Introduction
What kind of computation and knowledge representation do we need, to be able to identify false statements like
"Paul Newman, born in San Francisco, issued a statement today"?
Can we break such an utterance into elementary statements (e.g. speech acts or semantic units) to facilitate automatic validation using computational knowledge bases or Knowledge Graphs, and logical reasoning? If the statement is more complex, as for example:
"Paul Newman issued a statement today. He mentioned that he was born in San Francisco."
can we validate the second sentence that contains anaphoric expressions like personal pronouns, without explicitly mentioning Paul Newman?
Although there is an endless number of problems and issues with this task, the short answer is: of course we can.
We can utilize common Natural Language Processing (NLP) algorithms and Knowledge Representations to achieve that. Some of these NLP algorithms and knowledge representations are core components of Wolfram Language. Given the following text:
myText = "Paul Newman, born in San Francisco, issued a statement today.";
TextStructure will return some valuable linguistic annotation for this input:
TextStructure[myText]
The resulting output provides basic part-of-speech information and syntactic structures:

In addition to this kind of linguistic analysis, we might need some annotations that emphasize entities in the input text, in particular people, locations, date or time expressions, or organizations. TextContents is useful for typing named entities:
TextContents[myText]
This function call will display a table with highlighted named entities and their corresponding type information:
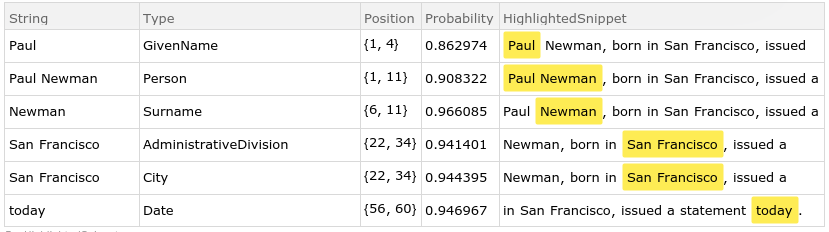
To be able to process the entities detected in text, we need to look up details about entities in the Wolfram Language Entity store. The Interpreter function returns an entity object that best matches the specification provided by the Named Entity analysis above. In this case, we can query "Paul Newman" of type "Person" and store the result in the pn variable:
pn = Interpreter["Person"]["Paul Newman"]
This will return an entity object:

We can use this entity object to query properties of it:
pn["Properties"]
The output will display all the properties an Entity can have:

One of the listed properties is "place of birth". Querying for the place of birth for a given entity can be achieved using the following code:
pn["BirthPlace"]
For our concrete entity "Paul Newman" as stored in the pn variable, the returned value will be:

The InputForm of this entity will revel the underlying data structure as:
Entity["City", {"ShakerHeights", "Ohio", "UnitedStates"}]
These are already very impressive and powerful tools for validation. We would like to identify the claim in a statement like "Paul Newman was born in San Francisco." as:
- Person: Paul Newman
- Location: San Francisco
- Claim: Location is Property "BirthPlace" of Person
If we can extract the entities and associate the predicate "was born in" as pointing to the Entity Property value BirthPlace, we can use a simple query to validate a claim:
SameQ[Entity["City", {"SanFrancisco", "California", "UnitedStates"}],
Entity["City", {"ShakerHeights", "Ohio", "UnitedStates"}]]
In this particular case the result would be False. We could detect a false claim in this specific case. But, we would like to check the facts in a more generic way using computations to identify deviation from some objective truth as encoded in entity properties, relations between entities, or other formal and logical knowledge systems. We want to be able to not only extract the entities from some text or sentence, but also process correctly the semantic properties. For that we need many more NLP technologies and deep digging into natural language properties, in particular semantics and pragmatics.
How can we achieve all this?
To address some aspects of this question, I decided to break down the problem into isolated sub-problems that as such are useful for various other NLP, information extraction, or text mining tasks. The following posts describe the sub-problems and potential solutions in more detail (as I finalize the different chapters, I will link them here in this list):
- Parsing sentences: Constituent and Dependency Parse Trees
- Lemmatization
- Analyzing the Scope of Negation
- Anaphora Resolution and Coreference Analysis
- Extracting core semantic relations as knowledge triples (in the RDF or Knowledge Graph sense)
- Mapping of Predicates to Entity Properties
Contact
Personal website: Damir Cavar


