Hello fellow Mathematica enthusiasts! My name is Abinav Routhu and I am a member of the Wolfram Summer Camp 2017 Group. Part of my experience was undertaking a project related to Mathematics/Computer Science in an area of our passion. Like many of you all, I must proclaim I am utterly fascinated by machine learning which partly led me to my project. I chose to construct a text classifier which would determine the political orientation of a body of text. I envision that it would be used most with articles, blogs, and other pieces of explicitly political rhetoric.But none of this would have been possible without the help of my mentor, Christian Pasquel -- Thank you for your (much needed) help! ______ Data Collection
The first step of the process was producing meaningful and quality data to train with. What we're looking for is writing that is highly politically charged - writers and bloggers who are unashamedly proud and forthright with their views. Sources which attempted to be neutral, bipartisan, or generally divorced from the classical left-right political spectrum were avoided. 5 sites were chosen (2 conservative, 3 liberal); around 9,500 articles published during election cycle, the most active blogging period in the typical 4 year cycle, were parsed and analyzed
*Credit to Yano, Kohen, and Smith for Information Database: http://www.aclweb.org/anthology/N09-1054*
- Carpetbagger Report (cb)
- Daily Kos (cb)
- Matthew Yglesias (my)
- Red State (rs)
- Right Wing News
Each article was tagged with its own unique ID. The files were split at random into training and testing data sets in an 80:20 ratio described in .txt files in lists of filenames.
At this point, the files were processed and imported. Newline characters were stripped, forward slashes were replaced, path names were pre-pended.
cbtrstr =
Import["C:\\Users\\venkat\\Downloads\\ProjectData\\blog_data_v1_0\\\
cb\\hbc_data\\data\\body_train_file.txt"];
cbtestr =
Import["C:\\Users\\venkat\\Downloads\\ProjectData\\blog_data_v1_0\\\
cb\\hbc_data\\data\\body_train_file.txt"];
cbtrlist =
StringSplit[
StringReplace[StringDelete[cbtrstr, "\n" | "\r"], "/" -> "\\"],
"..\\.."];
cbtrlist =
ReplaceAll[
y_String :>
"C:\\Users\\venkat\\Downloads\\ProjectData\\blog_data_v1_0\\cb\\\
distilled\\data" <> y][cbtrlist];
cbtelist =
StringSplit[
StringReplace[StringDelete[cbtestr, "\n" | "\r"], "/" -> "\\"],
"..\\.."];
cbtelist =
ReplaceAll[
y_String :>
"C:\\Users\\venkat\\Downloads\\ProjectData\\blog_data_v1_0\\cb\\\
distilled\\data" <> y][cbtelist];
cbtr = Import[#] & /@ cbtrlist;
cbte = Import[#] & /@ cbtelist;`
Afterward, punctuation was stripped, uppercase was made lowercase, and as much external noise as possible was removed.
cbtr = StringReplace[#, {"_meta_end_dot_" -> ".", "_meta_number_ref_" -> "#" , "_meta_percent_ref_" -> "%",
"_meta_end_question_" -> "?", "meta_end_exclamation_" -> "!"}] & /@ cbtr;
With the data at hand, the next step was constructing and training the classifier; with Mathematica the problem becomes almost trivial.
n = 10;
smprwntr = RandomSample[rwntr, n];
smprstr = RandomSample[rstr, n];
smpmytr = RandomSample[mytr, n];
smpdktr = RandomSample[dktr, n];
smpcbtr = RandomSample[cbtr, n];
clFunction = Classify[<|"Left" -> Join[smpmytr, smpdktr, smpcbtr], "Right" -> Join[smprwntr, smprstr]|>];]
It presents itself as a double edged sword. On one hand, Mathematica's built in functionality for machine learning and classification make it extremely easy for beginners to implement and design with. Much of text preprocessing such as the padding, breaking, and tokenizing are done instantly. Yet, much of the networks processes and methods are hidden and nigh inaccessible. My research indicated that algorithms with high chance of success included Multinomial Naive Bayes, Support Vector Machine, and Latent Dirichlet Allocation. Yet, the Classify function automatically assigns and computes with little direction.
