Ollama setup (post-it note instructions)
Set a Windows User Environment Variable OLLAMA_ORIGINS with a value of * (Start -> Settings -> System -> About -> Advanced System Settings (on the right) -> Advanced (tab) -> Environment Variables -> Add a new one on top)
Here's your HTTP request. The "ExportString" is the magic:
ollamaHttpRequest[model_, contextSize_, context_, seed_, streaming_,
prompt_] := HTTPRequest["http://127.0.0.1:11434/api/generate",
<|"Method" -> "POST",
"Headers" ->
<|"Content-Type" -> "application/json"|>,
"Body" -> ExportString[
<|"model" -> model,
"prompt" -> prompt,
"context" -> context,
"stream" -> streaming,
"options" ->
<|"seed" -> seed,
"num_ctx" -> contextSize|>|>,
"JSON"]|>];
Do a URLRead on that to send it to Ollama and you get an object from Ollama you can parse (should give you a '200' status server code).
Here's how you parse a non-streaming response:
ollamaReadSingle[ollamaHttpResponse_] :=
Association[ImportString[ollamaHttpResponse["Body"], "JSON"]];
And here's how you parse a streaming one:
ollamaReadStreaming[ollamaHttpResponse_] :=
Association[#] &@ImportString[#, "JSON"] & /@
StringSplit[ollamaHttpResponse["Body"], "\n"];
Confirming this doesn't to async responses yet (so you will wait even if you put in "streaming" unless you figure that part out). Didn't see this anywhere else. As much fun as it is being the only person in the world with a barely-working prototype...
Streaming Chat Setup
I am under the impression there is more interest in using Ollama with Mathematica. I've got quite a few features working, and would like to share. The idea with this is if you're a grad student or armchair researcher, you can get up and running with Ollama and start experimenting today.
If you're not using Ollama, it is available at ollama.com. It is a free and runs AIs locally on your computer (with extensive use of your graphics card to generate responses).
Attached is a notebook with an extensible framework that I hope will permit further experimentation with GPTs. Some features are included already. It's tested, but not extensively. Instructions are for Windows, however there are parallel functions and features for Mac and Linux (and these instructions are also much more extensively covered online).
All this model does is stream chat requests - it does not pull additional models, list what models you have, or run any other commands besides sending a streaming chat request (though it should be relatively easy to extend these features).
Crash Course
If you're already using Ollama, the crash course is to run the commands to load the model names, variables, and functions in the "Run Once" section, then scroll down to the bottom and enjoy. You may need to add an "OLLAMA_ORIGINS" environment variable (detailed below).
If this is your first time using Ollama, you will want to use Powershell to download at least one model file (this contains all the weights [the "brains"] of the AI). You should also attempt to start a Powershell chat session with the model to make sure it is returning responses, and there is no issue with Ollama failing to run.
If you are having issues running Ollama commands from Powershell, see if you can navigate to the installation folder, typically %AppData%\Local\Programs\Ollama, and attempt to run the commands there. If commands work from the Ollama installation folder, then the Ollama path is likely missing from your "Path" environment variable.
Ollama Environment Variables
Unless you do application configuration for a living, this is probably your first time hearing about environment variables. There are a few that you'll want to set / unset / know what they do.
To get into these (on Windows 10), go to Start -> Settings -> System -> About, and click "Advanced system settings" on the right. On the "System Properties" window, go to the "Advanced" tab and click "Environment Variables". You should get the following window:
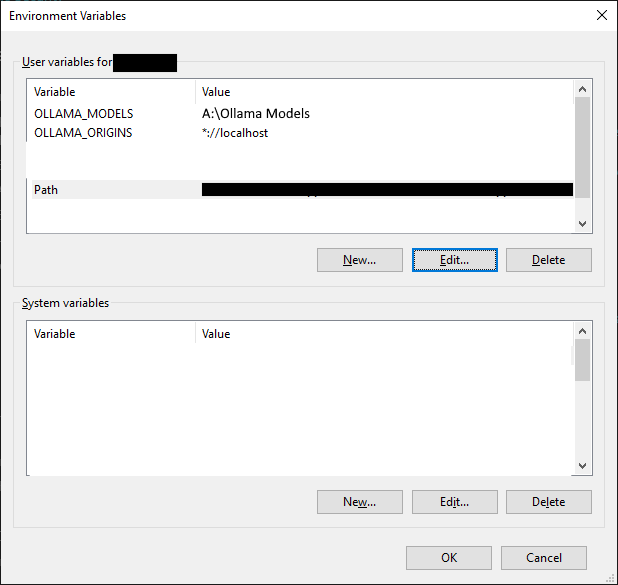
(I removed my system irrelevant variables for obvious security reasons, but you should have a lot.)
