Previous report introduced a parallel computing environment with ZMQ connection. Wolfram language code for Multi core computing was also reported. In this report, I'd like to introduce the Mathematica Multi-Node Multi-Core Parallel computing system combined prior trials and the system is composed of software key components, Object Oriented Programming, master/local ZMQ node, and the Association function.
Following sample code runs on a Master-Node of Raspberry Pi Zero and a Local-Node of Raspberry Pi 4B which has 4 cores.
Figure 1 shows the outline of this parallel computing system. Master and Local-Nodes have interconnections provided by ZMQ. A Service PC, in this case Mac, provides X11 service and is connected to the router providing DHCP services. The local net is constructed with USB-OTG between the Service PC and the multiple Raspberry Pi. In this sample, a Master-Node is prepared by a Raspberry Pi Zero, and one Local-Node is prepared by a Raspberry Pi 4B which is 4 core machine.
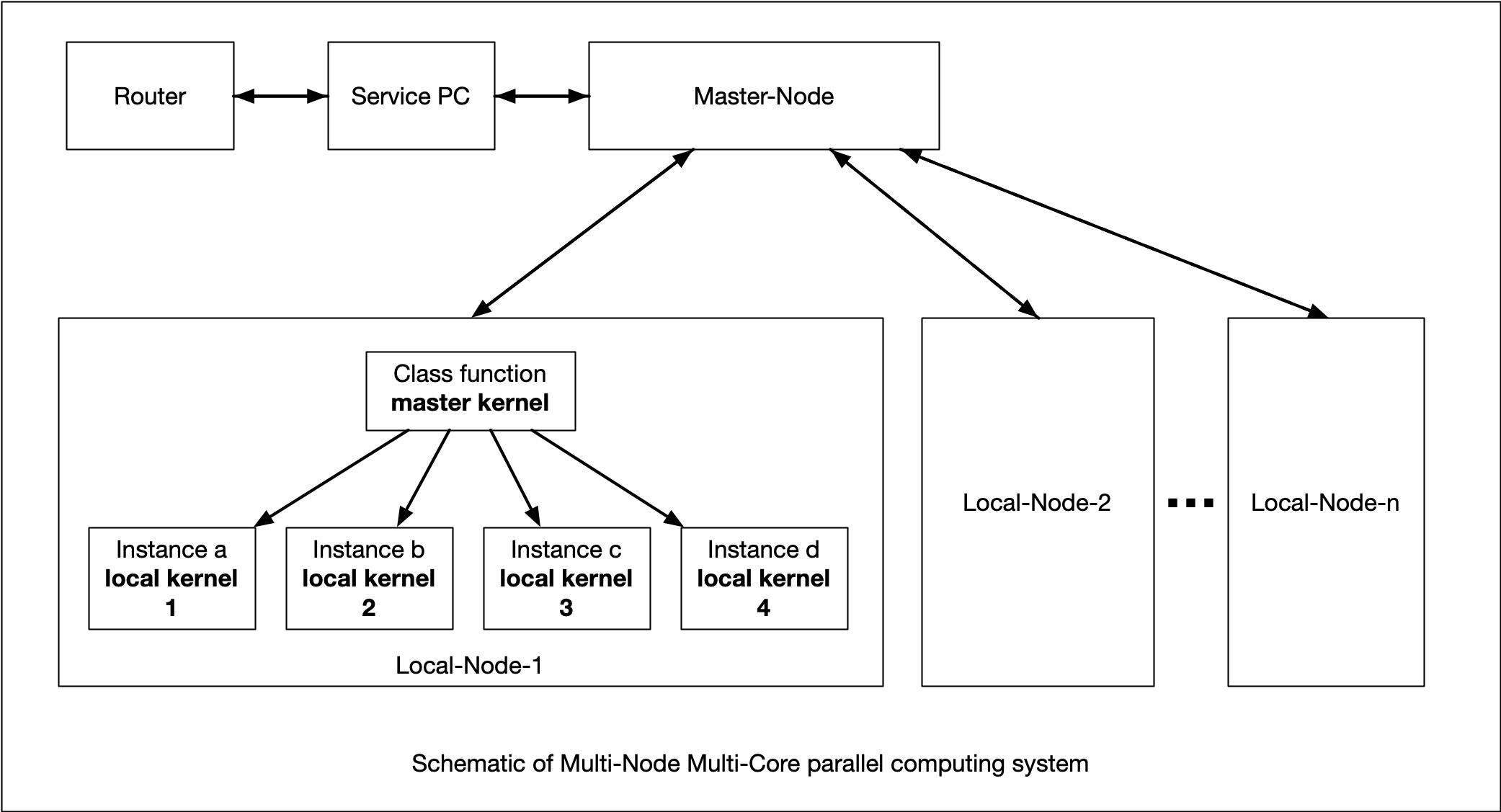
Followings are step by step sample code of the parallel computing system using Object Oriented Programming method. Where, the name of Raspberry Pi Zero is RaspberryPi7, and the name of Raspberry Pi 4B is RaspberryPi11. Each Raspberry Pi must have USB OTG. In this report, parallel Mersenne-Number calculation is a target to explain the parallel computing scheme.
Step 1 for Master and Local: preparing Raspberry Pi
imac : ~user$ ssh - X pi@RaspberryPi7.local
pi@raspberrypi7 : ~$ mathematica &
and
imac : ~user$ ssh - X pi@RaspberryPi11.local
pi@raspberrypi11 : ~$ mathematica &
Step 2 on Master: getting ip of Master-Node
HostLookup["raspberrypi7.local", All]
Step 3 on Master: opening the socket with the obtained ip with arbitrary port number, here, 40001
client1 = SocketOpen[{"192.168.1.10", 40001}, "ZMQ"]
Step 4 on Local: connecting to the Server socket, named "server"
server = SocketConnect[{"raspberrypi7.local", 40001}, "ZMQ"]
Step 5 on Local: setting a Socket-Listener that is the final set up for the Local-Node
listener =
SocketListen[server, (WriteString[server, ToExpression[#Data]]) &]
Step 6 on Master: deployment of a code to Local-Node that wakes up local cores
WriteString[client1, "LaunchKernels[];
kernelList = ParallelEvaluate[$KernelID];
{nk = Length[kernelList], kernelList}"];
ByteArrayToString[SocketReadMessage[client1]]
Step 7 on Master: deployment of a code of Class named "parallelClass" to Local-Node
WriteString[client1,
" parallelClass[nam_] := Module[{myID = nam, ins, ine},
nam[set[{ns_, ne_}]] := {ins, ine} = {ns, ne};
getID[] := myID;
nam[getStatus] := {ins, ine};
go[] := Select[Range[ins, ine], PrimeQ[2^# - 1] &]
]"];
ByteArrayToString[SocketReadMessage[client1]]
Step 8 on Master: deployment of a code of the Association is defined for the calculation parameter for each core
WriteString[client1, "object = {
Association[\"name\" -> Unique[k], \"range\" -> {9000, 9399},
\"kernel\" -> kernelList[[1]]],
Association[\"name\" -> Unique[k], \"range\" -> {9400, 9699},
\"kernel\" -> kernelList[[2]]],
Association[\"name\" -> Unique[k], \"range\" -> {9700, 9899},
\"kernel\" -> kernelList[[3]]],
Association[\"name\" -> Unique[k], \"range\" -> {9900, 10000},
\"kernel\" -> kernelList[[4]]
]}"];
ByteArrayToString[SocketReadMessage[client1]]
Step 9 on Master: let the Local-Node to deploy the instance for each core
WriteString[client1,
"Map[ParallelEvaluate[ parallelClass[#name], #kernel] &, object]"];
ByteArrayToString[SocketReadMessage[client1]]
Step 10 on Master: starting calculation on cores of Local-Node
WriteString[client1, "ts = SessionTime[];
ans = ParallelEvaluate[go[]];
{SessionTime[] - ts, ans}"];
ByteArrayToString[SocketReadMessage[client1]]
Step 11 results appeared on Master: Master-Node obtains the calculated result arrived on the socket
{242.348749, {{}, {9689}, {}, {9941}}}
The result shows that the consumed time and the Mersenne number found. You can confirm the results as follows.
{PrimeQ[2^9689 - 1], PrimeQ[2^9941 - 1]}
You can make above lengthy code to more easy and compact OOP code, and can expand very easily to the parallel computing system composed of more number of Local-Nodes. In the future system however, the network become not USB-OTG but powered Ether network considering the stability of power source and the network speed.
Enjoy and imagine, Ryzen multi node Wolfram environment.