 (Full Training Data Set Loaded Pictured)
(Full Training Data Set Loaded Pictured)
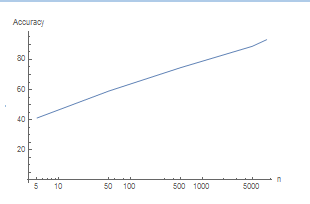
Next, the accuracy was measured. Varying n, the number of datum the classifier trained on while measuring accuracy is how the following graphic on a LogLinear Plot was made. The classifier makes roughly equal increases in accuracy every power of 10, reaching a peak of ~94%.
 ( The classifier functions best with medium-length text.)
( The classifier functions best with medium-length text.)
Try out the microsite here: https://www.wolframcloud.com/objects/user-9c0668a9-bd34-4028-bc47-a3315bead7b4/ProjectNameThing
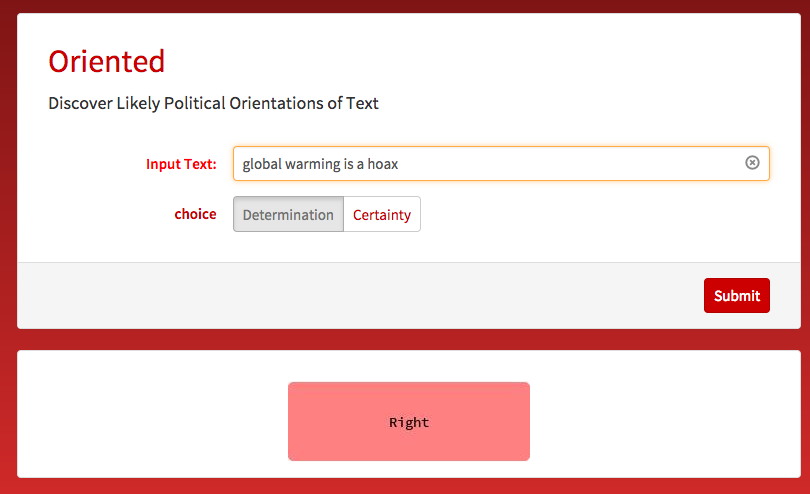
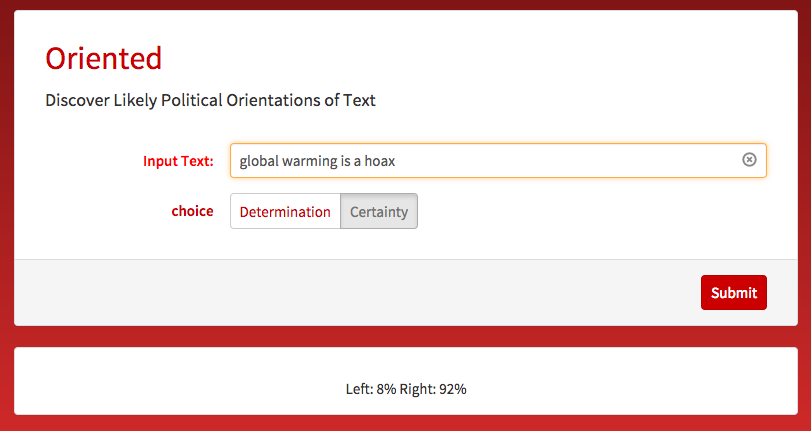
Here is an example:
Some other methods I had tried was using a embedding analysis through "Bag of Words" technique and sentiment analysis which is already built in to Mathematica; however, there were significant hurdles in making the word vectors. Another area which could be improved is the data itself which comes pretty exclusively from political blogs from 2008 to 2009. Other possible sources include reddit political posts, twitter comments, and political speech text. ______________ Before camp, I was relatively inexperienced with Mathematica and implementations of machine learning, but I have learned much over the course of two weeks. I'm glad I got to learn about an area of interest intensively for the past 12 days.


