The following wrapper will return a Dataset, but will otherwise behave like SQLSelect:
SQLSelectToDataset[args___, o : OptionsPattern[]] := Module[
{d},
SQLSelect[args, "ShowColumnHeadings" -> True, "ColumnSymbols" -> Function[{cols, res},
d = AssociationThread[cols, #] & /@ res
],
o
];
Dataset[d]
]
(The "ColumnSymbols" option lets you provide a callback to operate on the column names and resultset. You could accomplish the same thing less concisely munging the resultset and its column headings conventionally.)
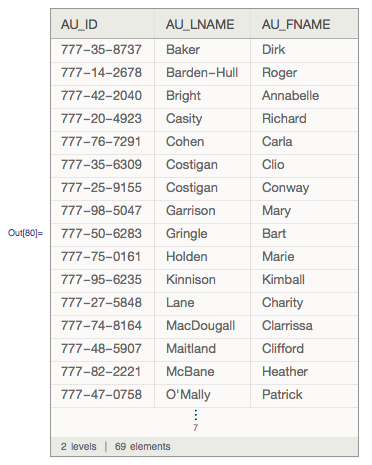
An example using one of the built-in example databases (documentation):
Needs["DatabaseLink`"];
conn = OpenSQLConnection["publisher"];
SQLSelectToDataset[conn, "AUTHORS", {"AU_ID", "AU_LNAME", "AU_FNAME"},
"SortingColumns" -> {
SQLColumn["AU_LNAME"] -> "Ascending",
SQLColumn["AU_FNAME"] -> "Ascending"
}]
CloseSQLConnection[conn];
Now to your point about efficiency. Key repetition is indeed built in to the current Dataset design, in part to support hierarchical data. We are aware of the need for more efficient representations of tabular data and are working on tighter Dataset-SQL integration. Note that it is possible to construct a keyless Dataset:
SQLSelectToDataset[args___, o : OptionsPattern[]] := Module[
{d},
SQLSelect[args, "ShowColumnHeadings" -> True, "ColumnSymbols" -> Function[{cols, res},
d = res
],
o
];
Dataset[d]
]
However in this case subsequent operations are limited to using [[part]] rather than #key syntax. HTH


