HedgeHog
AI multi-agent trading system
Abstract
Hedgehog, an automated trading system based on ensemble of neural network (NN) bots. These trading bots, treated as a population, are continuously optimized by combination of reinforcement learning at individual level and genetic algorithm at population level. In particular, we utilize NEAT algorithm, which allows for automatic optimization over different neural network topologies. The selection of best-performing bots is deployed to trade. Here, we show implementation in Wolfram Mathematica, utilizing parallel computation to accelerate training process. Besides core neural-network based trading system, Hedgehog also provides integration to financial data provider and broker.
Introduction
In recent years, the use of neural network (NN) trading bots in the stock market has gained significant attention due to their potential to improve trading strategies and generate higher profits. These intelligent systems leverage the power of neural networks, a type of artificial intelligence, to analyze vast amounts of historical market data and make predictions about future market trends. 
NEAT
In the context of neural network design and training, one typically works with a fixed neural network structure, where only the weights (free parameters) of the operators in the network are optimized in the course of the training process. The NeuroEvolution of Augmenting Topologies (NEAT) algorithm NEAT , as the name suggests, goes a step beyond this standard paradigm by proposing evolutionary optimization of neural network topologies. NEAT evolves a population of NNs, which are completely characterized by a tuple of {structure, weights}, by breeding between individual NNs which operates on the structure...
Reinforcement learning of NN bot
Here, we introduce basics of reinforcement learning ... and formulate individual's learning problem: At each tick perform one of the allowed actions with a goal to maximize portfolio value and avoid margin calls...
- target is a single symbol, and considered actions BUY, SELL, HOLD,CLOSESHORT,CLOSELONG of given but fixed lot (of share)
