 Dataset in plaintext
Dataset in plaintext
 Dataset in Wolfram Language
Dataset in Wolfram Language
1. Introduction
Data analysis is a process of inspecting and transforming raw data with the goal of discovering useful information and supporting decision-making. Most raw data is in plain text format such as comma-separated values(CSV) file. Processing huge amount of data usually needs a lot of time and it is hard to get useful information from plain text. Fortunately, Wolfram Database contains numerous information and users can access it easily if the input format is in Wolfram Language. Processing data in Wolfram Language is also very convenient. For example:

This article introduces a way to convert plain text from CSV file to Wolfram Language computable expressions. By using the function convertData[], users can import any CSV file and convert it to Wolfram Language. This function is able to handle large dataset contains millions of cells. It also provides several options to speed up and help users to convert particular data.
2. Function Overview
The function convertData[] contains three steps: split raw data; find special type in data and convert it to Wolfram Language. First step finds the structure of the imported file and splits it into two parts: header and body. Second step searches any potential special data types from header and body by using regular expressions. Third step converts corresponding data to Wolfram Language. All three methods will be discussed in details in section 3. The result of using this function is shown as the following figure:
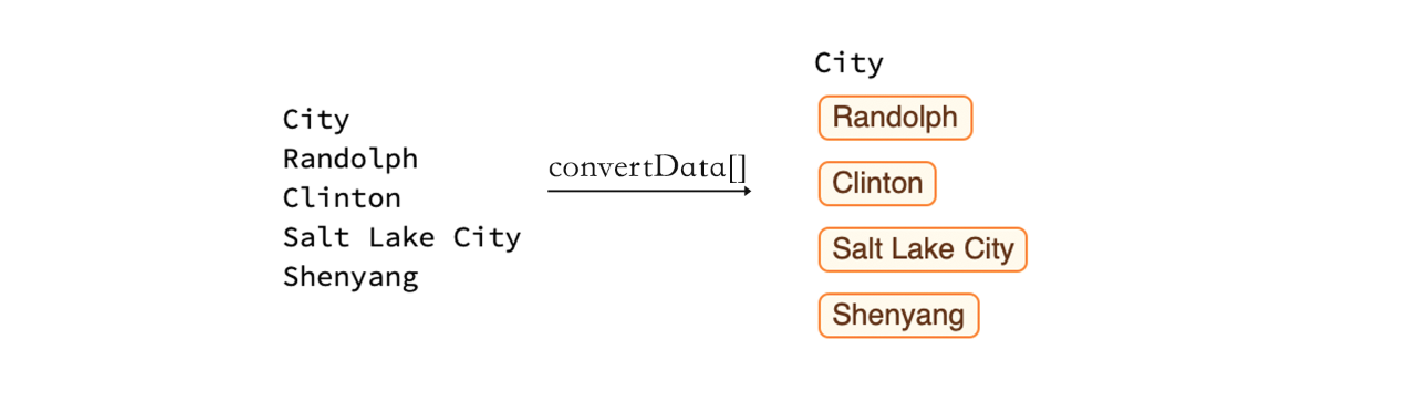
3. Method
3.1 Split Data
The first step is to find the structure of raw data. Generally speaking, a well-organized dataset contains two parts: header and body. Header part contains title of this dataset (if any) and data type of each column in body part. Assuming the length of the header part is the same as the body part, we take first up to 100 rows from dataset to avoid long time processing. Then we parse the whole part of selected rows to find data type of each column such as Email address, phone number, etc.
columns = Take[file, UpTo[100]];
interpretColumn = Map[parser, columns, {2}];
columns // TableForm
interpretColumn // TableForm
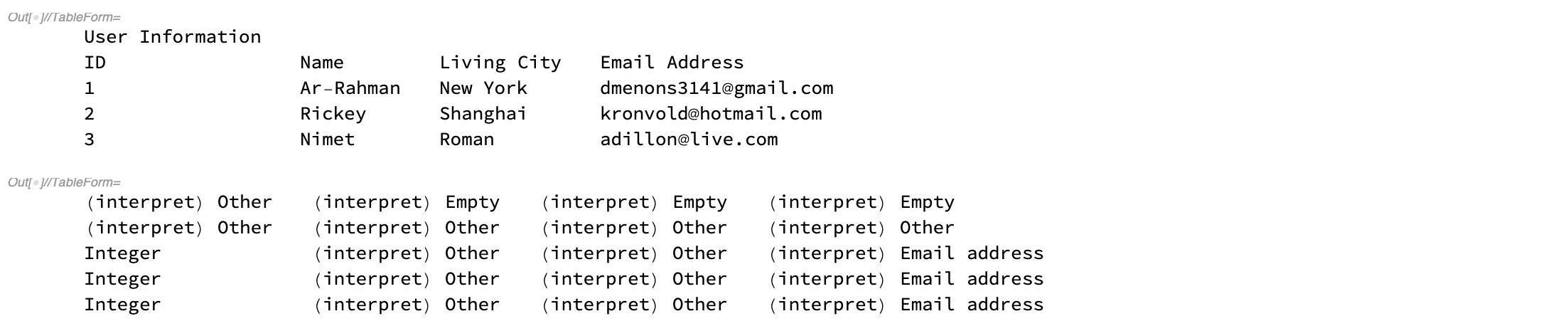
Some specific data types will be caught, others (like strings) will be categorized as (interpret) Other. Blank cell will be categorized as (interpret) Empty. After categorizing selected rows, we find the commonest data type in each column.
bodyType = Normal @@@ Commonest /@ interpretColumn

