Where [John] comes from
I find the baby names data sets at Kaggle.com, and decided to use Wolfram Language to tackle some of the challenges like "Where [John] comes from".
For this purpose, I used the data set StateNames.csv (30.22 MB).
babyNamesState = Import["StateNames.csv", "CSV"];
Since SimanticImport may take a long time when first importing the data, I instead used the code from @Vitaliy Kaurov to replace state abbreviation with state entity for smaller chunk of data in the final data visualization step:
divisions = Entity["Country", "UnitedStates"][EntityProperty["Country", "AdministrativeDivisions", {}]];
rule = Rule @@@ AdministrativeDivisionData[divisions, {"StateAbbreviation", "Entity"}];
The first visualization I made is a manipulate to show all the historical data in a US map for a certain name, together with a bar chart to show the top states. Here is a gif version for "John" from 1959-2014:
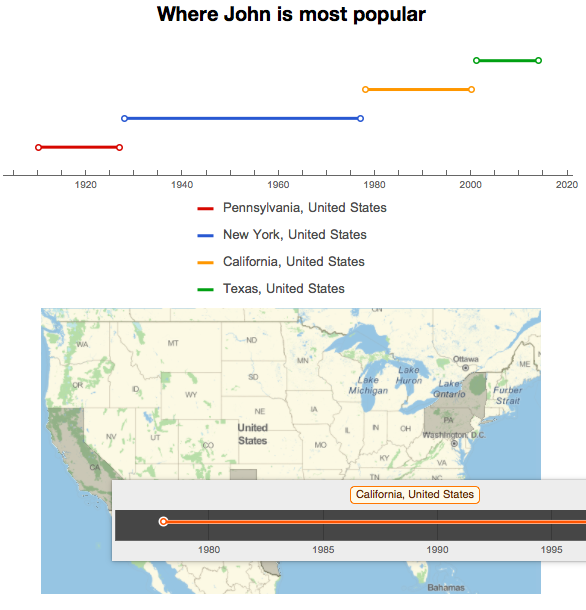
The second visualization shows in which state a name is most popular in a certain year. Here is a screenshot (It is kind of interesting to discover that within GeoGraphics[], it is able to create a tooltip version of TimelinePlot[]. So in the screenshot, when mousing over CA, it shows the timeline when John is most popular there) :
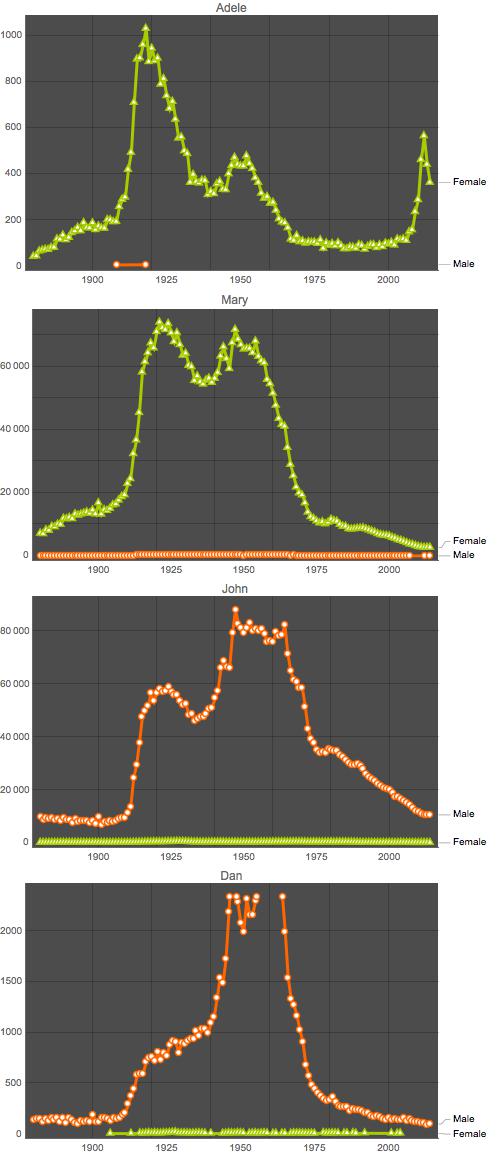
Once upon a time, [Adele] could be a boy
In the process of creating these graphics, I noticed that in rare cases, a masculine name like John is used to name a girl, and a feminine name like Adele could turns out to be a boy. I've long been interested in learning the gender property for a US name for some very personal reason. If you noticed, my own name Dan is very masculine in US. (well, it is actually not a US name but Pinyin for my original Chinese name. Unfortunately, both happened to use the same three letters in the same order. I've heard interesting comments regarding my name, and the best one is "What? You are Dan and your husband is She?" :) )
So I decided to find out all such extreme name cases by using the data set NationalNames.csv (11.54 MB). There are maybe better/more refined ways to do this, but I counted the total numbers of opposite genders for a specific name respectively, divide the smaller number with the larger one, and choose those that had a variance larger than 0 but smaller than 0.05. It takes a while to process all 93889 names, and get to the set of 3355 ones that meet the standard. (I think you can use the same code to find the most gender neutral names which will have a variance close to 50%)
And it is a pleasure for me to see some of the results:
Unsolved puzzle
With the built-in knowledge base in Wolfram Language, it should be possible to find out whether there is a correlation between names and historical events/movies/celebrities etc.. Alas, I failed to find a good way to accomplish this. If anyone has ideas/suggestions, please kindly share with me.


