Overview
Given an image of some sheet music, generate some internal representation of it that can then be played, reprinted or exported to some external musical notation software.
In order to do this, first we split the sheet music into images of each staff, and remove the staff lines; we then find bounding boxes for each musical component using image segmentation, and classify them. This is all then passed to a parser that parses the final sheet music.
Finding the Staffs
Staff lines are long, horizontal and thin; as such, they can be highlighted by using a bottom hat transform with a short vertical kernel, and the extracted with ImageLines. Then, by looking for close groups of five such lines, we can extract an image for each staff in the original score. We also find the median distance between the staff lines, both for padding the staff images and for reusing later.
detectStaffLineImages[image_] := Module[{
staffLines =
Select[ImageLines[BottomHatTransform[image, BoxMatrix[{1, 0}]],
Automatic, 0.0065][[All,
1]], (Abs@VectorAngle[Subtract @@ #, {-1, 0}] <
10 \[Degree]) &]
},
\[CapitalDelta] =
Median@Differences@Sort@Map[Mean, staffLines[[All, All, 2]]];
staffLineGroups =
Gather[Sort[
staffLines, (Last@Mean@#1 > Last@Mean@#2) &], (Last@Mean@#1 -
Last@Mean@#2 < 5 \[CapitalDelta]) &] // Echo;
{Map[
ImageTrim[image, Flatten[#, 1], {0, 2.25 \[CapitalDelta]}] &,
staffLineGroups
],
\[CapitalDelta]}
]


Removing the Staff Lines
Staff lines are dark, long, thin and horizontal. In order to remove them, we use a dilation with a short vertical kernel and the bottom hat transform of the image with a long horizontal kernel; by considering their closing together with taking the pixel-wise minimum and maximum of the resulting image with its morphological binarization, we get an image of the staff with no staff lines and not many artefacts.
removeStaffLines[image_, \[CapitalDelta]_] :=
With[
{withoutStaffLines =
imageMin[Closing[image, BoxMatrix[{\[CapitalDelta]/6, 0}]],
ColorNegate@
BottomHatTransform[image, BoxMatrix[{0, \[CapitalDelta]}]]]},
imageMax[withoutStaffLines,
MorphologicalBinarize[withoutStaffLines, {0.66, 0.33}]]
]
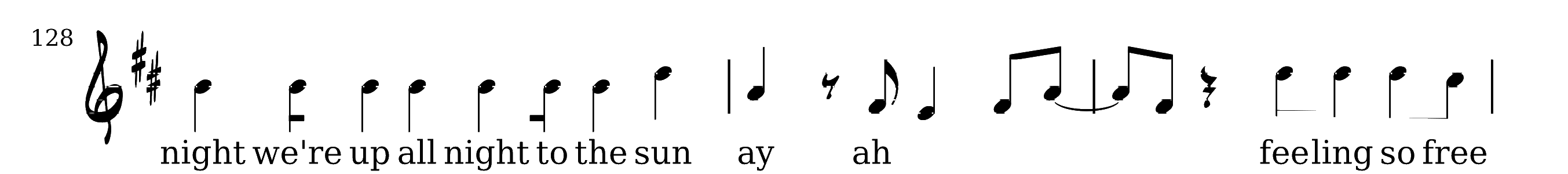
Finding Bounding Boxes for the Musical Components
Image Segmentation
For the image segmentation, we use a SegNet [^segnet] trained on the DeepScores [^deepscores] [Segmentation Dataset](https://drive.google.com/drive/folders/1KFxqi0rO-bJrd03rLk87fF1iOmnjpaoG), with some preprocessing: Each pair of images (original and segmented), was separated into individual staffs and the symbol colors were negated (so that there would be more contrast with the black background).


Finding the Bounding Boxes
In order to find the bounding boxes from the segmented image, we look for the its morphological components using ComponentMeasurements. Before using ComponentMeasurements, we blur and binarize the segmented image, as it usually yields more accurate results; we also discard any bounding boxes with area less than 25 pixels, as that is very likely just noise.

Classifying the Musical Components
For the component classification, we use a ClassifierFunction trained on the DeepScores [^deepscores] [Classification Dataset](https://drive.google.com/file/d/1bdBrX0dAX734I3MA_6-wH_-N2eqq_tf_/view), cropping the images in relation to a lookup table - this is so that the images contain only the actual symbol, and the classifier doesn't learn the context instead of the symbol.
Unfortunately, the classifier trained during the Wolfram Summer Program misclassifies some images; however, it does still provide something that can be worked with.

Parsing the Sheet Music
Very limited parsing could be done during the Wolfram Summer Program: we sort the notes and pitch them, and add rests in as well.
Finding the Pitches
Pitching the notes depends on their distance to the bottom of the staff and a reference pitch, which is determined by the clef. Because of the way we trimmed the staff images, we know that the first staff line (from the bottom) has the Y coordinate $2.25 \Delta$, where $\Delta$ is the distance between the staff lines in the original image. We also know, from the way we trimmed the staffs from the original page, that the distance between the staff lines in the resized image is fixed - and is $\delta = 10$.
PitchNumber calculates the distance from the note centroid to the bottom of the staff, normalizing by half of the distance between the staff lines. PitchToLetter finds the name for the given output of PitchNumber in relation to some reference pitch.

PitchNumber[noteCentroid_, \[Delta]_, bottom_] := (noteCentroid[[2]] - bottom)/(0.5 \[Delta])
naturalNotes =
Flatten[Table[# <> ToString[i] & /@ {"A", "B", "C", "D", "E", "F", "G"}, {i, 1, 7}], 1]
PitchToLetter[pitchNumber_, referenceNumber_, referenceLetter_] :=
RotateLeft[naturalNotes,
FirstPosition[naturalNotes, referenceLetter] - 1][[
Round[pitchNumber - referenceNumber] + 1]]
Basic Parsing
In this case, the parsing is a simple sorting - there are no dynamics, articulation or even accidentals taken into consideration.
ParseSheetMusic[pitchedNotes_, rests_] :=
SortBy[Join[pitchedNotes, restsNotation], NotationCentroid[#][[1]] &]
In the end, this is our final result:
{SheetMusicNote[{66.5, 64.}, "B5"],
SheetMusicRest[{97., 45.5}, "restHBar"],
SheetMusicRest[{97.5, 64.5}, "restHalf"],
SheetMusicNote[{121., 64.}, "B5"],
SheetMusicNote[{159., 64.}, "B5"],
SheetMusicNote[{196.5, 64.}, "B5"],
SheetMusicRest[{287., 49.5}, "rest32nd"],
SheetMusicNote[{327.5, 50.}, "F4"],
SheetMusicNote[{366., 59.5}, "A5"],
SheetMusicRest[{456., 75.}, "restQuarter"]}


