EXchange FORmat for experimental numerical nuclear reaction data parser for Wolfram Language
Introduction
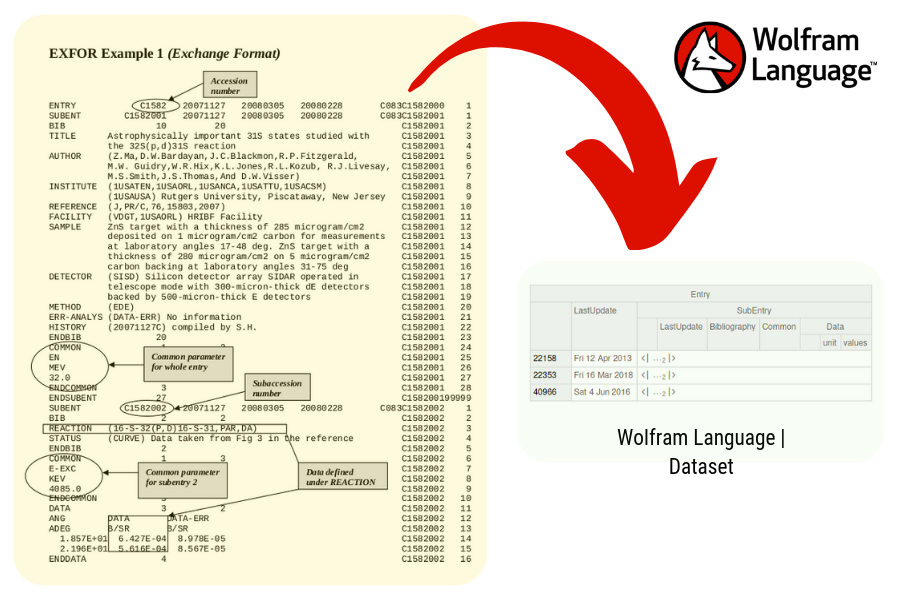
"EXFOR is the database for experimental nuclear reaction data maintained by the international Network of Nuclear Reaction Data Centres (NRDC) co-ordinated by the IAEA Nuclear Data Section." or/and "EXFOR is the exchange format for the transmission of experimental nuclear reaction data between national and international nuclear data centres for the benefit of nuclear data users in all countries". - EXFOR Documentation
In order to work with experimental numerical nuclear reaction data, one usually search for such kind of data in any EXFOR mirror. These website mirrors are maintained by Centre for Photonuclear Experiments Data (CDFE/Russia), Hokkaido University Nuclear Reaction Data Centre (JCPRG/Japan), Nuclear Data Services (IAEA/Austria), Nuclear Energy Agency Data Bank (NEADB/OECD/PARIS), National Nuclear Data Center (NNDC/USA) and other organizations.
Problem and solution
The WOLFRAM Language (WL) is known for its symbolic representation. One can parse different kinds of files, such as TEXT, JSON, XML, CSV, and work with them using WL. The language is also known for its variety of function for data visualization. Nevertheless, WL does not have any kind of function to extract information from EXFOR format files.
We expect that one can work with EXFOR files using WL in a faster way as they do using other file formats. This parser will set all the information for the user and one will be able to work with the EXFOR files using WL.
Obtaining the EXFOR file - Importing the file
One can obtain the EXFOR file from the EXFOR library:
- Do any request for data,
- Select the entries that work for you and click on the RETRIEVE button,
- In the output data page, select the EXFOR ORIGINAL file format.
I recommend that you do the request and then save the output page as a text file or a string. Both methods are recommended for the next steps.
Data Structure
The EXFOR Format has many manuals and documentations. One can easily find their documentation. We based our descriptions from the EXFOR Formats Description for Users (EXFOR Basics) made by the International Atomic Energy Agency (IAEA-NDS-206).
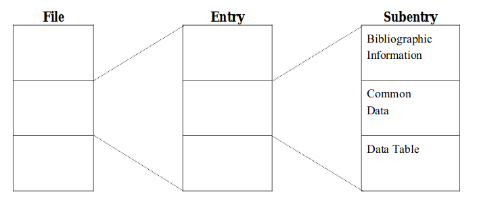
- File
- A file is represented by the EXFOR file that we imported. Each EXFOR File can contain many entries and each entry can contain many subentries.
- Entry
- In few words, an entry represents one experiment. "Each EXFOR entry is divided into a number of subentries (data sets) containing the data tables from this particular work. A subentry is identified by a subaccession number, consisting of the accession number and a subentry number."
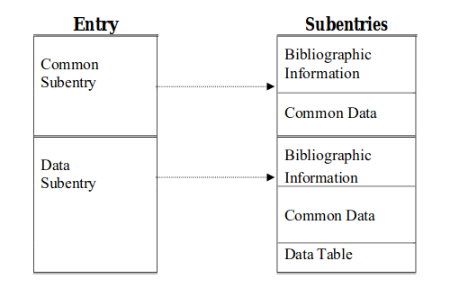
SubEntry
- In few words, each subentry represents the data sets for each experiment (entry). The subentries are divided into:
- Bibliography
- The BIB part represents all the bibliography, descriptions and bookkeeping information from the data.
- Common
- All common data that applies to all data throughout the subentry.
- Data tables
- The data tables contain all the data from the experiments.
Parsing the EXFOR file to a Wolfram Language Dataset
Entries
We first split all the entries inside a file and insert each subentry inside them. In each subentry, we add the information from each of them, as Bibliography, common and data.
parsefSubEntry[entries_String] := Association@StringCases[entries,Shortest[
{"SUBENT"~~___~~subentry1:Repeated[WordCharacter,{8}]~~___~~dateUpdate:Repeated[WordCharacter,{6,8}]~~Whitespace~~content__~~"ENDSUBENT"}]:>
<|subentry1 ->
<|
"LastUpdate" -> DateObject[dateUpdate],
"Bibliography" -> parsefBib[content],
"Common" -> parseCommon[content],
"Data" -> parseData[content]
|>
|>] // Dataset;
SubEntries
We define the function to split each subentry
parsefSubEntry[entries_String] := Association@StringCases[entries,Shortest[
{"SUBENT"~~___~~subentry1:Repeated[WordCharacter,{8}]~~___~~dateUpdate:Repeated[WordCharacter,{6,8}]~~Whitespace~~content__~~"ENDSUBENT"}]:>
<|subentry1 ->
<|
"LastUpdate" -> DateObject[dateUpdate],
"Bibliography" -> parsefBib[content],
"Common" -> parseCommon[content],
"Data" -> parseData[content]
|>
|>];
Helper functions
Now, to help us in our work, let's define some helper functions
Function to split the lines and remove some characters and symbols from each one
lineCleaner[s_String] := StringDelete[StringTake[StringSplit[s,"\n"],53],("(")|(")")|(StartOfString ~~Whitespace..)|(Whitespace.. ~~ EndOfString)];
Almost the same as the previous one, but this function remove some characters and symbols from a string
spaceRemover[s_String] := StringDelete[s,("(")|(")")|(StartOfString ~~Whitespace..)|(Whitespace.. ~~ EndOfString)];
A function to convert some values and units in Quantities (Because some of the units in EXFOR were created/defined by them)
updateUnit[value_String,unit_String] := If[StringMatchQ[ToLowerCase@unit,("mev"|"barn"|"mb/sr"|"gev"|"ev")],Quantity[convertScientNotat@value,unit],value];
EXFOR Files has a different kind of scientific notation than WL. We will convert its format for the WL format. We could use Interpret but it needs internet access. With this function below, one will not need internet connection.
convertScientNotat[value_] :=If[StringMatchQ[value,RegularExpression["\\d"]],value, StringReplace[value,"E"->"*^"]]//ToExpression;
For example
convertScientNotat["-1.307E-01"]
Out[-]: -0.1307
Parsing the content inside each subentry
Bib(liography) content
We define the main function to parse the bib content
parsefBib[entries_String] := Association @ StringCases[entries,Shortest[{"BIB"~~content__~~"ENDBIB"}]:>functionFilterBib[content] ];
As we can find many different kind of information inside a bib entry, we will create a new function to filter these informations
functionFilterBib[subentries_String] := StringCases[subentries,"\n"~~s:LetterCharacter~~Shortest@x__~~Whitespace~~Shortest[content__]~~"\n"~~(LetterCharacter|EndOfString):><| StringJoin[s,x]-> lineCleaner[content]|>,Overlaps->True];
Common content
We define the function to parse each common content
parseCommon[s_String] :=If[StringContainsQ[s,StartOfLine~~"NOCOMMON"],Missing[],
Association@StringCases[s,Shortest[{StartOfLine~~"COMMON"~~content__~~"ENDCOMMON"}] :> functionFilterCommon@content ]
];
As in Bibliography, we defined a new function to filter and parse the content parsed in the last function
functionFilterCommon[s_String] := Normal@Map[
Association[#[[1]] -> Normal@updateUnit[#[[3]], #[[2]]]] &,
Transpose@
StringCases[StringTake[Rest@StringSplit[s, "\n"], 66],
info : Repeated[(RegularExpression["\\S"]), {1, 11}] :> info
]];
More investigations need to be done in this section to improve it.