You may click "New" to add further variables. You will need to add "OLLAMA_ORIGINS" and set the value to "*://localhost" as in the example so that Ollama is allowed to receive connections from your own computer.
If you click on "Path" and click "Edit", you may have the path to the Ollama install directory in here. This allows Powershell, the Run dialog, and other things to run Ollama without needing to reference the entire folder path in the command line.
"OLLAMA_MODELS" will let you specify a different directory to download models into.
Lastly, please confirm that Mathematica is allowed to access the Internet (on version 12, this option is under Edit -> Preferences -> Internet & Mail).
Building Ollama HTTP Requests
Most of the HTTP request is built using Mathematica association datatypes - this is mostly just a list where values are assigned to a named "key" as well as maintaining an array position, and can be called by the name of the key.
Same as I've mentioned in an earlier post, the secret to getting the HTTP requests to work is to export just the body of the HTTP request association to JSON:
ollamaHttpRequest[bodyAssociation_] :=
HTTPRequest["http://127.0.0.1:11434/api/generate",
<|"Method" -> "POST",
"Headers" -> <|"Content-Type" -> "application/json"|>,
"Body" -> ExportString[bodyAssociation, "JSON"]|>];
This portion works for streaming responses as well as single-body responses.
The notebook attached builds the request in phases using a temporary association variable, beginning with a basic request saved to a temporary variable, and appending further body tags to that temporary variable before returning it as the result of the function:
ollamaHttpRequestBody[ollamaOptions_] :=
(
ollamaTempHttpRequestBody =
<|"model" -> ollamaInputModelString,
"prompt" -> ollamaInputFuncUserPromptString,
"stream" -> True,
"keep_alive" -> ollamaInputKeepAliveString,
"options" -> ollamaOptions|>;
(* Context - Included if not empty *)
If[ollamaUseContext && (ollamaVarCurrentConversationList != {}),
ollamaTempHttpRequestBody =
Append[ollamaTempHttpRequestBody,
"context" -> ollamaInputFuncSelectedContext]];
(* Template *)
If[ollamaUseTemplate,
ollamaTempHttpRequestBody =
Append[ollamaTempHttpRequestBody,
"template" -> ollamaInputTemplateString]];
(* System Prompt *)
If[ollamaUseSystem,
ollamaTempHttpRequestBody =
Append[ollamaTempHttpRequestBody,
"system" -> ollamaInputSystemPromptString]];
(* Image - Included if this model is a vision model *)
If[ollamaUseImage &&
ollamaFuncIsBoolVision[ollamaInputModelString],
ollamaTempHttpRequestBody =
Append[ollamaTempHttpRequestBody,
"images" -> ollamaInputFuncImageList]];
(* Include further body tags in here *)
(* This returns just the temporary HTTP request body association \
variable as the result of the function *)
ollamaTempHttpRequestBody
);
The "Options" portion of the request is built much the same way, as are the image and prompt parsing functions. This is done to allow easy extensibility - simply include an additional Boolean flag and pass the prompt or image to a manipulation function.
Saving Information
The notebook will save the contents of each query, and can be further extended to save further information by passing variables to Current Query Association variable (such as image sizes and CRC32 file hashes), as demonstrated below in the image builder.
