,11}],
LogisticSigmoid,
LinearLayer[1, "Weights" -> {{-16,-16}},
"Biases" -> 8],
ElementwiseLayer[#^5 &],
LogisticSigmoid
}, "Input" -> 2, "Output" -> 1];
Let's test it:
Tally@Table[Round@net@d[[1]] == d[[2]], {d, data}]
(* Output *) {{True, 18}}
There is probably a clever way of doing the same, but it will suffice for now.
Second NN
Now that we can predict the next state of a cell, we need to build an NN that can apply those rules to all the board.
A 3x3 convolution is the key of doing that. Look at the following two kernels:
$\begin{pmatrix} 1&1&1 \\ 1&0&1 \\ 1&1&1 \end{pmatrix}$ and $\begin{pmatrix} 0&0&0 \\ 0&1&0 \\ 0&0&0 \end{pmatrix}$
The first one gets the sum of the neighbors of the central cell while the other is just a duplicate of the central cell. Which is basically the inputs of the previous NN built.
So, in order to build an NN that can play the game of life, we need to run the two convolutions above and apply the previous NN to it, it can be done as:
netPlay[W_Integer, H_Integer] := NetChain[{
ConvolutionLayer[2, {3, 3}, "PaddingSize" -> 1,
"Weights" -> {
{{{0, 0, 0}, {0, 1, 0}, {0, 0, 0}}},
{{{1, 1, 1}, {1, 0, 1}, {1, 1, 1}}}
}, "Biases" -> None],
ReshapeLayer[{2, W*H}],
TransposeLayer[],
NetMapOperator[net],
ReshapeLayer[{1, H, W}]
},
"Input" -> NetEncoder[{"Image", {W, H},
ColorSpace -> "Grayscale"}],
"Output" -> NetDecoder[{"Image",
ColorSpace -> "Grayscale"}]
]
Where we have reshaped and transposed the layers so we could apply the previous net only at the channel's level.
Now we need to test our NN. To do it, we will build a function that generates a random Game Of Life board.
RandomLife[W_Integer, H_Integer] := Block[{mat, pad=2},
mat = ArrayPad[RandomInteger[1, {H, W}], pad];
mat[[1,1]]=mat[[-1,-1]]=1;
Rule @@ (ImagePad[Image@#, -pad] & /@ (
CellularAutomaton["GameOfLife", {mat, 0}, 1]))
]
Where we generate a random board and pad it, apply the Game of Life rules and then crop the result. This is needed since Mathematica changes the size of the board with the CellularAutomaton function, hence we use a trick of padding and adding a cell that will die in the next interaction, just to make sure the board will stay the same size. A very hacky way, but nonetheless, it works...
a = RandomLife[30, 20]
netPlay[30, 20][a[[1]]] - a[[2]]

Where we can see from the difference of both images that the NN can indeed predict the Game of Life rules.
Let's now apply it to a more realistic scenario. Gliders!
img = Image@ArrayPad[{{0,1,0},{0,0,1},{1,1,1}}, 10];
ListAnimate@NestList[(netPlay@@ImageDimensions@img), img, 45]
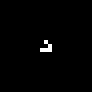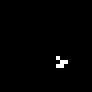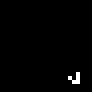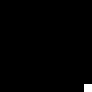
Notice that the Glider just dies at the corner of the board.
An interesting problem that we could pose is to write the problem backward. Given the current configuration, try to find a previous one, only using random images as a training set. It is well-known that the Game Of Life is not reversible, so this procedure it's not always possible. But it would be interesting to see what the NN would predict.
One could build such a neural network by feeding random images and then using convolutions to build the previous step, and then apply the previous network shown above to get back the input image and see the differences, in a kind of auto-encoder-way.


