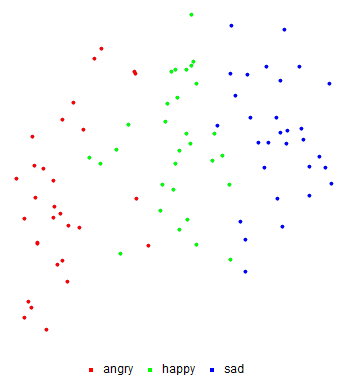
Figure Above: Feature Space Plot for speech data
Abstract
In this project, I aim to design a system which is capable of detecting mood in human speech. Specifically, the system can be trained on a single user's voice given samples of emotional speech labeled as being angry, happy, or sad. The system is then able to classify future audio clips of the user's speech as having one of these three moods. I collected voice samples of myself and trained a Classifier Function based on this data. I experimented with many different available methods for the Classifier Function and for audio preprocessing to obtain the most accurate Classifier.
Obtaining Data
In this project, I focused on detecting mood for only one user (specifically, myself) since different people may express mood in different ways, leading to confusion for the Classifier. I initially recorded ten speech clips in each mood as training data, and ten different clips in each mood as testing data. I used Audacity to record audio clips in 32-bit floating point resolution, exported as WAV files. If you're looking to replicate this project, you can use your own data, or use mine, available on my GitHub repository. I later recorded additional clips, as discussed below.
Feature Extraction
In order to produce the most accurate Classifier, I extracted features which I thought were most useful to detecting mood. Specifically, I extracted the amplitudes, fundamental frequencies, and formant frequencies of each clip over the length of the clip using AudioLocalMeasurements. That is, I took multiple measurements of each of these values, over many partitions of the clip. I partitioned each clip into 75 parts, but feel free to experiment with different values. I also found the word rate, using Wolfram Language's experimental SpeechRecognize function, and the ratio of pausing time to total time of the clip using AudioIntervals. The final function takes the location of the audio file (could be local or on the web) and the number of partitions, and returns an association with the extracted features. It's important that the function return an association, since this makes things much easier when constructing the Classifier Function. The initial function for feature extraction is included below.
extractFeatures[fileLocation_, parts_] :=
Module[{audio, assoc, pdur, amp, freq, form},
audio = Import[fileLocation];
pdur = AudioMeasurements[audio, "Duration"]/parts;
amp = AudioLocalMeasurements[audio, "RMSAmplitude",
PartitionGranularity -> pdur] // Normal;
freq = AudioLocalMeasurements[audio, "FundamentalFrequency",
MissingDataMethod -> {"Interpolation", InterpolationOrder -> 1},
PartitionGranularity -> pdur] // Normal;
form =
AudioLocalMeasurements[audio, "Formants",
PartitionGranularity -> pdur] // Normal;
assoc = <|
Table["amplitude" <> ToString[i] -> amp[[i]][[2]], {i, Length[amp]}],
Table["frequency" <> ToString[i] -> freq[[i]][[2]], {i, Length[freq]}],
"wordrate" ->
Length[TextWords[Quiet[SpeechRecognize[audio]]]]/
AudioMeasurements[audio, "Duration"],
Table[Table["formant" <> ToString[i] <> "-" <> ToString[j] ->
form[[i]][[j]], {j, Length[form[[i]]]}], {i, Length[form]}],
"pauses" ->
Total[Abs /@ Subtract @@@ AudioIntervals[audio, "Quiet"]]/
AudioMeasurements[audio, "Duration"]
|>;
Map[Normal, assoc, {1}]
]
Get Training Data
Using this function, I was able get the features for all of my training data. Here, I'll import my data from my GitHub repository.
angryTrainingFeats =
Table[extractFeatures[
"https://github.com/vedadehhc/MoodDetector/raw/master/AudioData/
TrainingData/angry" <> ToString[i] <> ".wav", 75], {i, 10}];
happyTrainingFeats =
Table[extractFeatures[
"https://github.com/vedadehhc/MoodDetector/raw/master/AudioData/
TrainingData/happy" <> ToString[i] <> ".wav", 75], {i, 10}];
sadTrainingFeats =
Table[extractFeatures[
"https://github.com/vedadehhc/MoodDetector/raw/master/AudioData/
TrainingData/sad" <> ToString[i] <> ".wav", 75], {i, 10}];
Get Testing Data
I also imported my testing data in the same way, so that it could be passed as an argument to the Classifier Function. I'll get this from GitHub as well. Note that this is the regular test data on GitHub.
angryTestingFeats =
Table[extractFeatures[
"https://github.com/vedadehhc/MoodDetector/raw/master/AudioData/
TestingData/Regular/a" <> ToString[i] <> ".wav", 75], {i, 10}];
happyTestingFeats =
Table[extractFeatures[
"https://github.com/vedadehhc/MoodDetector/raw/master/AudioData/
TestingData/Regular/h" <> ToString[i] <> ".wav", 75], {i, 10}];
sadTestingFeats =
Table[extractFeatures[
"https://github.com/vedadehhc/MoodDetector/raw/master/AudioData/
TestingData/Regular/s" <> ToString[i] <> ".wav", 75], {i, 10}];
Training a Classifier
I constructed a Classifier Function using Classify.
classifier =
Classify[<|"angry" -> angryTrainingFeats,
"happy" -> happyTrainingFeats, "sad" -> sadTrainingFeats|>,
Method -> "LogisticRegression"]
I ran the classifier on each set of training data.
classifier[angryTrainingFeats]
classifier[happyTrainingFeats]
classifier[sadTrainingFeats]
I experimented with all of the built-in options for Method to construct a Classifier Function with the best accuracy. I found that LogisticRegression gave the best accuracy at 77% accuracy on the test data. However, I wanted to improve the accuracy further.
