This is an interesting discussion! (In the following I am using the data from the OP posted notebook.) If one uses the full data as training-set, then the result should be better. Using then the same full data as test-set should lead to a still more improved result. I guess relevant are the relative differences:
trainingsset = Thread[Rule[Transpose@{X1, X2, X3, X4}, Y]];
cfunc = Predict[trainingsset, PerformanceGoal -> "Quality"];
relDiffData = Abs[cfunc[#1] - #2]/#2 & @@@ trainingsset;
ListLinePlot[relDiffData, PlotRange -> All, ImageSize -> Large,
GridLines -> Automatic,
Epilog -> {Red, Dashed, With[{m = Mean[relDiffData]}, Line[{{1, m}, {Length[relDiffData], m}}]]}]
which gives:
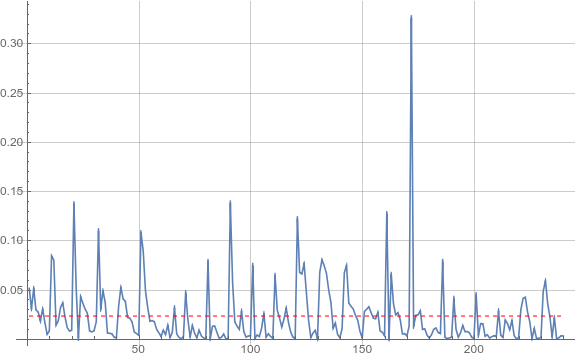
We find a mean relative difference of about 2.3%, but the discrepancies can be considerably larger. (I had expected a somewhat better agreement.)
In addition I find this interesting:
Correlation[relDiffData, #] & /@ {X1, X2, X3, X4}
(* Out: {-0.464144, 0.23598, -0.130216, 0.640481} *)
The prediction seems to have the most problems with data set X4.


