UPDATE (06-20-18): Currently working on Neural Network Implementation for this project. I will update this post, or perhaps link to a new one, as soon as it is implemented.
My Project attempted to perform Speaker Diarization in Mathematica.
| Audio |
The audio was taken from episodes of podcasts. I split the samples manually using PreSonus Studio One, this can be done in any audio editing software such as audacity. I imported, trimmed and then conformed all the audio samples by removing the silence, normalizing, resampling and filtering them.
| Feature Extraction |
MFCCs with their first and second order derivatives were computed and sent to the built-in classifier. The Random Forest method was used.
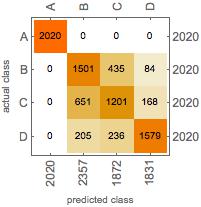
| Confusion Matrix Plot |