Hi,
I am sorry that if this does not have a short piece of code, trying to explain what I want to achieve. But I will try to explain in words as straight forward as possible.
First of all, if you run the two files I have written, one with all the functions I have written (main_func.m) and one with all the data (data.m). The syntax goes like this
Import["data.m"];
Import["main_func.m"];
closepop[B1997,kB1997,"LNB"]
closepop[B1998,kB1998,"LNB"]
closepop[B1999,kB1999,"LNB"]
closepop[housemice,khousemice,"LNB"]
The first three inputs are required, with the first two from data.m, and third one is one of the following, "Bin","TwoBin","BetaBin","BBB","LNB","BinLNB" or "LogGamma". They are different models, I aim to fit to the data.
For most of the datasets, the model "Bin","TwoBin","BetaBin" runs fine. See res_Bin.pdf for example, this is really a simple model, the output looks fine for all datasets. It also runs "reasonably" fast, just under 20 mintues to finish the whole file.
The main problem is that for other models, it runs really really slow. I hope to make it more efficient, and faster if possible.
The bit that is slowing it down, which I think is the "plot". The points are obtained by calculating 20 points (from line 439 in main_func.pdf). That is, only 20 optimization is done, to plot the graph.
The function PIfun[] is used to calculate the plot, but it depends on the optimization, which is really really time consuming. The final plot (what's really plotted) just adds some constant to the graph, see line 521-539.
Another problem with the code is, 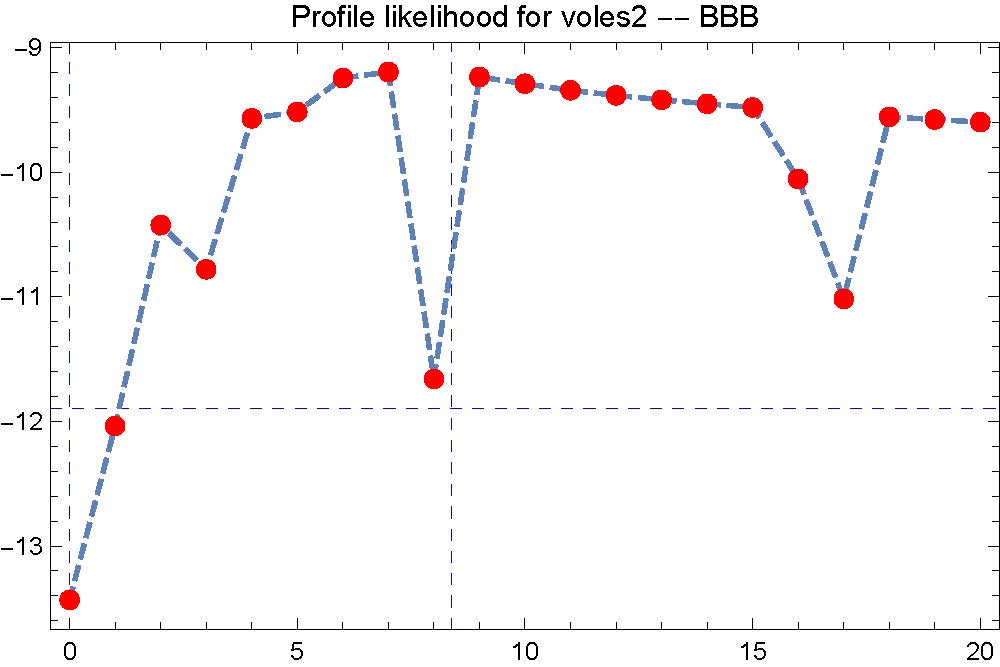
This was produced by
closepop[voles2,kvoles2,"BBB",0,20]
The last two values sets the range to plot the graph. I am expecting some kind of concave smooth curve, but because I used only 20ish points to plot the graph, it seems that the optimization was not very good at some of the points, even with 200 random points (which was set for NMaximize in the method of "RandomSearch").
I am really new to mathemtica. So if you have the time, please have a look, and help me improve my code to run faster.
Thanks!
 Attachments:
Attachments:


