Introduction
Hi, I'm Rishu Mohanka, and I developed a Cryptographic Hash Code Algorithm based off of Cellular Automata. I initially came up for the idea while thinking about the complexity of CAs (Cellular Automata) and their applications in the real world, and I came across a relatively old article regarding how researchers at Google were able to crack the SHA-1 Hash Code Algorithm; hash code algorithms are very important regarding the security of our personal and sensitive information, so I decided to try to make my own Hash Code Algorithm that generated hash codes for inputs/messages from complex and chaotic CA. I thought this project would be pretty easy to complete, but it was harder than I expected, and completing the project successfully required a lot of experimentation. In the end, I wasn't able to fully achieve my vision of the potential for my algorithm within the 2 weeks I had at Wolfram Summer Camp 2017, but I will continue to work hard at perfecting, refining, and improving my algorithm because I truly believe that chaotic CA are the best means to generate hash codes.
What are Hash Code Algorithms?
First, let's go over what hash code algorithms are and why they are needed. Cryptographic hash functions are used to take in an arbitrarily long input/message, and it performs mathematical operations on the message to transform it into a hash code which is the output; the hash code must have a fixed length but it can be the same length or shorter than the input. These hash codes securely represents the input, and for good/valid hash code algorithms, it's easy to generate hash codes, but it's extremely hard to get the input from solely the hash code. Also, very good hash code algorithms must have extremely low probabilities of creating collisions meaning that if the hash code algorithm took in two distinct inputs, then if it generated the same hash code for the two distinct inputs, then that's a collision which creates the confusion and mix-up because you cannot have one hash code representing two distinct inputs. Also, a good/valid hash code algorithm must have the ability to generate the same hash code for the same input meaning that it is deterministic. Cryptographic Hash Code Algorithms are used for purposes like storing passwords securely, secure file/data transferring, etc. Good cryptographic hash code algorithms exhibit two main properties: Strong Collision Resistance and Weak Collision Resistance. Strong Collision Resistance means that it is computationally impractical for anyone to find any two distinct messages/inputs that when inputted into the cryptographic hash function, output the same hash code. Weak Collision Resistance means that for any large set of inputs, there exist no inputs in that set of inputs such that they will generate the same hash codes as another input in that set. If a hash code algorithm has the property of Strong Collision Resistance, then it also exhibits the property Weak Collision Resistance, but the converse is not true.
Development
The CA used in this project have ranges of either 2 or 3, and they all have two states (black or white so k = 2), and the CA used are those that are very chaotic and complex with no pattern available within the CA's structure in order to prevent the hash code algorithm from generating collisions for distinct messages/inputs/passwords. To choose the CA from r = 2, r = 3, k = 2, I generated at hundreds of thousands of CA for each range. There are 2^2^5 (around 4.3 billion) number of possible CA for r = 2, k = 2 and around 2^2^7 number of possible CA for r = 3, k = 2, so it was computationally impossible for me to go through each and every one of those CA without crashing my kernel repeatedly, so I had to pick and choose (in the future, if I have access to powerful computers, I'd want to modify my algorithm and test every one of those CA). Example for r = 2:
Select[Table[{n, Flatten@CellularAutomaton[{n, 2, 2}, RandomChoice[{1, 0}, 128], {{1000}}]}, {n, 1, 20000}], (60< Count[#[[2]], 0] < 75) &];
Example for r = 3:
Select[Table[{n, Flatten@CellularAutomaton[{n, 2, 3}, RandomChoice[{1, 0}, 128], {{1000}}]}, {n, 123308249090345280300093458548552398347, 123308249090345280300093458548552438347}], (60 < Count[#[[2]], 0] < 70) &]
I changed the parameters to go through more rules, so, in total for r = 2, k = 2, I went through the rules between 21000-65000, 65001 - 120000, 120001 - 200000, 200001 - 300001, 300002 - 600000, 600001 - 1000000, 1000001 - 1500000, 2000001 - 2500001, 90409230 - 90999240, 953402389 - 1094838934, 3008324031 - 3008563853, 2309409238 - 2309732198, 1094838929 - 1094939529. I only selected the rules that had between 55 and 75 0s (or between 60 and 70 0s for the larger rules) because I want approximately the same amount of 1s and 0s in the rules I use to make sure that I am using chaotic and random CA. For r = 3, k = 2, I looked at the rules from 90280300834552398346 - 90280300834552598349, 9090345280300834552398347 - 909034528030083454308552458347, 123909034528030083454308552398347 - 123909034528030083454308552410347, 12330824909034528030083454308552298347 - 12330824909034528030083454308552438347, 123308249090345280300093458548552398347 - 123308249090345280300093458548552438347, 58437598988924093823479989347 - 58437598988924093823479999347, 584378988924093823479989347 - 584378988924093823479999347, 9843095354984375023479989347 - 9843095354984375023479999999, 910843095354984375023479789347 - 910843095354984375023479989347.