Audio Pre-Processing
One of the things that improved the Classifier's accuracy substantially was cleaning the audio before extracting features and classifying. Specifically, I trimmed the audio using AudioTrim, and filtered each clip using HighpassFilter before extracting features. The audio cleaning function is included below.
cleanAudio[fileLocation_] := Module[{audio, trimmed, filtered},
audio = Import[fileLocation];
trimmed = AudioTrim[audio];
filtered = HighpassFilter[trimmed, Quantity[300, "Hertz"]]
]
New Feature Extraction Function
I updated the feature extraction function to include audio cleaning.
extractCleanFeatures[fileLocation_, parts_] :=
Module[{audio, assoc, pdur, amp, freq, form},
audio = cleanAudio[fileLocation];
pdur = AudioMeasurements[audio, "Duration"]/parts;
amp = AudioLocalMeasurements[audio, "RMSAmplitude",
PartitionGranularity -> pdur] // Normal;
freq = AudioLocalMeasurements[audio, "FundamentalFrequency",
MissingDataMethod -> {"Interpolation", InterpolationOrder -> 1},
PartitionGranularity -> pdur] // Normal;
form =
AudioLocalMeasurements[audio, "Formants",
PartitionGranularity -> pdur] // Normal;
assoc = <|
Table[
"amplitude" <> ToString[i] -> amp[[i]][[2]], {i, Length[amp]}],
Table[
"frequency" <> ToString[i] -> freq[[i]][[2]], {i, Length[freq]}],
"wordrate" ->
Length[TextWords[Quiet[SpeechRecognize[audio]]]]/
AudioMeasurements[audio, "Duration"],
Table[
Table["formant" <> ToString[i] <> "-" <> ToString[j] ->
form[[i]][[j]], {j, Length[form[[i]]]}], {i, Length[form]}],
"pauses" ->
Total[Abs /@ Subtract @@@ AudioIntervals[audio, "Quiet"]]/
AudioMeasurements[audio, "Duration"]
|>;
Map[Normal, assoc, {1}]
]
New Results
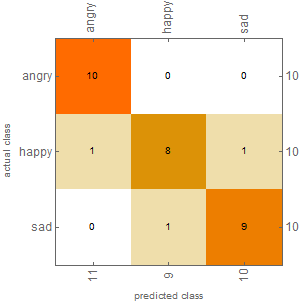
Using audio cleaning, the accuracy of the classifier improved to 90%, much better than before. The results can be seen in the Confusion Matrix Plot below, generated using ClassifierMeasurements.
Testing with Neutral Statements
Now, up until now, the statements used for recordings were all emotional in nature. For example, the clips recorded in an angry mood also had an angry statement being said. In order to control for this, I recorded neutral statements in each mood. That is, I recorded each of ten emotionally neutral statements in each of the three moods. If the Classifier still works on this data, that would show that it is not relying on the content of the speech, but on other audio features, which is the intended method. I imported these data using the clean feature extractor and, once again, I'll download them from my GitHub here. Note that this is the Neutral Statements data.
nAngryCleanTestingFeats =
Table[extractCleanFeatures[
"https://github.com/vedadehhc/MoodDetector/raw/master/AudioData/
TestingData/NeutralStatements/a" <> ToString[i] <> ".wav", 75], {i,
10}];
nHappyCleanTestingFeats =
Table[extractCleanFeatures[
"https://github.com/vedadehhc/MoodDetector/raw/master/AudioData/
TestingData/NeutralStatements/h" <> ToString[i] <> ".wav", 75], {i,
10}];
nSadCleanTestingFeats =
Table[extractCleanFeatures[
"https://github.com/vedadehhc/MoodDetector/raw/master/AudioData/
TestingData/NeutralStatements/s" <> ToString[i] <> ".wav", 75], {i,
10}];
Results for Neutral Statements
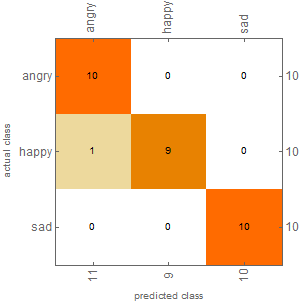
I ran the clean Classifier on the new data, and the results were very positive. The classifier achieved an accuracy of 97% on the Neutral Statements data. The results are displayed in the Confusion Matrix Plot below, generated using ClassifierMeasurements.
Conclusions
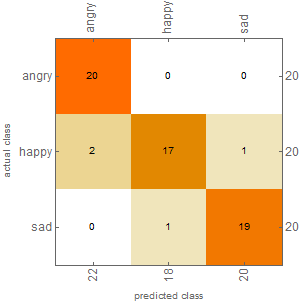
Overall, the Classifier was able to identify mood at 93% accuracy, even when the same statements were spoken in different moods. The composite Confusion Matrix Plot for all testing data can be seen below.
Future Work
In the future, I hope to improve the accuracy of the Classifier by providing additional training data, and to test it further with additional testing data. I also hope to expand the range of moods that the Classifier handles, including moods such as fear, calmness, and excitement. This, of course, would require the aforementioned additional data, and perhaps, more complex structures for the Classifier Function. In the future I would also like to experiment with multiple speakers, and determine whether classifiers for one speaker's moods can be used to determine those of another speaker.
Acknowledgements
I would like to thank my mentor Faizon Zaman for his guidance and assistance on this project.
GitHub
You can find my code for this project on my GitHub repository, with all code available beginning July 12th, 2019.


