Abstract: This project utilized the Wolfram Language to automate the processing of 10-K reports from domestic technology and biotechnology companies. It automates data gathering and analysis via interfacing with SEC's EDGAR service for public company reporting, extraction of Company names mentioned in annual reports (10-K filings) and allows for a graphical representation of the industry network via these mentions. Additionally, given some manual processing, an exploration of the most salient details of deals with companies mentioned in 10-Ks can be extracted.
~
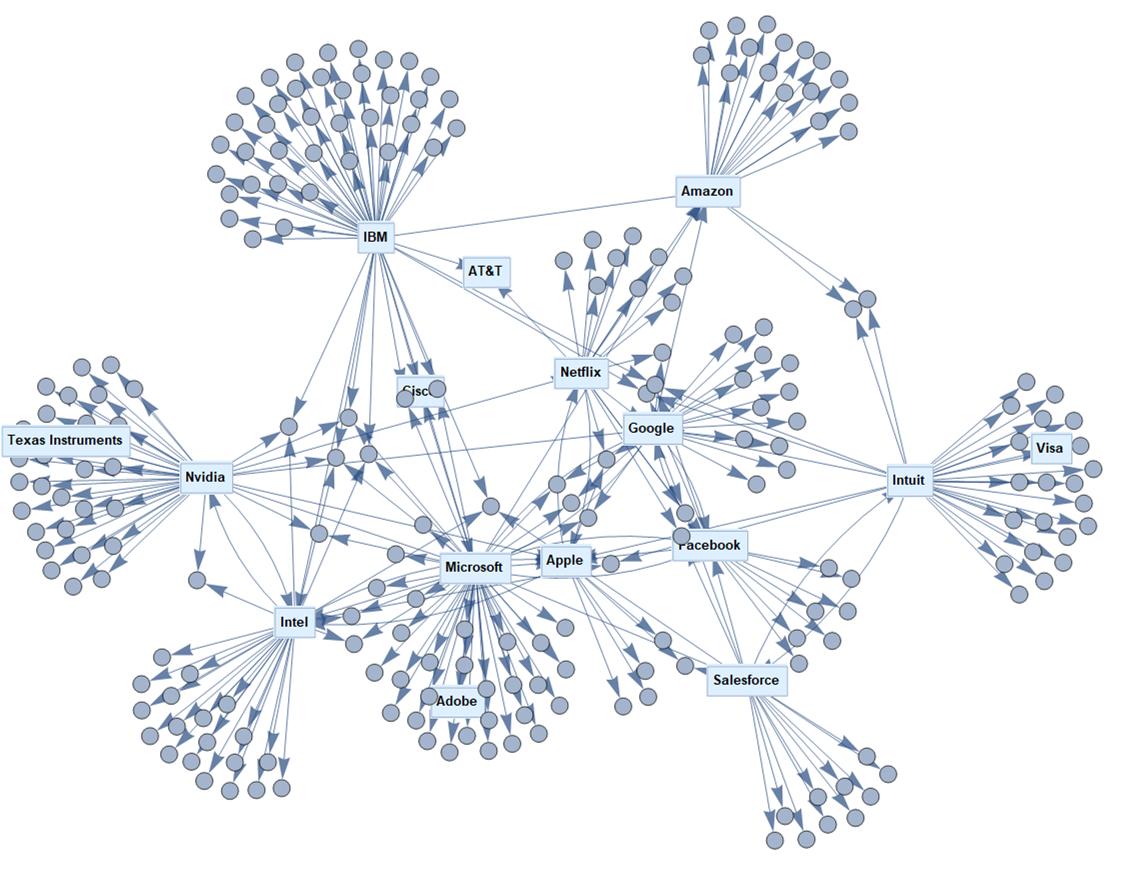
Below is a graph of 2013's technology industry connections (as measured by mentions in 10-K reports in named companies). Each vertex represents an entity judged to be a company by an algorithm that can be called via the TextCases[] function.
In[21]:= TextCases["I love Netflix, they have great movies \
sometimes!", "Company"]
Out[21]= {"Netflix"}
Goals: The project goals were to assist with the interpretation and analysis on 10-K filings by domestic corporations. Specifically automating the retrieval of reports from multiple years, extracting information from the downloaded files, and organizing the result into individual company mentions, and for the biotechnology/pharmaceutical companies munging the relevant deal information.
Results: Given some manual curation of partner names a rich graph of biotech company deals was generated (from 2019 data, below), the deal specifics were interrogated using natural language query FindTextualAnswer[] function and then compiled into association lists with several details.
In[23]:= FindTextualAnswer["I ate cheese today, and drank some \
water.", "What did I eat today?"]
Out[23]= "cheese"
Using FindTextualAnswer[] after the manual curation of Merck's partner names generated associations with specific deal information, as seen below (hover for tooltips with more information):  Difficulties: While scaling the original functions focused on extracting information on biotech deals, the memory usage and processor intensity of the FindTextualAnswer[] function proved to be suboptimal for running on a personal computer. Also, the imports of the 10Ks as XMLObjects proved difficult due to memory requirements and time-constraints on processing and GPU acceleration had only variable success.
Difficulties: While scaling the original functions focused on extracting information on biotech deals, the memory usage and processor intensity of the FindTextualAnswer[] function proved to be suboptimal for running on a personal computer. Also, the imports of the 10Ks as XMLObjects proved difficult due to memory requirements and time-constraints on processing and GPU acceleration had only variable success.
Full Notebook can be found at:
https://www.wolframcloud.com/obj/iosifmg/Published/IMG-10K.nb