f = BooleanFunction[# /. {0 -> False, 1 -> True}, {a, b, c, p, q, t, u}] &
I found the Boolean functions representing each rule for the CA in each range. Because I was going through so many rules, for many operations, I had to export the list of rules in text files that way I can just read those text files after my kernel crashes without having to evaluate the previous cells Then I ran Boolean Minimize on each Boolean Function for every rule.
evenBetterRules = Table[{n[[1]], BooleanMinimize[n[[2]]]}, {n, ReadList["bestRules.txt"]}]
I found the Leaf Counts for every Boolean Function after compressing each one.
leafCountRules = Table[{n[[1]], LeafCount[n[[2]]]}, {n, ReadList["evenBetterRules.txt"]}];
I created a Distribution (Histogram) of the aforementioned leaf counts, then I took the rules at the 90th percentile
graphOfDist = HistogramDistribution[ReadList["leafCountRules.txt"][[All, 2]]]
This is what the histogram looks like for r = 3
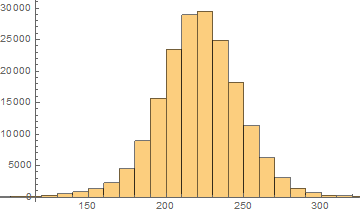 It looks approximately normally distributed which is interesting. I took the rules at the 99.95 percentile for r = 2,
It looks approximately normally distributed which is interesting. I took the rules at the 99.95 percentile for r = 2,
listOfRules = Select[ReadList["leafCountRules.txt"], Last[#] > Floor[Quantile[graphOfDist, 0.9995]] &]
and rules at the 95th percentile for r = 3.
setOfRules = Select[leafCountRules, Last[#] > Quantile[w, 0.95] &]
I then found the amount of information entropy in each CA (interestingly enough, I found that the max entropy of the rules for CA in r = 2, 3, k = 2 was 6.9085, no CA had more entropy than that) and found the rules whose information entropy exceeded 6.5. The following is the code for r = 3
theBestRules = Select[rules, N[Entropy[CellularAutomaton[{#, 2, 3}, RandomChoice[{1, 0}, 128], 1000]]] > 6.5 &]
Then, I converted each CA in my new small set of rules into JPEG images and using file conversion compression algorithms; the following is the code for r = 3, just replicate the same process with r = 2.
arrayPlotOfBestRulesr3k2 = Table[ArrayPlot[CellularAutomaton[{theBestRules[[n]], 2, 3}, RandomChoice[{1, 0}, 128], 1000]], {n, 1, Length[theBestRules]}];
picsOfBestRulesr3k2 = Table[Export[StringJoin[StringJoin["r3k2rule", ToString[n]], ".jpg"], arrayPlotOfBestRulesr3k2[[n]]], {n, 1, Length[theBestRules]}];
secondFinalSetOfRules = Table[{theBestRules[[n]], FileByteCount[picsOfBestRulesr3k2[[n]]]}, {n, 1, Length[theBestRules]}]
I created a Distribution (Histogram) of file byte sizes for each CA then I took the CA at the 95th percentile and found that all of those CA at the 95th percentile were very complex, chaotic and had no pattern, and this distribution also looked approximately normally distributed (for r = 2, I took the CA at the 85th percentile, these were also very complex CA, but the distribution of file byte sizes for r = 2 was not normally distributed).
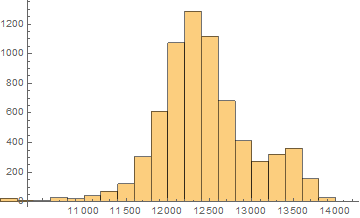
Distribution = HistogramDistribution[FileByteCount /@ picsOfBestRulesr3k2]
finalSetOfRulesr3k2 = Select[secondFinalSetOfRules, Last[#] > Quantile[Distribution, 0.95] &]
An example of one of the CA at the 95th percentile in terms of file byte size for r = 3, this is rule 123308249090345280300093458548552398368 up to 1000 evolutionary steps:
ArrayPlot[CellularAutomaton[{123308249090345280300093458548552398368, 2, 3}, RandomChoice[{1, 0}, 128], 1000]]

To generate hash codes for inputs based off of my new set of CA, I converted the user's input into their binary representation, then I took the first n bits (length specified by the user, and if their input's binary representation was shorter than the user's specified length, then my algorithm pads their input's binary representation with 0s) and used that as the initial condition for a random CA rule (range specified by user) while the kth row is generated by taking the base-10 representation of the user's input, squaring it, and doing that number mod a random prime number between 2^10 and 2^15 (similar to Rabin cryptosystem processes), then the first n bits of that row are used as the hash code. I created a block system similar to Merkle Damgård Construction, so I partition the user's input into x amount of blocks where x is a multiple of the length of the hash code as specified by the user, then I use the hash code for the first block as an input as the initial conditions for the CA in the second block, then I take the hash code of the input in the second block and I perform the XOR operation on the hash codes from the first block and the second block and use that as the input for the third block,etc. The hash code from the final block is used as the final hash code of the user's message/input/password. In my algorithm, I got the number 57203 (from the process similar to Rabin's cryptosystem as described earlier) as the nth row to get the hash code for each block, and I decided to use the