- decision to take an action is influenced by data from a set of selected of symbols and the status of portfolio managed by the agent (NN)
- A subset of best-performing agents is persisted [in DB/file store]
- In new round, new set of agents (NNs) are proposed by evolutionary mechanism (breeding) from previous(previous round) and current best performing NNs
- This process is executed continuously over the growing set of historical data
Results
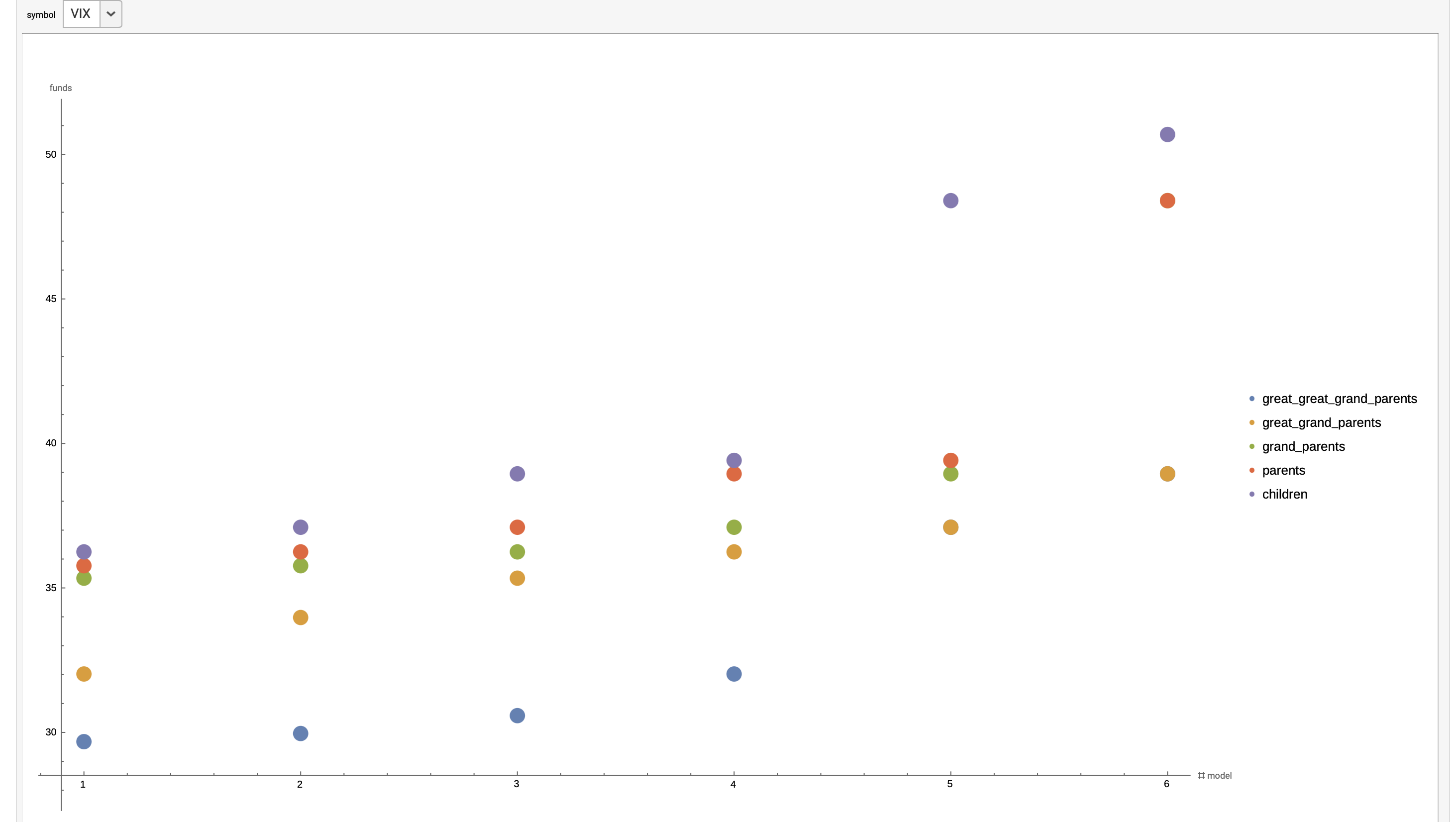
In an effort to verify the usefulness of the trained models, we subjected the models to backtesting on historical data. (see Backtesting section). Test results were aggregated (gold color) and compared with the same number of tests with a senate of random untrained models (blue color). 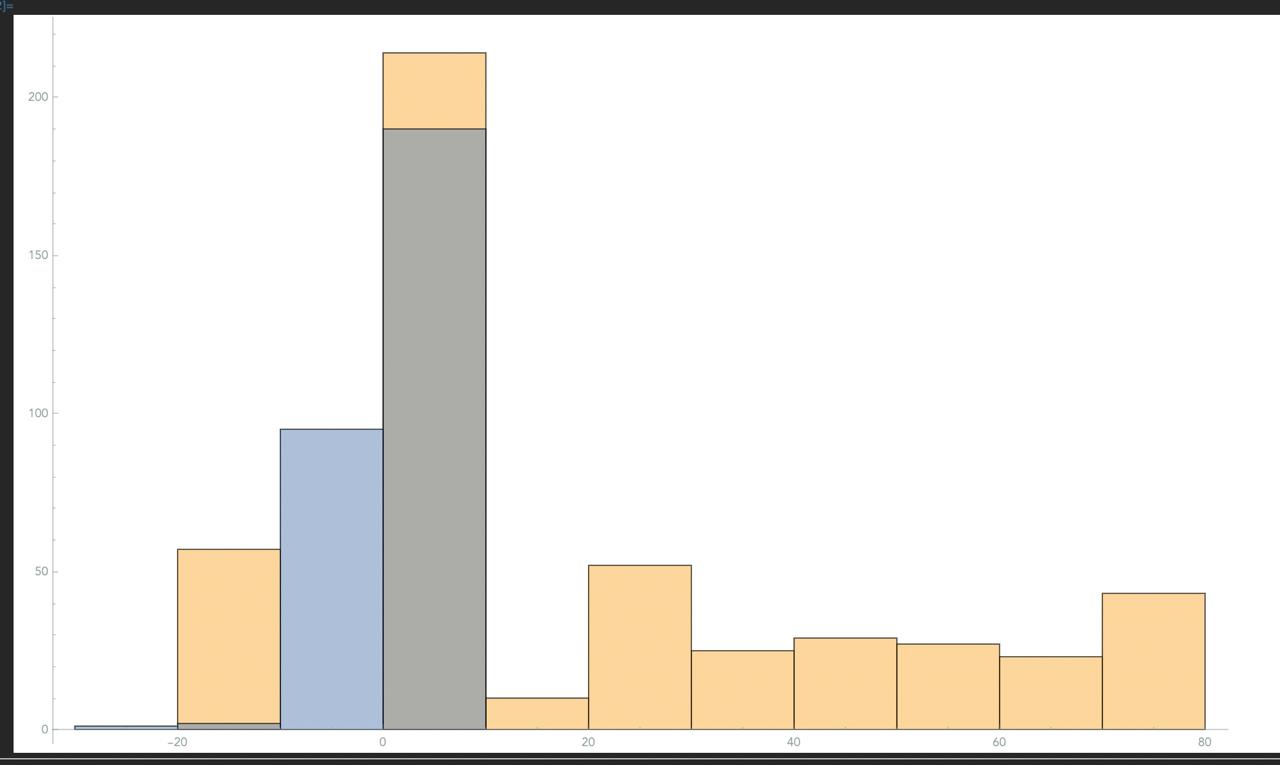 (x-axis ending profit, y-axis #cases)
(x-axis ending profit, y-axis #cases)
Backtesting
To verify the correctness and robustness of the solution, I chose two types of testing: forward testing and backward testing. In this part, I will describe the backward testing procedure and show the results from the first functional prototypes. The backward testing procedure itself is divided into several phases.
As it is important to test the robustness of the solution, the required test package is divided into three main test instances. During testing, the first instance takes into account historical data from which 150 individual random trading sessions are carried out. In the second phase, historical data is mixed with white noise corresponding to +-5% deviation and 150 individual random trading sessions are implemented. In the third phase, it occurs analogously with only +-10% deviation. The implementation of the test trading session itself proceeds as follows:
For each time stamp test, the "senate" (collective of n-models trained for a specific symbol) is offered all required inputs, then the aggregated output of all models is evaluated in the form of a vote, and the final decision is made in relation to the simulated environment. Around 450 such various tests are subsequently evaluated and archived in the cloud in the form of a simple web application.