This function will take an input of a list of paths of images, and first import the files so the files can have information saved (such as the size and hash), and then are converted into raw images so they can be manipulated, resized and the like, and then re-exported into JPG format for use as input into Ollama:
ollamaInputFuncImageList := (
(* Appends the image paths to the query *)
ollamaVarCurrentQueryAssociation =
Append[ollamaVarCurrentQueryAssociation,
"imagePaths" -> ollamaVarImagePathsString];
(* Splits the single string list of files up at the semicolons \
into a list of file paths *)
ollamaTempFilePathsList =
ollamaFuncGetImagePathsStringList[ollamaVarImagePathsString];
(* Entire image files are imported as binary objects *)
ollamaTempImageFileList =
ByteArray /@ (Import[#, "Byte"] & /@ ollamaTempFilePathsList);
(* Appends the size of the images to the current query association \
*)
ollamaVarCurrentQueryAssociation =
Append[ollamaVarCurrentQueryAssociation,
"imageFileSizes" -> (Length[#] & /@ ollamaTempImageFileList)];
(* Also appends a list of file hashes *)
ollamaVarCurrentQueryAssociation =
Append[ollamaVarCurrentQueryAssociation,
"imageHashesCRC32" -> (ollamaFuncImageFileHashString[#,
"CRC32"] & /@ ollamaTempImageFileList)];
(* The binary object image files are imported again in the image \
format, so it is now editable by image functions *)
ollamaTempImagesList =
ImportByteArray[#] & /@ ollamaTempImageFileList;
(* This runs all the edits we want to apply to our images *)
ollamaTempImagesList =
ollamaFuncAlterImage[#] & /@ ollamaTempImagesList;
(* Returns the list of images for inclusion in the HTTP request *)
ToCharacterCode[ExportString[#, "JPG"]] & /@ ollamaTempImagesList);
Receiving Streaming Responses
On URL submission, the Ollama server will begin returning responses. HTTP requests can be manually submitted via the use of the URL Submit function (however this notebook will call the URL Submit function with a number of other helper functions):
ollamaVarResponseTask = URLSubmit[
ollamaHttpRequest[ollamaTempHttpRequestBody],
HandlerFunctions -> <|
"HeadersReceived" -> (ollamaFuncHandlerHeaders[#Headers] &),
"BodyChunkReceived" -> (ollamaFuncHandlerBodyChunks[#BodyChunk] \
&),
"ConnectionFailed" -> (Print[
"Connection Failed: Ollama is probably not running."] &),
"TaskFinished" -> (ollamaFuncHandlerTaskFinished &),
"TaskStatusChanged" -> (ollamaFuncHandlerTaskInterrupt[#Task, \
#TaskStatus] &)
|>,
HandlerFunctionsKeys -> {"BodyChunk", "Headers", "Task",
"TaskStatus"}];
When setting up the URL Submit, you will want to save the URLSubmit command to a variable to keep track of the "task". This task variable may be used later to interrupt the query by the use of the "TaskRemove" function.
For a streaming response, URL Submit will need to be provided with "handler functions", and "handler function keys".
Handler functions are called when certain HTTP events take place, such as a body chunk is received (usually containing a single token), when the response is finished, interrupted, when headers are received, etc.. Handler function keys are values passed with the event.
A simple example is the headers handler, which just saves the returned headers into the current query association under the "headers" key:
ollamaFuncHandlerHeaders[
headers_] := (ollamaVarCurrentQueryAssociation =
Append[ollamaVarCurrentQueryAssociation, "headers" -> headers];);
It is okay to receive responses just as a string without attempting to import them from JSON into an association, especially when debugging.
Issues & Future Work
There may be some issues with the body chunks received. Some may be sent back empty, and some may be sent back incomplete (with the completed portions sent in subsequent body chunk responses). The notebook attached will parse some of these issues, but it seems like some new models can introduce new issues.
There are further notes within the notebook detailing how to tell if it's running, how to handle crashes and the like. Mostly you'll want to check your graphics usage, specifically the "Cuda" usage, but there are other signs things are working or not.
Please feel free to extend & upload the attached notebook at will. I won't be adding features, but if there are errors or bugs I may fix them & reupload (it's a lot of code, I'm sure I've missed some things, but I feel like this is good enough to publish at present).
Setup and usage details


