Its a graphical and, of course a copyright problem.
You will find the character sets, loaded by the system, only, and from these a subset is defined in Mathematica as belonging to some
$CharacterEncodings.
Most characters are the Chinese some 100000 in different styles and variants (Honkong, Taiwan, Simplified) plus language systems from all cultures with an own letter system . I load the Chinese keyboard layouts in Windows, needed to have OCR capabillities .
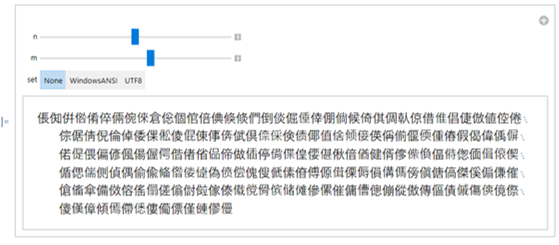
I once made an overview Manipulate in order to fast find Chinese characters on paintings by scrolling through the sets
Manipulate[ With[{n = 16^Floor[n] + 4^Floor[m]},
Quiet[FromCharacterCode[Range[n, n + 200 ], set]]],
{{n, 3}, 0, 6}, {{m, 7}, 0, 12}, {set, {None, "WindowsANSI", "UTF8"}}]