Introduction
By utilizing machine learning functions in Mathematica, we could predict genders of the input voices. The dataset we used is the open audio source VoxCeleb1 Dataset, which contains over 100,000 utterances for 1,251 celebrities from YouTube videos. The powerful build-in Classify function helps us to classify real voices into categories, to learn from examples, and predict values from data. Neural network is applied to tackle dataset with camouflaged or frequency-shifted voices.
Predict Gender For Real Voices
Dataset
First we download information for all the speakers in the dataset from the website, the data structure is shown as below:
 then, eliminate the headings, extract and build association of ID and gender columns.
then, eliminate the headings, extract and build association of ID and gender columns.
metadata = Rest @ Import["http://www.robots.ox.ac.uk/~vgg/data/voxceleb/meta/vox1_meta.csv", "Table"];
$id = 1; (*gender is the 1st colomn*)
$gender = 3; (*gender is the 3rd colomn*)
idToGender = Association[Thread[metadata[[All, $id]] -> metadata[[All, $gender]]]];
Each ID represents one voice which contains several dialogues and each dialogue envelopes more than one utterances. The VoxCeleb1 Dataset, though claims it contains more than 1,251 IDs or celebrities' voices, is not complete. some IDs in the CSV file do not have the associated audios. We randomly choose one audio of 100 IDs out of the whole and make associations between them.
(* Randomly choose samples in the auido directory *)
IDN = 100;
samples = RandomSample[DSdirectories = Select[FileNames[All, "", Infinity], StringLength[#] == 7&], IDN];
Audiodata = Flatten[RandomSample[FileNames[All,Directory[]<>"/"<>#,Infinity], 1] &/@ samples];
(* Make associations between audios and genders *)
genderData = idToGender[#] &/@ samples;
audios = Map[Import[#]&, Audiodata];
realDataset = Thread[audios -> genderData];
{realTrainingData, realTestData} = TakeList[realDataset, {4/5 IDN,All}];
Training process
By using the in-build function Classify in Mathematica and check the accuracy of the classifier.
classifyRealVoices = Classify @ realTrainingData;
cm = ClassifierMeasurements[classifyRealVoices, realTestData];
cm["Accuracy"];
cm["ConfusionMatrixPlot"];
The accuracy could reach 100% and the confusion matrix plot is attached below: 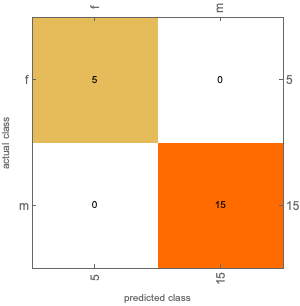 **
**
In real world, voices are sometimes camouflaged, either frequency-shifted or pitch-shifted. Classify function could not deal with a dataset containing both true and shifted voices. The idea is that fundamental frequencies is the key factor to identify the gender of a given voice, I shift the even fundamental frequencies(FF) of each training voice to 165Hz ~ 180Hz which is the overlap of the FF between male and female, so that we could make Classify concentrate on qualifying. However, this only works well with low-shifted voices.
Predict Gender For Camouflaged Voices
Here we utilize the neural network and download the net model from Wolfram Neural Net Repository for the gender recognition of frequency-shifted voice.
Dataset
We make two audio datasets by randomly sampling from the audio pool, one dataset contains real voices and the other one contains 1000 corresponding frequency-shifted voices with a shift range from -2000Hz to 2000Hz according to the selected true voices.
(* Set path for real and shifted or fake voices *)
realpath = FileNameJoin[{audioPath, "wavBig"}];
fakepath = FileNameJoin[{audioPath, "wavBigFake"}];
(* The shift function is given below: *)
makefake[file_]:=
Export[
FileNames[file],
AudioFrequencyShift[Audio[file], RandomReal[{-2000,2000}]*Quantity[1,"Hertz"]]
];
After obtaining the real and fake audio data and associating it with gender information, we divide them into three subsets: the training set, the validation set, and the test set with a ratio of 8:1:1.
(* Associate audios and genders *)
tagData[file_]:= idToGender[First@StringSplit[FileNameTake[file,-1], "_"]];
realData = Map[Rule[Audio[#],tagData[#]]&,
Select[FileNames[All,realpath], !StringContainsQ[#,"._"]&]
];
fakeData = Map[Rule[Audio[#],tagData[#]]&,
Select[FileNames[All,fakepath], !StringContainsQ[#,"._"]&]
];
lenReal = Length @ realData;
lenFake = Length @ fakeData;
len = lenReal + lenFake;
testLength = Floor[lenReal * 0.1];
trainLength = Floor[lenReal * 0.9];
(* test data *)
testData = Flatten @ Join[{realData[[-testLength;;]], fakeData[[-testLength;;]]}];
trainingData = Flatten @ Join[{realData[[;; trainLength]], fakeData[[;; trainLength]]}];
(* training data and validation set *)
{train, valid} = TakeList[RandomSample[trainingData], {Floor[8/9 trainLength], All}];
Training process
The net model we used is adapted from VGGish Feature Extractor Trained on YouTube Data, which is in the Wolfram Neural Net Repository. We can define different models with different size of training data and different classes.
The first NN model we trained is with 2000 data-points (half from the real voice dataset, the other half from the fake voice dataset), and with 2 different categories, male (m) and female (f). This model gives us 90% accuracy.
classes = {"f","m"};
classifier = NetGraph[<|
"features"->NetModel["VGGish Feature Extractor Trained on YouTube Data"],
"dropout" -> DropoutLayer[],
"linear"->NetMapOperator[LinearLayer[]],
"max"->AggregationLayer[Max,1],
"softmax"->SoftmaxLayer["Output"->NetDecoder[{"Class",classes}]]
|>,
{"features"->"dropout"->"linear"->"max"->"softmax"}];
trainres2 = NetTrain[
classifier, train, All, ValidationSet->valid,
BatchSize->8,
TargetDevice->"GPU", LossFunction->CrossEntropyLossLayer["Index"],
TimeGoal->Quantity[15,"Minutes"]]
We trained the second NN model with the same data samples above in 4 different categories, such as male (m), female (f), fake male (fakeM), and fake female (fakeF). Though whether the voice is true or not doesn't really matter and the gender is what we care about, we want to check if the neural network is smart enough to identify even a small shifting amount in frequency. This is useful when one male voice is shifted to a natural woman voice, vise versa. The confusion matrix plot is shown below with an accuracy of 83%:
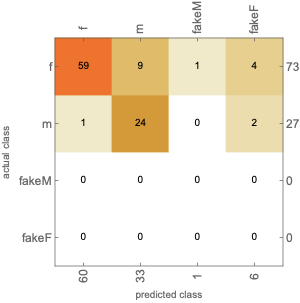
The difference in accuracy between the above two classifiers leads us to investigate if the reason behind this is because NN could not work well with identifying true and fake voice recordings. We then run a third classifier with classes of fake and real voices. The given accuracy is 95% and the confusion matrix plot is as below:
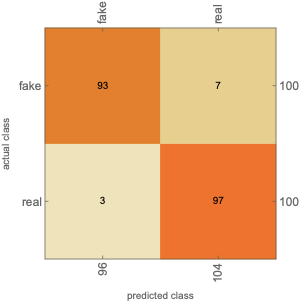
Discussions
The build-in Classify function gives decent predictions on gender from real voice data but not camouflaged ones. The Neural Network must be adapted to deal with frequency-shifted voice recordings. We observed NN could identify gender of fake voices with a rough accuracy of 90% when the data is tagged by female and male FM classifier). In case the data tagged by both gender and fakeness, the NN returns a classifier with accuracy of 83% FTG classifier). NN could also gives a good classifier to identify fake and true voices (FT classifier).
Though all the classifiers trained by NN obtain decent accuracy, we could not safely address that they could most likely tell the truth by giving any voices with any frequency change ranged from -2000Hz to 2000Hz. For example, if we increase the frequency of a male voice by more than 300 Hz, the FM and FTG classifiers almost always identify this fake voice as female, vice verse. Aside from the size of our training data, one possible explanation is that the function we use for deciding how much we shift the frequency of true voices for generating fake voices is RandomReal in Mathematica. We could not guarantee each true voice is shifted properly since for each voice, a small shift with regard to its original frequency won't make any difference and a large shift could lead to audio distortion. Both of those cases give rise to unreliability of our classifiers' accuracy. Another possible explanation is the composition of our audio data. Though we set up our training dataset with half true voices and half camouflaged voices, gender balance is not taken into consideration because of the randomness in our choosing strategy. Due to the limitation of time and computation resources, we haven't worked on those two yet.
Future work
We could enlarge our training data, optimize the audio data composition and find a better mechanism to shift the voice frequencies as what we brought up above.
Explore different layers for the NN training to improve our classifier in identifying gender of heavily frequency-shifted camouflaged voices. Moreover, we didn't deal with pitch-shifted voices which is different from our aspect. We didn't deal with pitch-shifted voices which is different from our aspect. Shifting frequency gives audio by shifting the spectrum of audio by the given frequency. However, applying pitch shifting to audio is shifting every frequency f to r f in the spectrum.
If we are lucky enough to solve all the problems above, we will reach a situation where poor personal detectives could tell the gender of a camouflaged anonymous phone call no matter how much it is shifted either in frequency or pitch. Then we could even step forward further, imagine you have the a camouflaged anonymous audio and a piece of true voice recording of a suspect, you want to know if they are from the same person.
Contact
Please contact me if you have any idea or comment that could shed light on my confusions in the Discussion and Future work parts!
zhang@astro1.sci.hokudai.ac.jp
Here is my Github link.