As we can see, the commonest type of first column is integer and of last column is email address.
We then exclude all columns which majority cells are categorized as empty and other because these two types may affect the result. Recall that a well-organized dataset has the same height of each column in body part, so exclude some columns will not affect the final result. Then we find the first position of remaining data types in each column. The commonest position should be the row where body part starts.
goodTypes = Cases[bodyType, Except["(interpret) Other" | "(interpret) Empty"]];
firstGoodRow = DeleteMissing[
Flatten[ FirstPosition[Alternatives @@ goodTypes] /@ interpretColumn]]; header = First[Commonest[firstGoodRow], 1]

Result from code shows that the body part starts from row 3, which is the same as we can see from raw data.
3.2 Find special data type
We have split whole dataset into two parts: header part and body part. We have also categorized some special data types. Now we need find the rest of them, especially for those which are categorized as (interpret) Other. To approach this, we parse the header part again to find any keyword that indicates this column could contain a special data type. We use regular expressions to match keywords, the regex rules are very flexible to find any keyword from interpretList such as "Year", "First_Year" and will exclude similar words but have different meaning such as "Yearly".
interpretList = {
"Phone", "Email", "URL", "LatitudeandLongitude", "Year", "Date", "Zip", "City", "State", "Country"}; headParser = {RegularExpression["(?i)^.(\b|\)city(\b|\).$"] ->"(interpret) City"}; headToString = Map[ToString, Transpose[headPart], {-1}]; headMerge = Map[StringJoin, Riffle[#, " "] & /@ headToString]; headParsing = StringReplace[headParser] /@ headMerge
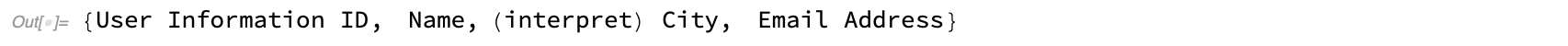
The third column is now categorized as (interpret) City, whereas it was categorized as (interpret) Other during first parsing.
Then we merge result from first parsing and result from second parsing to get the whole list of special data type in the dataset. We also find the corresponding indices of these columns.
dataType = Transpose[{headParsing, bodyType}];
dataSpecialTypePosition = Position[
dataType, List?(MemberQ[String?(StringStartsQ[ Alternatives @@ specialList])])][[All, 1] ] dataSpecialType = Intersection[#, specialList] & /@ dataType[[dataSpecialTypePosition]]

The result shows that the third column may be city and the forth column may be Email address, which is the same we can see from raw data.
3.3 Convert to Wolfram Language
The last step is to convert selected data to Wolfram Language. According to different data types, different interpreters will be executed. The position of targeted column is first found by dataSpecialTypePosition we got from previous subsection. Then by using Interpret[] function with corresponding entities we can convert plain text to Wolfram Language. If interpreting is failed then original input will be returned. After interpreting all columns, final result will be shown as function output. Interpretation list which is supported by this function now contains phone number, Email, URL, geolocation, year, date and time, ZIP code, city, state and country.
cityPosition = Position[dataType, "(interpret) City"][[All, 1]];
If[cityPosition != {},
cityTemp = Transpose[bodyPart[[All, cityPosition]]]; cityResult = Interpreter["City"] /@ cityTemp; cityResult = cityResult /. f_?FailureQ :> f["Input"]; bodyPart[[All, cityPosition]] = cityResult[[1]] ]; Join[headPart, bodyPart] // TableForm

