Introduction
The purpose of this project is to find out the most common word in Marathi and then use the data to obtain some interesting results. The core of this project was to build a database of the Marathi Words from articles that were present online i.e, in this case, Wikipedia Marathi. But this code can also be used for any other website with some tweaks in the code.
Importing Data from Wikipedia
wikLinks =
Cases[xml,
XMLElement[
"a", {___, "href" -> articleLink_, ___,
"title" -> title_, ___}, _] :> {
title,
With[{ss = StringSplit[articleLink, "/"]},
Block[{decoded, url},
decoded = URLDecode[ss[[2]]];
If[StringMatchQ[ss[[1]], "wiki"],
url = StringJoin@Riffle[{ss[[1]], decoded}, "/"];
"https://mr.wikipedia.org/" <> url
]
]
]
}, Infinity];
mrWikiLinks = DeleteCases[wikLinks, {_, Null}];
test = Import[#[[2]], "Plaintext"] & /@ mrWikiLinks;
The given function imports data from the Marathi Wikipedia by searching for the XML objects and the hyperlinks. To get the data we wanted we had to inspect the Wikipedia Source. Also since the XML Element only contains the link to their server we had to append the link such that it could also be opened from a browser. Then we had to delete the null cases that were generated during importing the data. Since only the second element of the URL is needed while importing, parting the string was the only way to import the data. So after importing it in plaintext, we stored it in a list.
Splitting the data into words
Since the data is being imported in sentences it needed to be converted into words to compute them.
newList3 = TextWords@newList2
Where newList2 is the list which was used to remove the whitespace characters which were generated during importing the data. So to remove them we have to map Text Words over newList2 so that the list is converted to individual words.
Appending the list
Since stopwords tend to be used more in a language we have to divide it into two cases. With and without stop words.
newList4 =
DeleteCases[newList3 // Flatten, Alternatives @@ stopwords] //
DeleteCases[#, WhitespaceCharacter .. ] &;
d = Select[
newList4, !
StringContainsQ[Alternatives @@ Alphabet[]][ToLowerCase[#]] &];
Where newList3 is the text words list. To evaluate the list we have to flatten it i.e merge all of the lists together and then find the stopwords and remove them. Then assign the list to a new variable and remove the English Words that were generating during importing the data. To do that we have to convert all of the words to lower case and then remove them.
Finding out the frequency of the words
FinalList = d // Counts // ReverseSort;
The list that was previously generated has been completely sorted with all of the English Words removed after this we have to count the individual words and then reverse sort them so that we get the individual values.
Graphical Representation of the Data
To generate an image that can be used to understand the data generated in a glance we have to generate a WordCloud (visual representation of text data), and a dataset that sorts the data in a table.
WordCloud[d] (*generated without the stopwords*)
WordCloud[sortedList] (*generated with stopwords*)
Where sortedList is the list of words generated after flattening and sorting the newList3. You may find some English words in them but they are generated because they cannot be converted.


Generating a Dataset
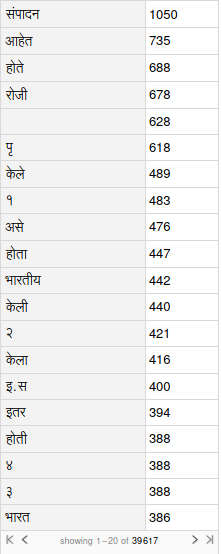
To see the data generated in a tabular form we have to use a Wolfram Syntax that is:
FinalList // Dataset
If you observe closely in the dataset there are whitespace characters counted as well. I was not able to remove it from the dataset, I tried to remove it using the whitespace character syntax but it does not work.
Conclusion
We conducted this project to find out the most commonly used words in Marathi. Marathi is a regional language spoken in Western parts of India. We found the most used words in Marathi and then stored them in a dataset and found out the data that we were expecting. We then created a WordCloud and a dataset to get a graphical representation and it was fascinating to watch all of them. I would like to thank Fez for all the help he gave me in completing my project, along with the other mentors. I would also like to thanks Dr. Wolfram, Mads and Kyle, and the Wolfram High School Summer Camp for the opportunity to become engaged in such an adventure, and one that will remain with me for years to come.
If you want to download my project notebook please redirect to my GitHub link.


