Motivation
While sipping my morning energy drink today, I was browsing my old archived backups and I came across some MP3 files from a 5 to 10 years ago, a time when music streaming services were nascent and offline music was the norm. I browsed through the archive and listened to some of my favorites from that time. After sometime, I realized that when I played in Autoplay mode, the music queue was very randomized. 10 years ago this was fine but now I've got used to listening similar tracks unless I manually change. So I thought:
Hey! let's design a music recommendation system, and let's use Mathematica to do it fast!
MP3 Metadata
First, I use exiftool to extract all the metadata of the music files and exported them to a CSV file:
exiftool - csv ~/music_archive/ > metadata . csv
csv = Import["~/metadata.csv"];
Dimensions[csv]
headers = csv[[1]]
The CSV file has 249 rows and 75 columns. The first row contains the field headers and the rest contain the actual metadata. There are 75 fields. But we don't need all. For this task, I have picked the following headers as these would be sufficient for my small music collection:
I thought of using the Composer and Year fields as well, but most rows did not have an entry for these fields. Next, I extract the position of these fields and extract the data with respect to these fields
fields = Position[headers, #] & /@ {"Album", "Artist", "Genre", "Title"} // Flatten
data = csv[[2 ;;, fields]];
At this point, I also extract the titles for use later: titles = data[[All, 4]];
Encoders
Now that I have the data, I needed a way to represent them numerically in order to further proceed. One simple way is to encode all discrete values as "One-Hot vectors". This encoding ensures that there are no inherent bias or ordinal relationships between the numerically encoded discrete values. But before encoding, I needed to extract all the unique values for each fields.
Albums
albums = data[[All, 1]] // DeleteDuplicates // Sort;
albums // Length
In my music collection, there 144 unique albums. This means that my encoder for album would produce a vector of length 144. Let's create that:
albumsEncoder = NetEncoder[{"Class", albums, "IndicatorVector"}];
Similarly, I create encoders for Artists and Genres.
Artists
artists = StringDelete[#, " - MassTamilan.org"] & /@ StringSplit[#, {"/", ", "}] & /@
data[[All, 2]] // Flatten // DeleteDuplicates // Sort;
artists // Length
There are 186 unique artists in my music collection ... Interesting ...
artistsEncoder = NetEncoder[{"Class", artists, "IndicatorVector"}];
Note that there is StringSplit function used. This is because a single track may have multiple artists.
Genre
genre = DeleteMissing[(ToLowerCase /@ (StringSplit[#, "/"] & /@
data[[All, 3]] // Flatten) // DeleteDuplicates) /. {"" -> Missing[]}] // Sort; genre // Length
And finally, there are 50 genres in my collection. Here, in addition to the use of StringSplit, I've also used DeleteMissing in order to deal with some instances that did not have a genre entry.
genreEncoder = NetEncoder[{"Class", genre, "IndicatorVector"}];
Feature Encoding
Now that I've created all the encoders, I'll take the data for each field and encode them.
Album
albumsData = data[[All, 1]];
albumsVector = albumsEncoder[albumsData];
Artist
In case of Artists, a single track may have multiple artists. To deal with this, I encoded each artist for a given track and then sum the two encoded vectors. This is done with the helper function encodeArtists: artistsData = StringSplit[#, {"/", ", "}] & /@ data[[All, 2]] encodeArtists[artists_] := Plus @@ artistsEncoder[artists] artistsVector = encodeArtists[#] & /@ artistsData;
Genre
Similar to artists, multiple genres for a given track are dealt by summing the encoded vectors of its individual genres. However, an additional challenge here is to deal with the missing values. For this, since the encoding function returns 0 for this, I just convert them to list and pad more zeros to make their length consistent. genreData = ToLowerCase[ StringSplit[#, "/"] & /@ data[[All, 3]]]; encodeGenre[genreList_] := PadRight[Flatten@{Plus @@ genreEncoder[genreList]}, Length[genre]] genreVector = encodeGenre[#] & /@ genreData;
Feature aggregation and embeddings
Now that the fields have been converted to feature vectors, they can be flattened for each instance: features = Flatten /@ Transpose[{albumsVector, artistsVector, genreVector}]; features // Dimensions The result is a {248, 300} array which means 248 examples and each example has 380 features, which isn't very bad for further computation but can be challenging to interpret. So I'm going to reduce this to just 3 dimensions because then it wold be very convenient to visualize and draw interpretations. For dimensionality reduction, I have used "t-SNE" because it preserves the local relationships between data points i.e. it preserves clusters to certain degree.
