Hello Guillermo,
The data is in XML format (representing a spreadsheet) but Import doesn't know that. If you provide "XML" as the second argument to Import, it works fine. However dealing with spreadsheet XML is not fun. As HTML is kind of a derivative of XML I tried with Import["the url","HTML"] and it works! So you just need to do some string processing after that to get the data in a useful way.
The first step is importing the data as a string:
s = Import[
"https://analisis.datosabiertos.jcyl.es/explore/dataset//situacion-de-hospitalizados-por-coronavirus-en-castilla-y-leon//download/?format=xls&timezone=Europe/Madrid&lang=es&use_labels_for_\\header=true",
"HTML"
]
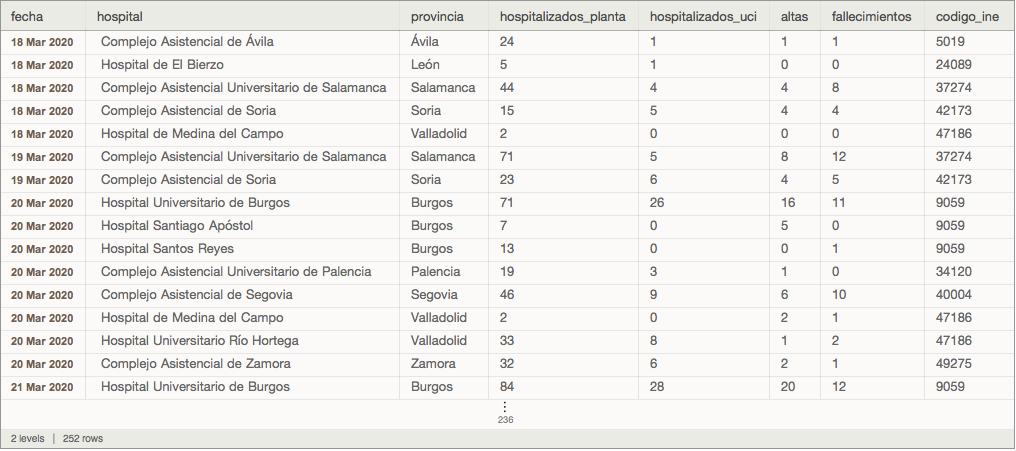
(* fecha hospital provincia hospitalizados_planta hospitalizados_uci altas fallecimientos codigo_ine 2020-03-18 Complejo Asistencial de Ávila Ávila 24 1 1 1 5019 2020-03-18 Hospital de El Bierzo León 5 1 0 0 24089 (...etc...) 2020-04-04 Hospital Universitario Río Hortega Valladolid 157 51 244 58 47186 *)
Then we separate the header from the data, convert the date, split and partition:
{header, data} = StringSplit[s, d:DatePattern[{"Year","Month","Day"}] :> DateObject[d]] //
{First /* StringSplit, Rest /* (Partition[#, 2] &) } //
Through
and finally we can use a carefully crafted string expression to separate the strings into fields so that we can convert to a dataset:
ds =
Map[
StringCases[
#[[2]],
f1:Except[DigitCharacter]..~~" "~~
f2:WordCharacter..~~" " ~~
f3:NumberString~~" " ~~
f4:NumberString~~" " ~~
f5:NumberString~~" " ~~
f6:NumberString~~" " ~~
f7:NumberString :> AssociationThread[header->{#[[1]],f1,f2,f3,f4,f5,f6,f7}]
] &,
data] //
Flatten //
Dataset