4. Function Options
Interpreting huge amounts of data sometimes is very slow since interpreter may go back to Wolfram Database to search related information. This may cost hours to process data. To avoid this case, convertData[] provides several function options to help users speed up.
4.1 Types of interpretation
There are three different types of interpretation which allow users to interpret their data according to their needs.
"InterpretType" -> "None"
Interpretation type is set to "None" in default. Interpret will not work in this case, function output is raw data.
"InterpretType" -> "Fast"
Fast Interpretation only interprets parts of data types: phone number, Email, URL and geolocation. All of these types don't take long time to interpret. The function convertData[] executes in very short time.
"InterpretType" -> "Full"
Full Interpretation interprets all data types. Notice in this case the function convertData[] may take very long time to process data since some entities like city, state, country need interpreters go back to Wolfram Database to find related information.
4.2 Fast Preview
"FastPreview" -> False
Even with "Fast" type of interpretation, columns with thousands of data still take very long time to interpret. Fast preview allows users to only interpret parts of data. The default is False, if it is set to True, convertData[] will only interpret first ten rows of data. (Exclude header part). Users can then decide to further interpreting or not.
4.3 User Specified Interpretation
"InterpretChoice" -> All
Users can choose specific data type to interpret. The default value is All, which will interpret all data types. However, users can specify any particular type of data they want to interpret. For example,
"InterpretChoice" -> {"City","Date"}
will only interpret columns with city and date data types.
4.4 Showing IntermediateStep
"IntermediateStep" -> False
The function convertData[] can show intermediate step if users have questions about certain steps. These steps contain finding header and body part; finding special data type and interpreting data.
5. An example
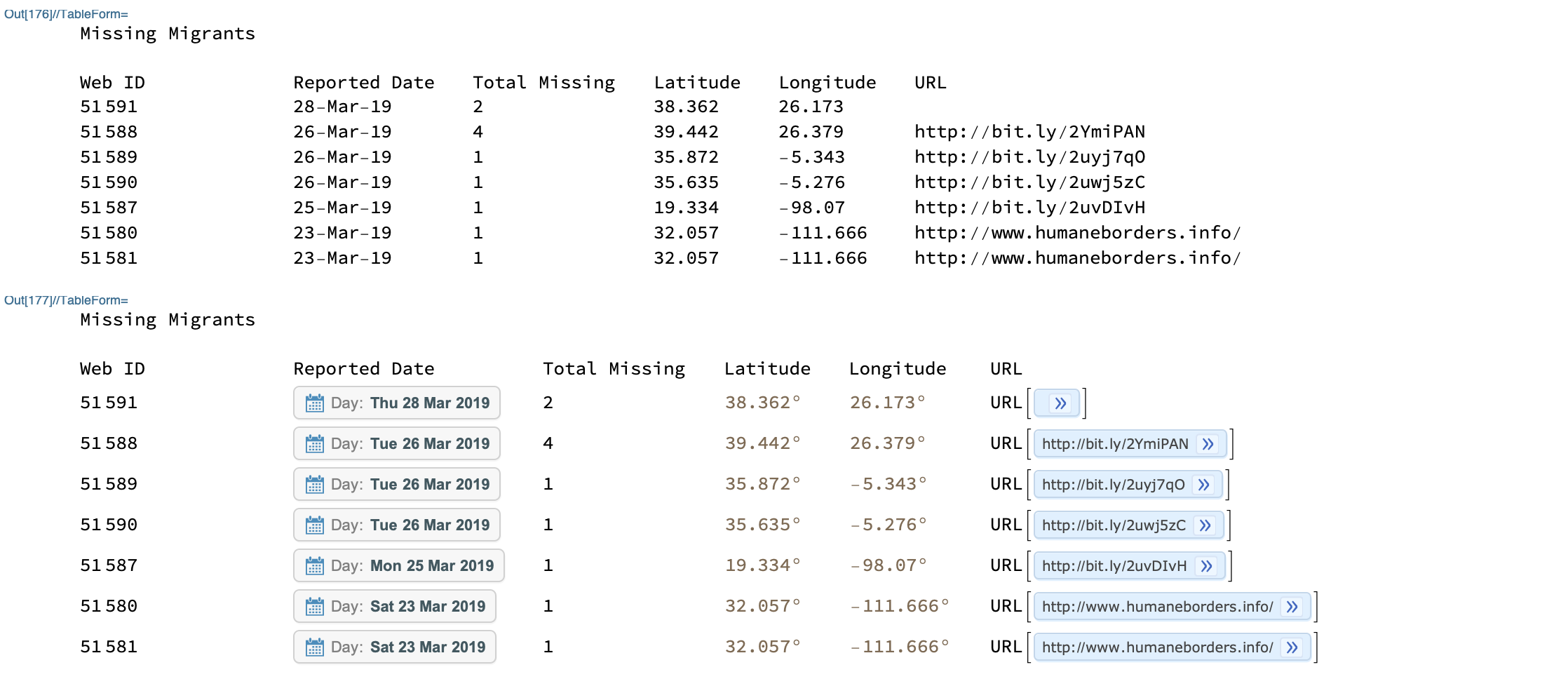
Following is part of data from Missing Migrants Project, we can use convertData[] to convert it to Wolfram Language.
rawData // TableForm
convertData["InterpretType" -> "Full"] // TableForm
6. Potential Problem and Future Work
If the header part of a dataset is larger than body part, the function will not split the dataset correctly, although this case should be rare. In the future, convertData[] should interpret more data types such as currency, address, etc. It should also have more accurate type inference, especially on numerical data.
Contact
LinkedIn: https://www.linkedin.com/in/yifei-xiao/
E-mail: yifei.xiao1995@gmail.com
 Attachments:
Attachments:


