I have a problem in which I want to optimize the placement of sensors in addition to using a NN to predict what those sensors are "saying".
(Aside: It's kind of an interesting issue if you try to optimize both the NN and the sensor placement at the same time in a single NetGraph. The training data--at least what is fed into the NN--changes at each iteration. I've developed a few strategies for doing this but none work very well as there is a local minimum for each sensor combination. The best strategy seems to be decoupling the two optimization problems, finding some good sensor layouts with a GA-like strategy, and then doing brute-force hill climbing from those layouts. If anyone is interested in this or would like to discuss better strategies, let me know.)
To find good sensor layouts I run NetTrain many times. I have notice that the input rate drops significantly with the number of training runs. At first I thought this might be because the GPU (both a Quadro M4000 and a GTX 1050Ti) might be getting hot a reducing their clock speeds. Some simple testing showed this was not the case (and the GPU loads are typically less than 20%). If I stop the training for awhile (to, say, let the GPUs cool) and then start back up, the input rate does not increase back to when the training iterations started. If, however, I restart the kernel and start training immediately, the input rate climbs back to what it was initially. Thus, it seems something is going on in the kernel or the link between it and MXNet.
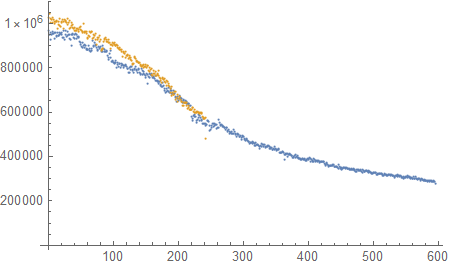
I have included a graph of the mean input rate for each network that is trained. At various points I stopped the training but the rate continues to drop. When I restart the kernel the rate resets and starts the cycle again (orange dots).
Thoughts?
Eric Mockensturm
Edit:
Sorry, I didn't mention that this occurs with all NNs I've tried, even extremely simple ones. As an example, put a loop around this:
NetTrain[NetChain[{16, Ramp, 12, Ramp, 4, SoftmaxLayer[]},
"Output" ->
NetDecoder[{"Class", Range[4]}]], trainingData, "ResultsObject",
ValidationSet -> testingData, MaxTrainingRounds -> 12000,
BatchSize -> 20000,
TargetDevice -> {"GPU", 1}, TrainingProgressReporting -> "Panel"]
and generate 20000 training points with any input size (I've tried downto 2x1) in each loop iteration. The data in the graph is simply the MeanInputsPerSecond for each iteration.