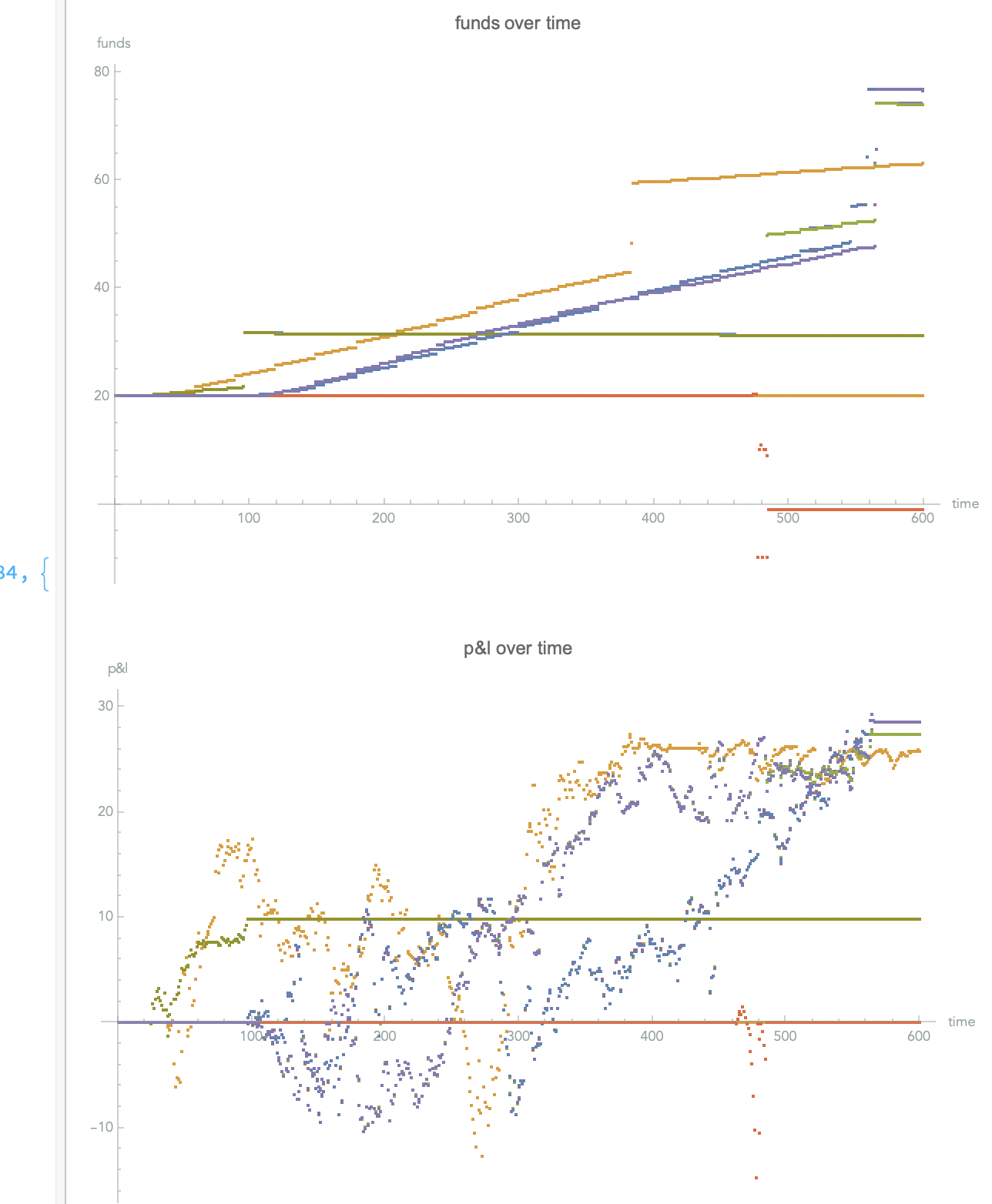
Forward testing
The second approach to forward testing required a developed API script enabling communication with the broker application enabling interactive access to the chest. in this third party application we have created a demo account and with the help of the relevant API we will interact with the "senate" of trained models. However, when reading scientific publications dealing with the problematic of traditional signals, they often turned out to be the most effective combination of different methods than just the methods themselves. Breaking this intuition, we decided that it would be more convenient to provide data from the broker (prices of monitored symbols, state of the demo portfolio) to all models independently and to interpret their individual decisions as a choice.
Assuming that the models agree in the vote on some decision (buy, sell, hold, etc.), this decision will be implemented through the API on the broker's side. The performance of the bots is actively monitored and the status is stored in the cloud in the form of an overview application the performance of the bots is actively monitored and the status is stored in the cloud in the form of an overview application.
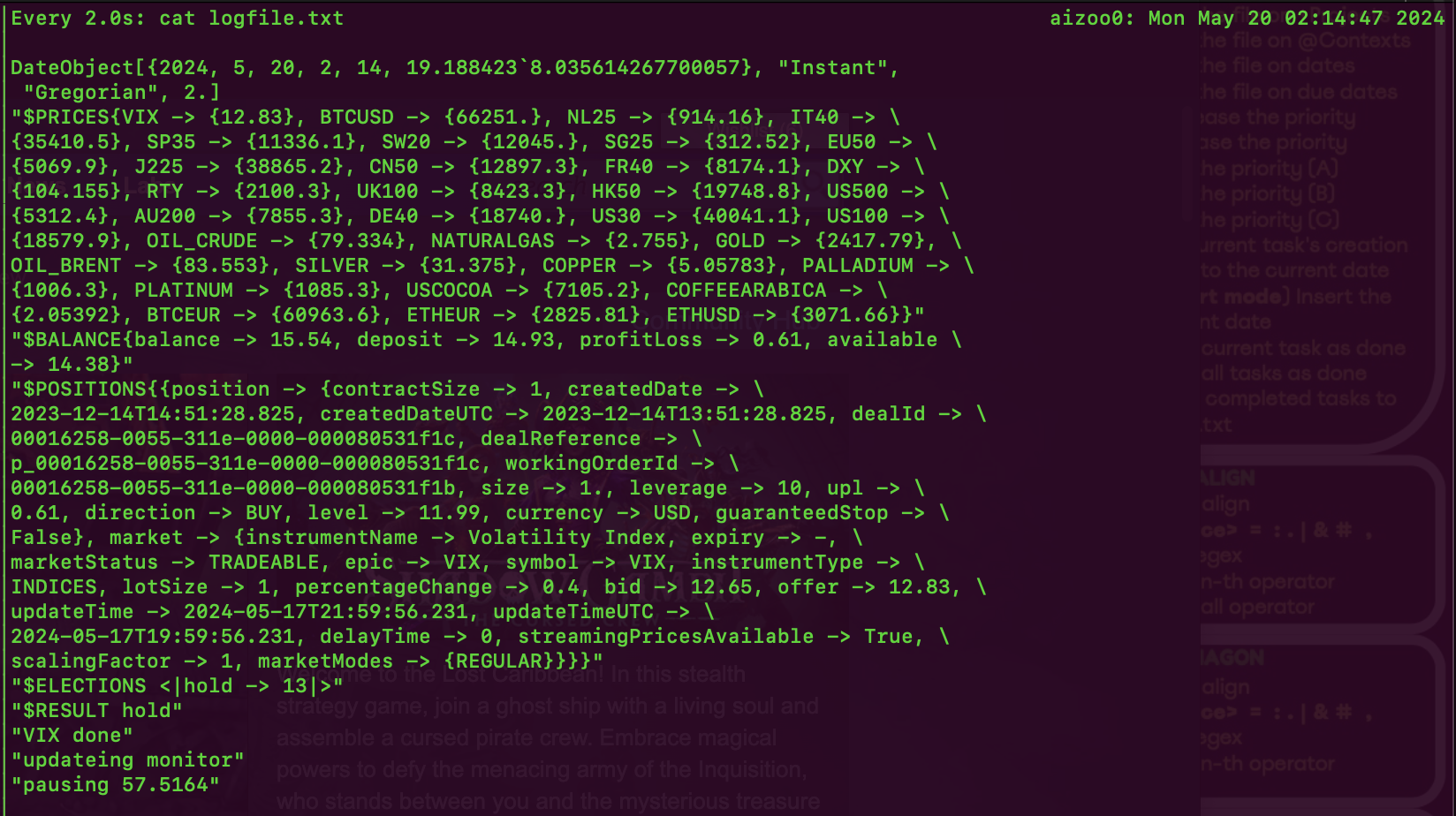

Implementation
The central point of our efforts is to find models whose common result of their efforts is to trade the designated symbol as effectively as possible. This patch includes the initialization of parallel compute nodes. The following distribution of training data for each kernel. Assuming that there was already successful learning in the past, it will try to load these models from the database and repopulate the population. If it is an initial learning, the required number of models are randomly created. The required state variables such as number of trading days and initial funds are set. As the last thing before starting learning, the required value of the quality measure is calculated.