rule 2309726947 as the CA for r = 2, k = 2 and rule 123308249090345280300093458548552398368 for r = 3, k = 2. The user, through my microsite, can enter their message along with the length of the hash code and the range of the CA, so for example, if they enter in their message to get a hash code with length 128 using r = 2, my algorithm will generate the hash code for their message using rule 2309726947 at the 57203th evolutionary step. The predetermined nth evolutionary step helps ensure that the user will get the same hash code for the same input rather than fully implementing the random function in the algorithm which will produce a different nth row for every input meaning a different hash code for the same inputs which is NOT what we want. Here is my code for the described process:
RoundFunctionr2k2[block_] := Flatten@CellularAutomaton[{2309726947, 2, 2}, block, {{PowerMod[FromDigits[block], 2, 57203]}}]
RoundFunctionr3k2[block_] := Flatten@CellularAutomaton[{123308249090345280300093458548552398368, 2, 3}, block, {{PowerMod[FromDigits[block], 2, 57203]}}]
CAHash[message_, len_, range_] := Block[{blocks = Partition[ImportString[ToString[message],"Bit"], len, len, 1, 0]},
If[range == 2, StringJoin[ToString/@Fold[RoundFunctionr2k2@BitXor[#1, #2] &,RoundFunctionr2k2[blocks[[1]]], blocks[[2;;]]]],
If[range == 3, StringJoin[ToString/@Fold[RoundFunctionr3k2@BitXor[#1, #2] &,RoundFunctionr3k2[blocks[[1]]], blocks[[2;;]]]]]]
]
After this, I wanted show that my hash code algorithm based off of cellular automata was really strong by showing that no two rows would be the same in two cases: by checking the CA if you had random initial conditions, but the same row, and by checking the CA if you had the same initial conditions(still random initial conditions) but different amount (random) of rows. You can use random initial conditions for the CA because it's supposed to represent the user's input and since there are so many possible inputs, it might as well just be random.
For the first case, r = 2, my code is shown here:
Block[{in = RandomChoice[{1, 0}, 128]},
Sort[Tally@(CellularAutomaton[{2309726947, 2, 2}, in,
PowerMod[FromDigits[in], 2, 57203]]), #1[[2]] > #2[[2]] &]]
and r = 3,
Block[{in = RandomChoice[{1, 0}, 128]},
Sort[Tally@(CellularAutomaton[{\
123308249090345280300093458548552398368, 2, 3}, in,
PowerMod[FromDigits[in], 2, 57203]]), #1[[2]] > #2[[2]] &]]
For the second case, r = 2,
Block[{in = RandomChoice[{1, 0}, 128]},
Sort[Tally@(CellularAutomaton[{2309726947, 2, 2}, in,
PowerMod[FromDigits[in], 2,
RandomPrime[{2^10, 2^20}]]]), #1[[2]] > #2[[2]] &]]
and r = 3,
Block[{in = RandomChoice[{1, 0}, 128]},
Sort[Tally@(CellularAutomaton[{\
123308249090345280300093458548552398368, 2, 3}, in,
PowerMod[FromDigits[in], 2,
RandomPrime[{2^10, 2^20}]]]), #1[[2]] > #2[[2]] &]]
And for both cases, each row only occurs once!
Here is the link to my microsite where you can test out my program: https://www.wolframcloud.com/objects/ccc4a4f1-b362-431d-8f71-5688908ecfa7
Reflections and Extensions
This project really gave me a taste of what software development was all about because almost everyday was full of intense work on my project including many rounds of just revisions and experimenting with Mathematica. My original vision for my project was not able to come into fruition because 2 weeks weren't enough to fully develop my project, but I will be hard at work refining and perfecting my novel algorithm. I personally think that my cryptographic hash code algorithm based off of Cellular Automata can be used to replace current cryptographic hash code algorithms implemented to secure passwords, securing file transfers, implemented in cryptocurrencies, etc., but I'm working hard to prove that it is better.
In the future, I want to find complex CA and test each rule from r = 1 to r = 5 (or even r = 10) on more powerful computers to compile a list of CA fit to use for my cryptographic hash code algorithm. I also want to explore further methods of making my system more safe and secure than current cryptographic hash code algorithms (like SHA-256, SHA-512, etc.) because I believe that chaotic cellular automata can serve very useful purposes in cryptography, and chaotic/disordered CAs will allow for more secure cryptographic systems in the future. Also, I want to learn more about cryptanalysis and methods of cryptanalysis, so that I can try to break my own system, and if I can't (or if anyone else can't), then I'll try to prove that my cryptographic system is more secure than current cryptographic hash code algorithms (and if my system is "breakable", then I'll try my best to improve my system). I'm going to learn about more secure cryptosystems implemented in other hash functions to see if I can use those in junction with CA to create better cryptographic hash code algorithms based on CA that are harder to brute force than current hash functions like SHA-256 or SHA-512.