Data tables
Now we define the function to parse the data grid from the main content
parseData[s_String] := Flatten@ StringCases[s,
Shortest[{StartOfLine ~~ "DATA"~~Whitespace ~~ content__ ~~ "ENDDATA"}] :>
If[StringLength@content>1,functionFilterData[content],<| Missing |>]
];
and we define a function to split the content inside the data grid
functionFilterData[s_String] := functionCreateDataGrid@StringCases[
StringTake[StringSplit[s, "\n"], 66], info : Repeated[(RegularExpression["(\\S|\\s)"]), {1, 11}] :> info ];
and we define another function to adjust the data in the way that we want
functionCreateDataGrid[s_] := Module[{
col = ToExpression@StringDelete[First[s][[2]], Whitespace ..],
row = ToExpression@StringDelete[First[s][[3]], Whitespace..]},
Association@Table[
If[col <= 6,
<| spaceRemover@ Rest[s][[1]][[n]] ->
<| "unit" -> spaceRemover@Rest[s][[2]][[n]],
"values" -> StringDelete[Rest@s[[3;;,n]],Whitespace..] |>
|>, Missing[]]
, {n, 1, col}]
];
Final result
We had a file/string in the beginning and now we have the final data as a dataset
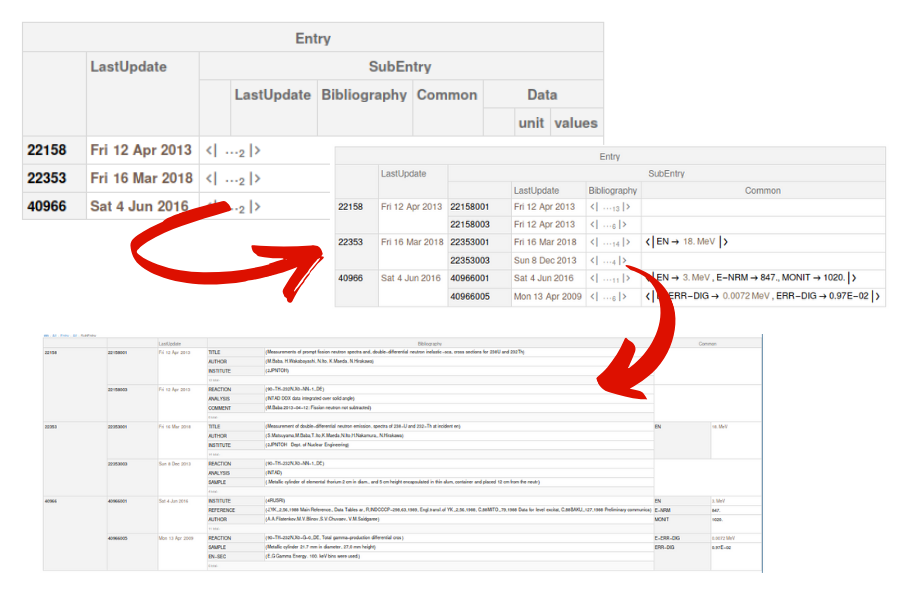
Conclusion
Wolfram Language is interesting because one can do many kinds of things using it. In this project, we tried to work in a data curation problem. Most of the work done was based on strings, datasets, associations, and data manipulation. The data manipulation part needs to be improved but the prototype to work with EXFOR format files is already done.
One will be able to get this project and use it to extract the data from any EXFOR File. The main problem for the project is that we do not have access for the EXFOR library database. The user has to go to one of their websites and collect the data to use here. If we had access, we could get the data directly from their database.
Nevertheless, the project is done and it needs some improving. Some of the next steps to improve this project and to make the functions better were mentioned in the text, but we list all of them here:
- Improve the data grid parsing function,
- Improvements on the common parsing function,
- Create a function to query/plot the data on the final dataset.
GitHub Repo
Check it on my repository: https://github.com/sbrno/WSS-2019
References
EXFOR Web Database & Tools Paper: NIM A 888 (2018) 31