Learning itself consists of several phases. In the element, the population of models is divided between individual kernels. Next, each kernel proceeds as follows. Create a neuron network (wolfram Mathematica object) from the model. Create environment by opening clerk device object. Next, it divides the learning data into a set of training and a set of validation data of the required length.
Due to the significant amount of data when trying to train a large number of models over a large number of days and a small time scale, it was necessary to divide the training itself into 2 phases (elementary training, advanced training). After the end of the first phase of learning, the results of validation during learning are evaluated and if they meet the criteria, they advance to the second phase of learning where they are exposed to data up to a 1-minute scale. Subsequently, it will be evaluated whether the validation fulfills the conditions for proceeding to the selection process for the population.
The selection is simple, no more than 10% of the entire population is selected from the given selection of the population. The selection is saved in the cloud. Then it creates all possible pairings (much like Beverly Hills). These pairs will each produce an offspring. In order to achieve sufficient repopulation, these descendants self-replicate with the required number of new random mutations and the necessary number.
A new bar is set for learning progress and the process returns to the beginning with a new population in an endless cycle.
Training pipeline
the basis of the whole project is the training pipeline. It includes a comprehensive procedure as in the environment of parallel kernels, it teaches a large population of evectively generated models. Intuitively, it can be divided into the following parts.
- initialization
- dependencies fetching
- training data loading
- parallel training process
- validation and evolution
Under initialization, we can imagine the revival of parallel kernels across networked devices. As much as it was a challenge for me personally to involve wolfram cloud as much as possible in the solution. Therefore, I decided to export the developed libraries (.wls scripts) to the cloud. The training script downloads these scripts from the cloud and distributes them among parallel kernels. After initial attempts, we were shown to use price development data directly downloaded from the broker using the API programmed by us. These data are individually stored on disk in the form of wolfram mathematica TimeSeries objects and exported as 'symbol.m'. These data are individually loaded by each kernel into the operating memory.
Each slightly more complex program requires some state variables, where it is possible to determine starting points for learning, such as the length of the required learning interval, initial capital, total population size, etc. Then, as the last step before starting learning by itself, there is an attempt to load the existing models, and then they repopulate the population of the required length, if successful learning has already taken place in the past, if it is initial learning, a pop-population of random progenitors is generated. For operational reasons, this population is copied to a backup variable, in case stagnation occurs after learning and to save time for pairing (which can be time-consuming in specific cases), this archived population is used. The time has come for the learning process itself.
To the extent that this is an evolution that should not be limited by time in principle. The choice of infinite while seemed intuitively the most correct choice. Constructs like While[True,...] do not belong to the equipment of a good programmer. therefore, a more reasonable approach required controlling this cycle with some external variable that effectively functions as a control mechanism. A cloud object storing a simple string was sufficient for these purposes. Later it turned out that this mechanism can also be used for regularly updating training data, or implementing changes in libraries without the need to interrupt the learning process and make the required changes after following the currently running population. The next generation will take into account required changes in data or code. The last option is to end the process "decently".
Assuming that our control mechanism finds a call to run learning, the following machinery will start. The entire population is collected and distributed among all kernels that perform the following. A neural network model is created from the specified Graph object as well as the required Loss function. The environment is generated in the form of a DeviceObject with the required initialization parameters. Historical data is divided into a set of training and validation data. The first learning phase will start. After the first phase, the set of 'ValidationMeasurementsLists' for the given model is evaluated and if it meets the minimum requirements, it advances to the next learning phase, otherwise it is discarded. In the second phase, he shuffles the model through learning on smaller time scales in an attempt to teach it to 'perceive' subtle changes in price and on small intervals but on a longer time scale. If the average of the set of validation cycles meets the minimum requirements, as at the end of the first phase, the model is retained and is advanced to the elimination process.
In this process, 10% of the best models from the generation of the previous selection are selected and analyzed to see if there has been stagnation compared to the previous generation. If stagnation has occurred, the possible number of mutations will increase and the stored population from the beginning of the learning process will change with the new required number of mutations. In the case of progress, i.e. in the new selection, the models are more successful than in the previous generation, these models will mate with each other (like Beverly Hills 90210) and create a new generation of proto-siblings. Next, the proto-siblings are copied each with a different chance of mutation to an amount exceeding the required size of the new generation. From this set, a new generation and the required number of individuals are randomly selected.
At the end of each generation, a little maintenance is done. Updating the cloud application in the form of a form with the latest models (in the bonus section we will discuss a bug that I managed to discover in WolframEngine while solving this problem).
Notifying the testing panel in advance to update the model database and continue testing. The new minimum requirement for the next generation will be recalculated based on the results of this one. In the last step, the current command of the control mechanism is downloaded from the cloud and the cycle continues.
