Hello,
I'm trying to build a text classifier using the build-in ML function Classify. I would like to know how to infer the classifier.
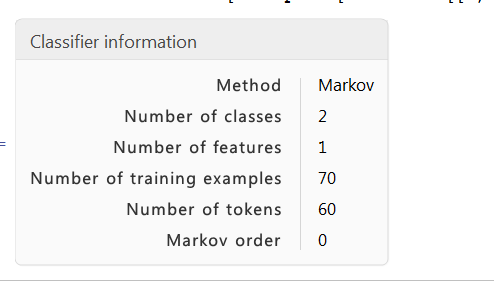
The ClassifierInformation function tells me that the classifier is using 0 order Markov model with 60 tokens.
ClassifierInformation[classifier]
However, I cannot see what are the word tokens used.
ClassifierInformation[classifier, "Tokens"]

I looked at the raw input format of the classifier:
classifier // InputForm
The set of tokens selected must be in this large association list. I think the tokens are probably hashed in this list:
<|"KeyHashes" -> {-8976609893939919452, -8894468231639786475, -8821926462245084318, -8593336127551271715, -8230815741027407785,
-8169792254897264918, -7757392622201104217, -7450228085403843758, -7147780780546570176, -6450296839742528765,
-6321595595375550476, -6222518939466451144, -6120399269222035989, -5585954272307346234, -5325103404253888535,
-5047623564691230835, -4981700751255594184, -4715233395353939948, -4509858987706864534, -4199542088805114162,
-4014743305594174262, -3913841058855507721, -3215676548730020875, -3136867552601502537, -3135880422665582565,
-2782771971927742608, -2553761260950900616, -2497465046883164335, -2357594401606083772, -2355706281896490993,
-1703360418925995958, -830435937522354266, -294253833800640815, -6406031197119517, 688536583746639659, 1266119473970088594,
1837117999705495410, 2001654405541659228, 2070912078197124738, 2173713581728700265, 2467134433834694074,
2817133499554344420, 3287432777910049379, 3665543855719664016, 3726697319209185988, 4425731798162304613,
4860099944076926020, 5133716165221699954, 5268648669712629995, 6391810193822596594, 6761163375797324647,
7240349841727313807, 7413631309042994934, 7482972113662169985, 7914209223226821202, 8139733960235943832,
8353135900516592165, 8548904748961355449, 8908130562059403171, 9132676784075023035}, "Values" -> None, "DefaultValue" -> -1,
"HashFunction" -> (Data`StringHash[#1, "Murmur3-64"] & ), "KeyHeads" -> {String}, "Version" -> {10.4, 1}|>
I don't know how to decipher it. Does anyone know how to get the tokens used in classification? Also, I would like to know based on what metrics the tokens are selected.
Thanks