features3D = DimensionReduce[features, 3, Method -> "TSNE"];
ListPointPlot3D[features3D]
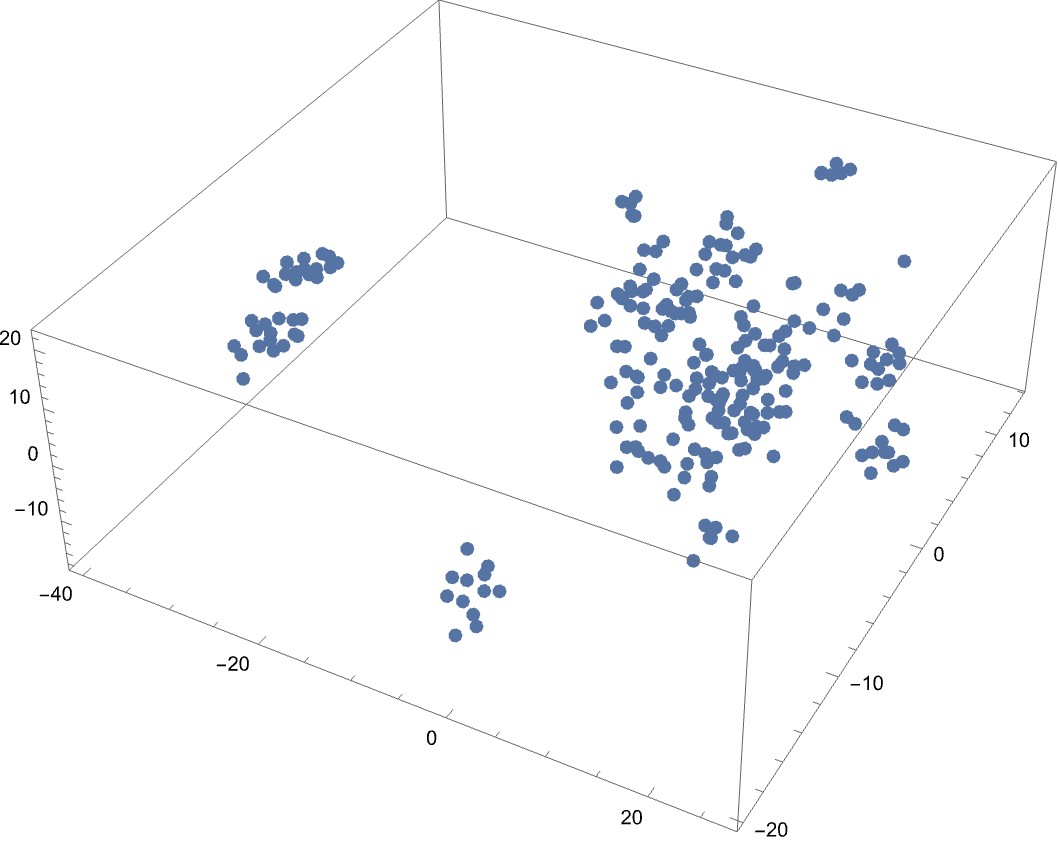
The visualization is very interesting because it indicates that there are several clusters. The obvious interpretation is that points in the same cluster have high degree of similarity.
Distance computation... and the Recommendations
Given a track, the goal is to identify tracks that are similar to it i.e. given the feature vector of a track, we want to identify n other feature vectors that are closest to it. For simplicity, let's assume here n=5. There are several distance metrics for vectors but I found the cosine distance and the Euclidean distance to give the best results. To begin with the experiment, I'm going to pick a random feature vector and see what song it corresponds to.
In[83]:= sample = RandomChoice[features3D];
Position[features3D, sample]
Out[84]= {{209}}
In[87]:= titles[[209]]
Out[87]= "I'm an Albatraoz"
So the random choice picked here is "I'm an Albatraoz" by Aron Chupa and Lil Sis Nora. This song is very popular and can be classified as a party/pop/rock type.
CosineDistance
Now I compute the cosine distance between the sample and all the other vectors, and then pick 5 which have the smallest distance. In case of Cosine distance, the value ranges from 0 to 2, 0 meaning the vectors are along the same direction and close and 2 meaning the vectors are pointing diametrically opposite.
In[99]:= cosineDistances = CosineDistance[sample, #] & /@ features3D;
top5Cosine = Sort[cosineDistances][[2 ;; 6]];
top5CosineIndex = Flatten[Position[cosineDistances, #] & /@ top5Cosine];
titles[[#]] & /@ top5CosineIndex
Out[102]= {"Little Swing", "Trombone", "Rave in the Grave", \
"Tequila", "Kinare"}
The cosine distance works wonderfully. It has picked up 4 songs out of 5 which belong to the same artist and are of same party/pop/rock type. The last song is a Bollywood rock song. Thus this distance metric works wonderfully for my small dataset.
EuclideanDistance
Let' s try and see if Euclidean Distance also gives similar or better results.
In[107]:=
euclideanDistances = EuclideanDistance[sample, #] & /@ features3D;
top5Euclidean = euclideanDistances // Sort;
top5EuclideanIndex = Flatten[Position[euclideanDistances, #] & /@ top5Euclidean][[2 ;; 6]];
titles[[#]] & /@ top5EuclideanIndex
Out[110]= {"Trombone", "Little Swing", "Tequila", "Rave in the Grave", "Llama In My Living Room"}
The Euclidean distance works even better. It has picked up all the 5 songs which are by the same artist.
Conclusion
Now that I've come up with a neat model that can compute similar tracks, I will write a script that will generate m3u files. One important thing to note is that when the computed distances are sorted, the instances that occur latter may not necessarily be similar to the initial sample and most certainly not similar to its neighboring instances. Therefore there needs to be a recalibration done after, say, every 5 or 10 tracks in order to obtain tracks that are similar to one that index. I also plan to extend this script such that it can generate playlist from input values combinations such as artist name, genre instead of a song. But that's a project for another weekend.