- accumulates historic data for selected symbols
- data are stored in files, updated on a periodic basis [weekly](i.e. cron job)
- sources: capital.com [minute-intervals, offer, spread, swap ]
- initialization of pipeline
2.1 local and remote kernel configuration
2.2 launching kernels
2.3 loading packages and configuration from cloud
2.4 fetching data
2.5 variables initialization
- creation and training of agents
3.1 population initialization
3.1.1 initial population generated as simple progenitors of size N
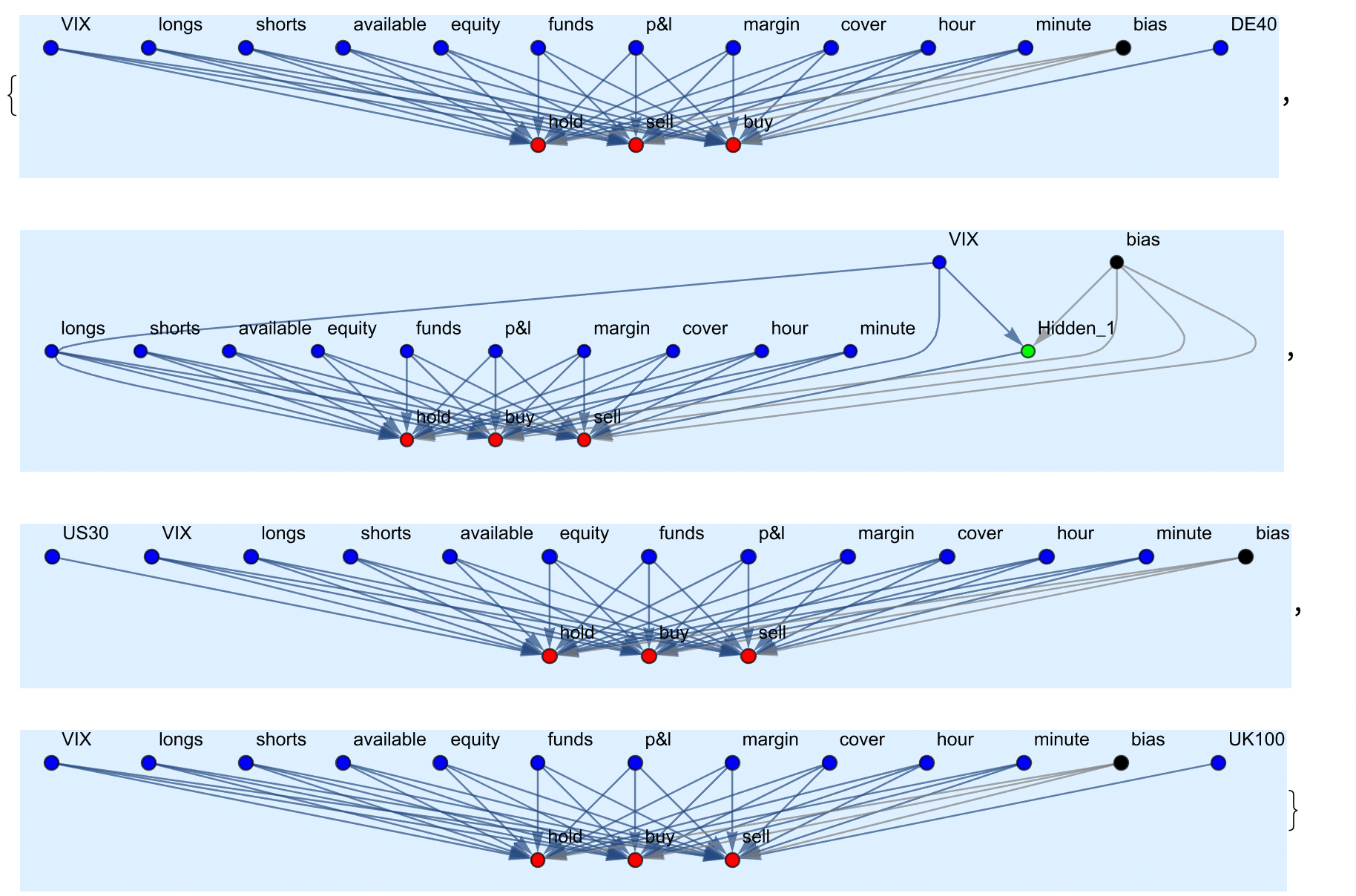 3.1.2 loaded previously trained models populating new generation from loaded models
3.1.2 loaded previously trained models populating new generation from loaded models
3.2 training
3.2.1 initialization of environment
3.2.2 initialization of policy net
3.2.3 data samplings (validation, training)
Full data: Timeseries from (circa since 2019) to Today with resolution of 1min
Samples: given sample length T, take consecutive samples of length T, starting from offset. Half of the samples, at random are to be used in training - the rest is kept for validation
3.2.4 Training - initial stage (240 minute scale)
3.2.5 Training - higher resolution
3.2.6 second stage trained model which surpassed minimal backward validation requirement continues for generation selection
3.2.7 select 10% of the best by performance measurement
3.2.8 stagnation verification (if performance of population stagnate incremental counter of possible mutations over generation
3.2.9 saving selection to cloud
3.2.10 crossbreeding
3.2.11 reevaluation of minimal requirement
3.3 training sample
3.3.1 penalties
3.3.2 treats
3.3.3 reward measurement
3.3.4 training & validation data randomization
4. running an agent 4.1 infrastructure initializations (broker API connection)
4.2 portfolio state data fetch
4.3 environment data fetch
4.4 models voting over data
4.5 action performance
4.6 validation data aggregation preservation and presentation
5. Instance of a council * A set of trained agents (NNs) together with decision rule forms a council
forward testing pipeline
in the event that the average of the selection validation is greater than the initial resources, the given selection is saved in the cloud and informs the relevant script performing preliminary testing to update the tested population. In the next part, we will see how this process takes place. The tested population is exposed in real time to live data from the broker through the API, namely monitored model symbols and monitored status of portfolio variables. Next, each member of the population expresses their opinion and the final decision is determined in the form of an election. The decision is made on the broker's side through the API by realizing the purchase of a long or short position on a demo account reserved for testing.
- initialization
- loading of models
- fetching live broker data
- model execution and voting
- execution result on broker side
upkeep pipeline
as the market and prices are constantly evolving, it was essential to ensure the continuity of learning models on current data. We have developed a script whose sole purpose is to update the historical data of the monitored symbols at regular (weekly) intervals, to distribute them over the network to all machines participating in parallel learning. Finally, notify the training script to update the training data before training the next generation.
initialization
fetching old data
- via API fetching new data from broker
- updating data and upload to cloud
- notifying training script to fetch new data
NEAT
In the last part, we will review the way in which the models are represented and organized . The method of pairing selected models and subsequent variations in subsequent generations using mutations
- creation
the models have two identical representations . To simplify the work of the neural network, it is represented as a Graph . For simplicity, vertices are colored, inputs are blue, outputs are red, and hidden neurons are green . The weights of the edges of the graph represent the weight of individual synapses in the neural network
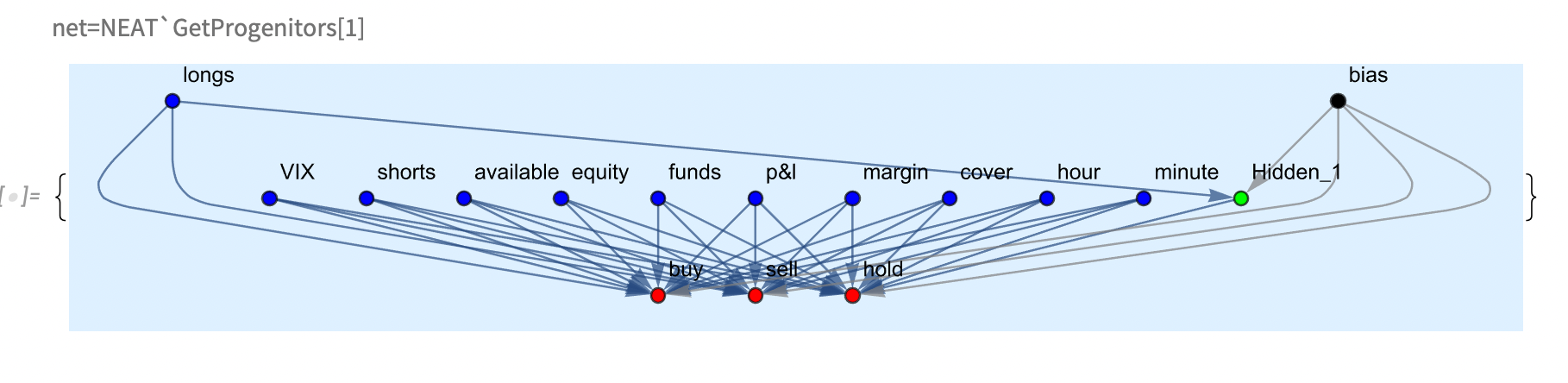
- initialization initialization consists in loading the Graph object of the selected model, its subsequent analysis and translation into a NetGparph object suitable for learning
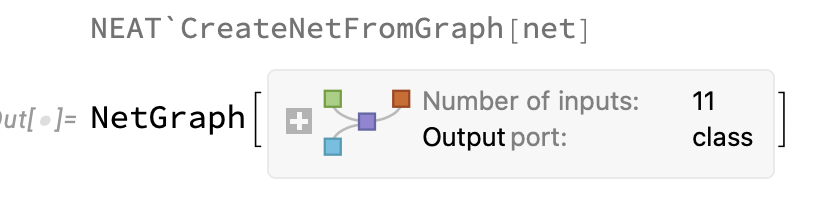
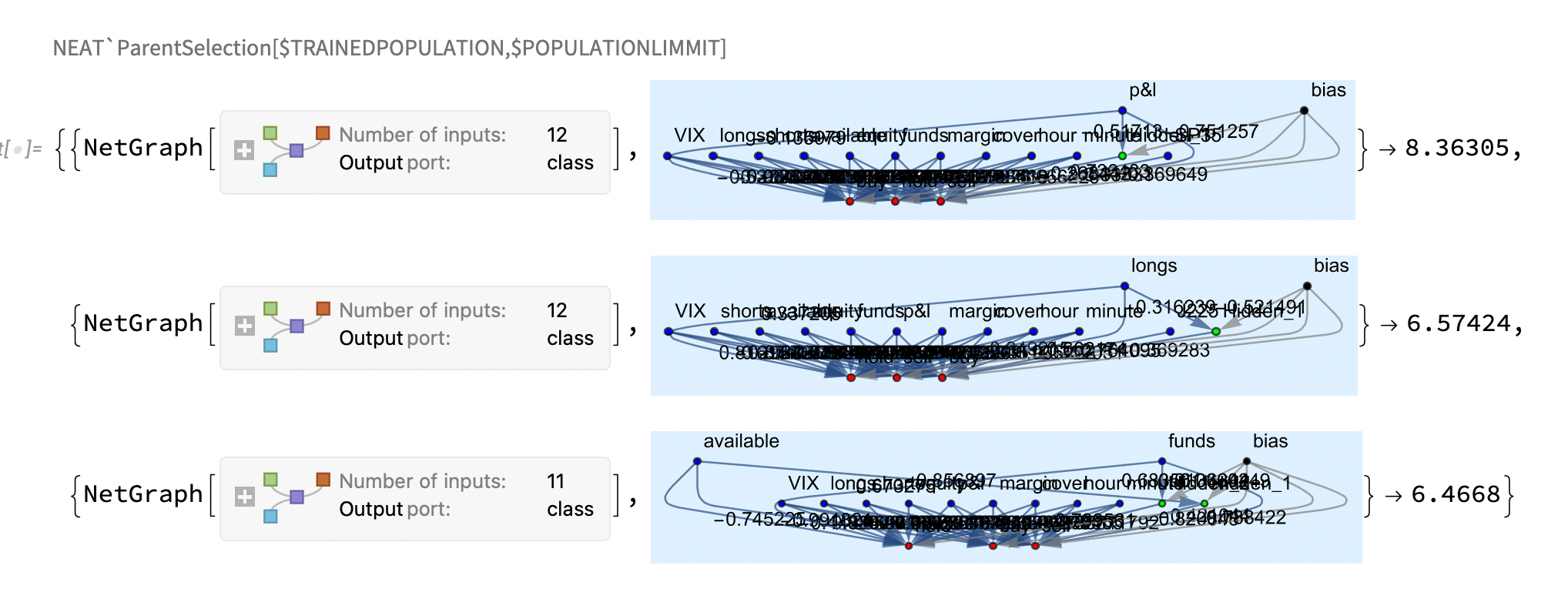
- selection after the end of the learning epoch, the models are ranked based on the success in the validation tests . We will select the top 10 % of the most successful models from the order of selection
- breading
Pairing of selected models as a process takes place in several logical phases . The first step is to create all possible pairs from selected models . These pairs produce a background number of offspring . The offspring of individual pairs (siblings) are distinguished by various random mutations guaranteeing the difference of siblings . We will randomly select a new population of the required size from the set of all descendants .
4.1 mutation
4.1.1 mutation first type
mutation of first type choose randomly between 2 vertices (one can be non existing input) then and new synapse
 4.1.2 mutation second type
4.1.2 mutation second type
mutation of second type choose random edge and intersect it with new hidden vertex (neuron) 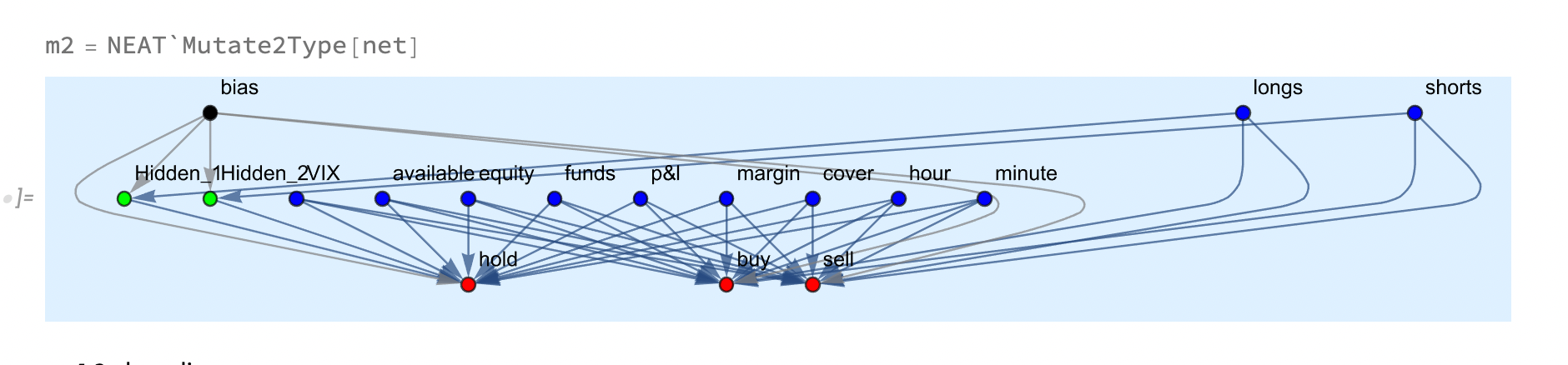 4.2 breading
4.2 breading
combine two graphs in to resulting offspring by coping edges, preferring dominant specimen if mutual edge is detected
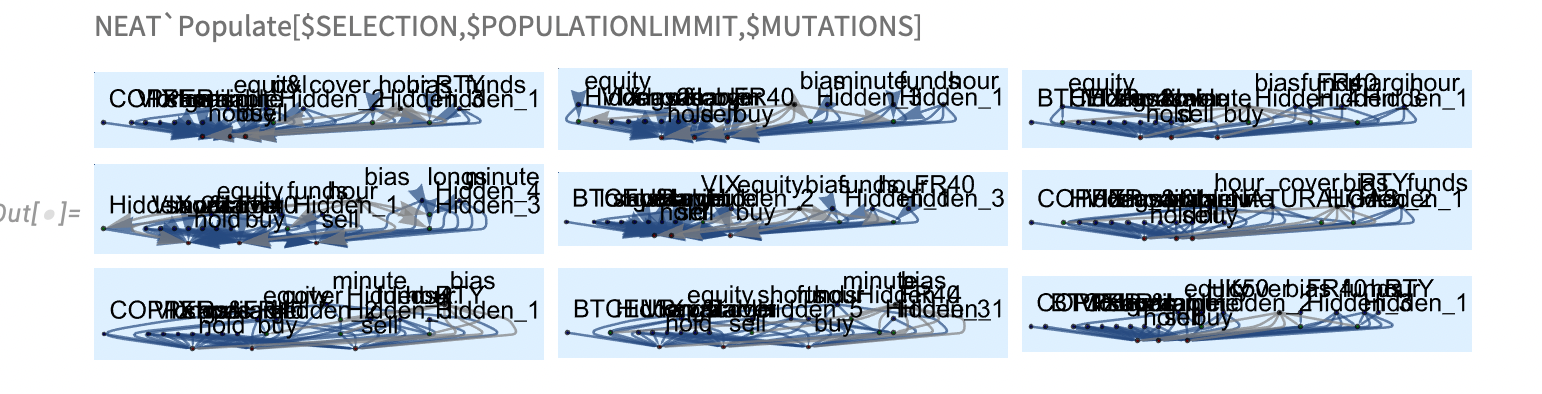
 4.3 populating
4.3 populating
selected pairs bread new generation of graphs.
- creating reinforce loss
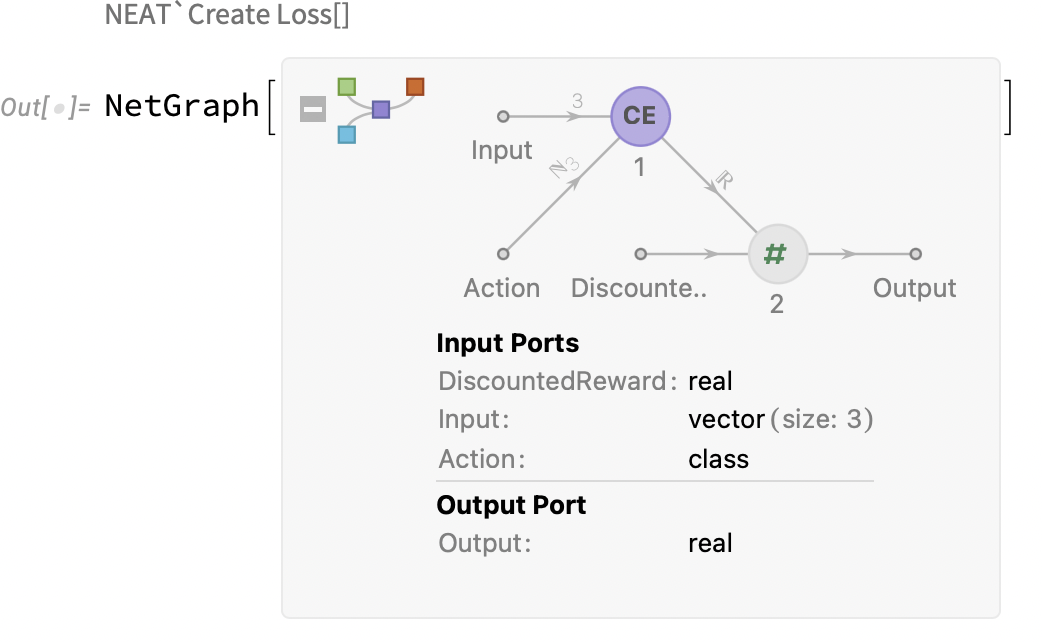 selected pairs bread new generation of graphs.
selected pairs bread new generation of graphs.
- defect detection and correction
- save and load
7.1 saving
save trained models in to the cloud object
7.2 loading
load trained models from cloud
environment
in the last period, the term "gamification of stock markets" is often mentioned in the media and professional community. As much as I myself grew up in a generation where computer games were an integral part of childhood. The perception of the stock market as a game engine where the player tries to maximize his profit was therefore not a problem for me. We therefore chose the method where the agent was trained in a reinforcement learning environment. (we drew inspiration for the implementation from reinforce learning ). However, our environment was not a pendulum simulator, but a simple device driver implemented by us called "clerk", whose task is to store and evaluate the statuses of the variable simulated portfolio (p&l margin funds, etc.) lists of executed trades (longs, shorts). On request, simulate the required training sample with the specified model over the required time with specified initial funds, it also controls the system of giving out rewards and punishments. For other needs, the implementation can also simulate a back test on historical data for the selection of one or more models and evaluate this collective decision.
1.initialization
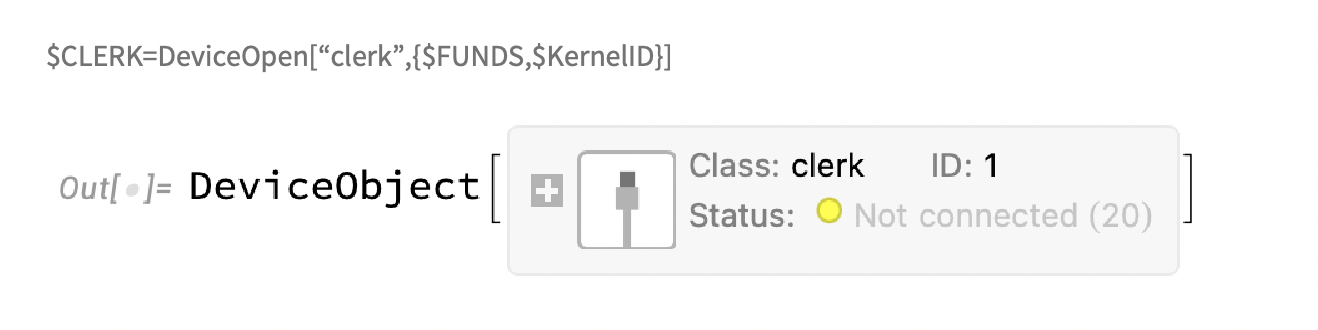
 2.execute testing sample
2.execute testing sample
 3.portfolio management
3.portfolio management
4.rewards and penalties
4.1 rewards
4.1.1 at the end of the business day swaps are calculated for longs and shorts, then accounted to overall funds
4.1.2 allocated profit or loss in opposite longs and shorts is calculated and added to rewards
4.2 penalties
4.2.1 initialization of environment
4.2.2 initialization of policy net
4.2.3 data samplings (validation, training)
4.2.4 data samplings (validation, training)
5. discounted rewards
utilities
just like every project, our project also required a small amount of commonly used utilities. We can divide them into two basic groups. The first one that takes part in the learning process and the second one that takes part in the maintenance.
In the first category, we find functions that ensure the preparation and distribution of data for learning and validation needs, calculate the length of training samples for the needs of the learning process, set the length of learning for individual time scales (training rounds) and, last but not least, the function of generating the training samples themselves using "clerk" device for learning or backward testing.
In the second part we find functions ensuring the running of elementary activities such as parallel loading of training data into all kernels. Updating cloud application database after successful training of the new generation.
1.fetching data
 2.policy net training
2.policy net training
3.validation and verification data split
 4.testing data
4.testing data 
Conclusion
the implementation of this solution, even if it was time-consuming, led to many interesting solutions, which without a doubt enriched the person professionally. We had the opportunity to try out a wonderful tool in the form of WM and implement the entire solution internally, starting with the theory of graphs, neural networks, and ending with a web API, web interface, etc... If there is someone who is interested in this issue, we would like to start a productive cooperation.
enquiries@aizoo.tech


